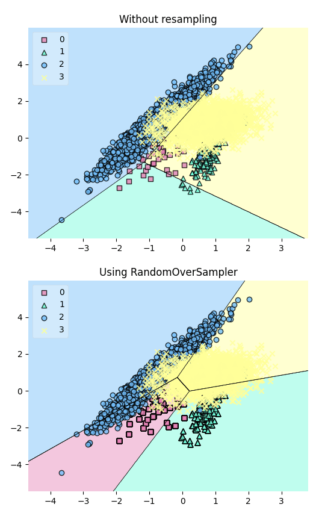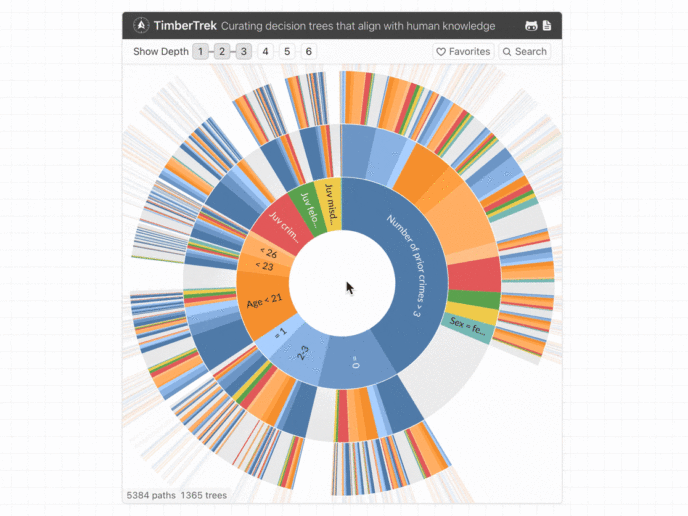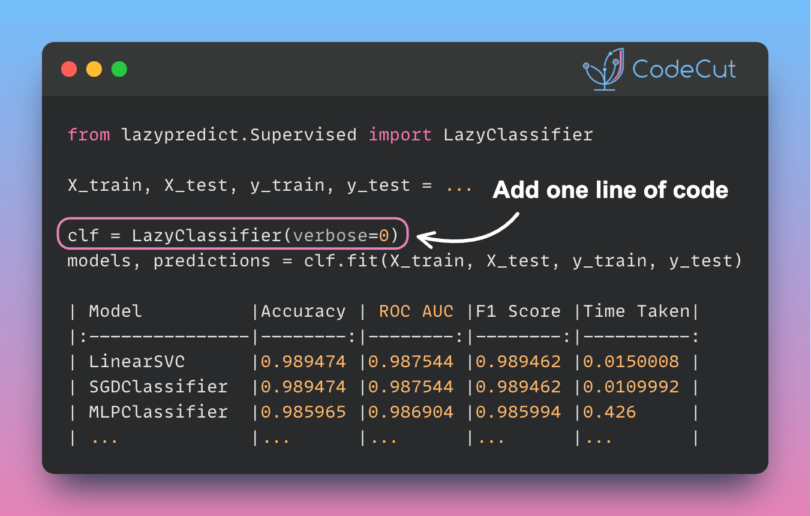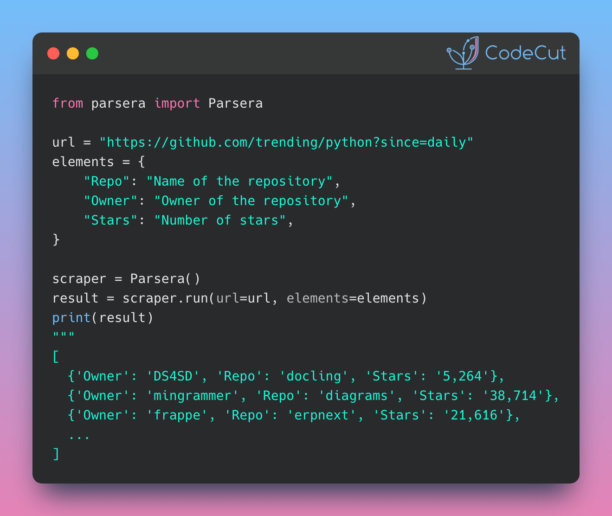
Interpreting decisions made by complex modern machine learning models can be challenging.
Interpreting decisions made by complex modern machine learning models can be challenging. imodels works like scikit-learn models and can replace black-box models (e.g. random forests) with simpler and interpretable alternatives (e.g. rule lists) without losing accuracy.
