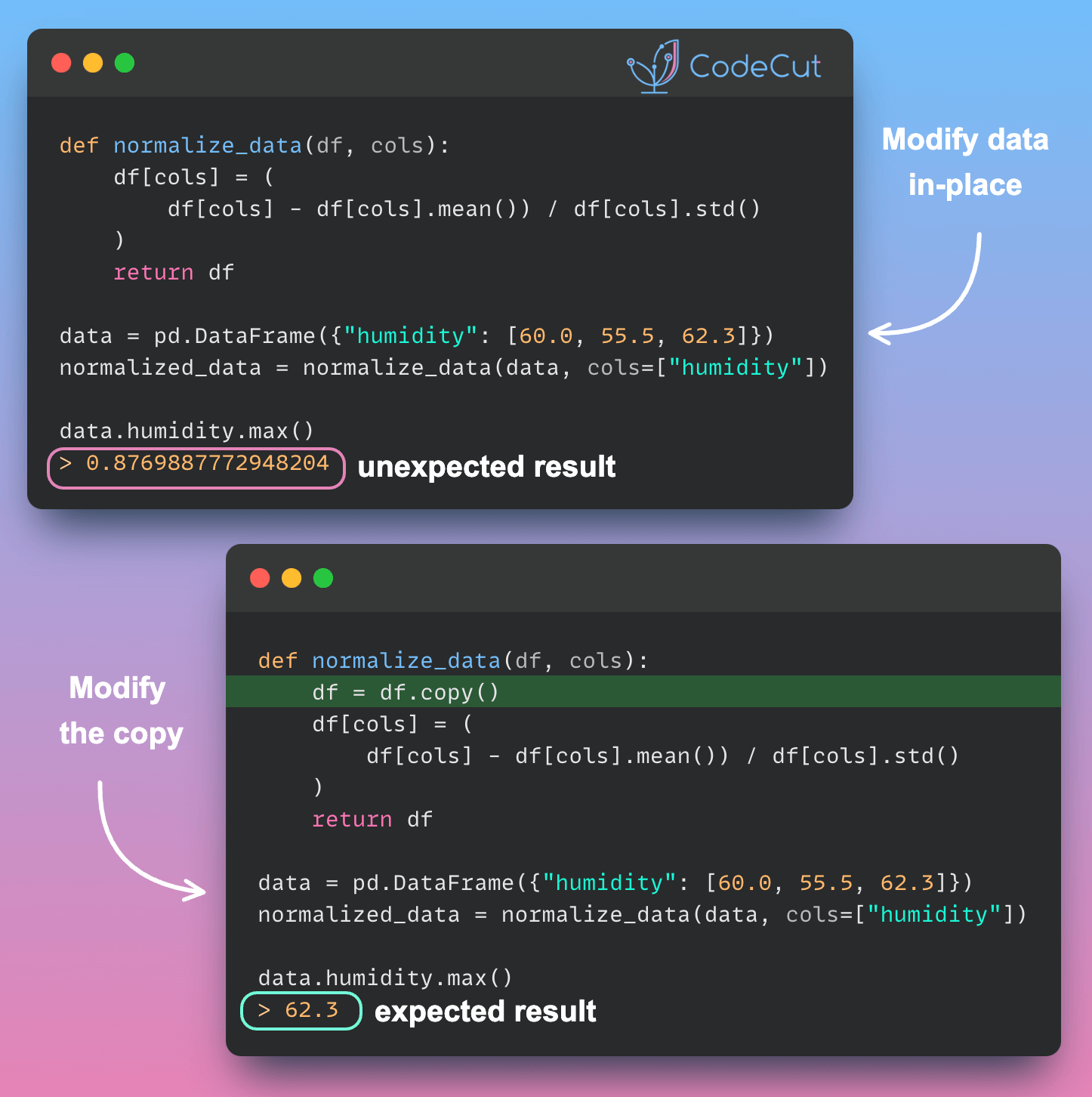
Modifying input DataFrames directly within functions can lead to unintended consequences and make your code harder to understand and maintain. Consider this example where we modify a DataFrame in-place:
import pandas as pd
def normalize_data(df: pd.DataFrame, columns: list) -> pd.DataFrame:
df[columns] = (df[columns] - df[columns].mean()) / df[columns].std()
return df
data = pd.DataFrame(
{
"temperature": [25.5, 27.8, 23.2],
"humidity": [60.0, 55.5, 62.3],
"pressure": [1013.2, 1015.7, 1012.8],
}
)
normalized_data = normalize_data(data, columns=["humidity"])
print(f"Original data:\n{data.head()}")
print(f"Maximum humidity: {data.humidity.max()}")Output:
Original data:
temperature humidity pressure
0 25.5 0.212019 1013.2
1 27.8 -1.089008 1015.7
2 23.2 0.876989 1012.8
Maximum humidity: 0.8769887772948204In this example, the original DataFrame data is modified in-place. This can cause issues if you need to use the original data later in your analysis or if other parts of your code depend on the unmodified data. For instance, the maximum humidity value is no longer 62.3 as it was in the original data.
Instead, create a copy of the input DataFrame before modifying it:
import pandas as pd
def normalize_data(df: pd.DataFrame, columns: list) -> pd.DataFrame:
df = df.copy()
df[columns] = (df[columns] - df[columns].mean()) / df[columns].std()
return df
data = pd.DataFrame(
{
"temperature": [25.5, 27.8, 23.2],
"humidity": [60.0, 55.5, 62.3],
"pressure": [1013.2, 1015.7, 1012.8],
}
)
normalized_data = normalize_data(data, columns=["humidity"])
print(f"Original data:\n{data}")
print(f"Maximum humidity of original data: {data.humidity.max()}")Output:
Original data:
temperature