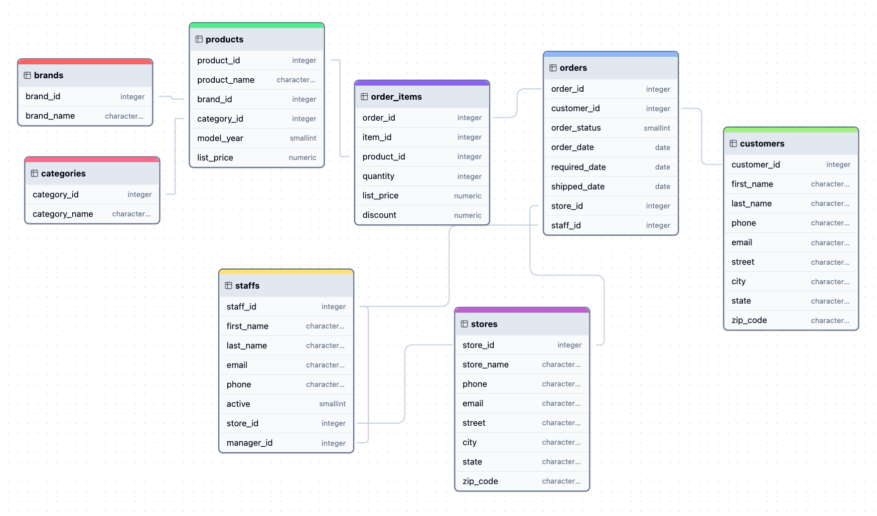
Here’s an example of fitting an interpretable decision tree to predict juvenile delinquency:
from sklearn.model_selection import train_test_split
from imodels import get_clean_dataset, HSTreeClassifierCV
# Prepare data
X, y, feature_names = get_clean_dataset('juvenile')
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# Initialize a tree model and specify only 4 leaf nodes
model = HSTreeClassifierCV(max_leaf_nodes=4)
model.fit(X_train, y_train, feature_names=feature_names)
# Make predictions
preds = model.predict(X_test)
# Print the model
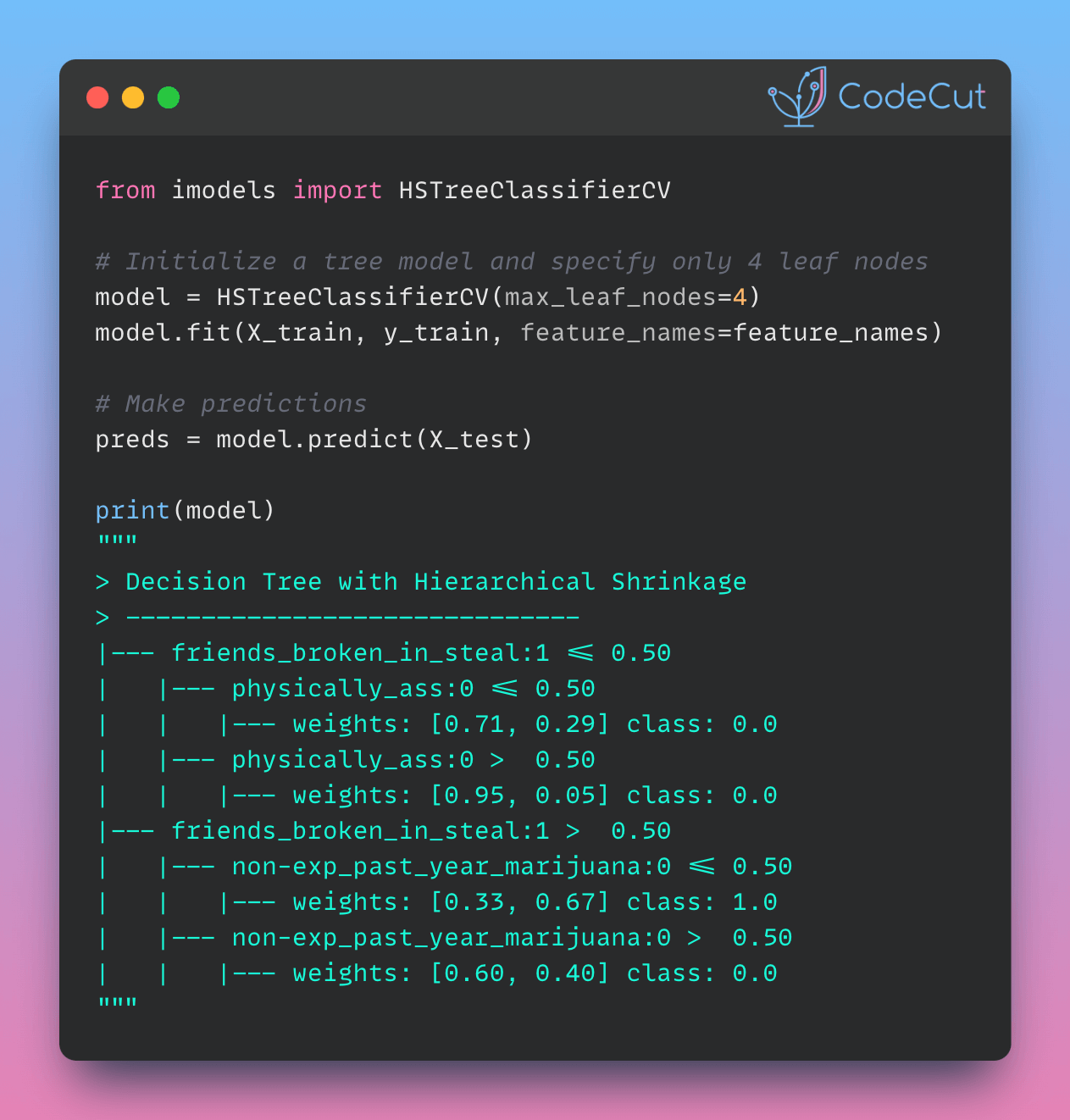
print(model)> ------------------------------
> Decision Tree with Hierarchical Shrinkage
> Prediction is made by looking at the value in the appropriate leaf of the tree
> ------------------------------
|--- friends_broken_in_steal:1 <= 0.50
| |--- physically_ass:0 <= 0.50
| | |--- weights: [0.71, 0.29] class: 0.0
| |--- physically_ass:0 > 0.50
| | |--- weights: [0.95, 0.05] class: 0.0
|--- friends_broken_in_steal:1 > 0.50
| |--- non-exp_past_year_marijuana:0 <= 0.50
| | |--- weights: [0.33, 0.67] class: 1.0
| |--- non-exp_past_year_marijuana:0 > 0.50
| | |--- weights: [0.60, 0.40] class: 0.0This tree structure clearly shows how predictions are made based on feature values, providing transparency into the model’s decision-making process.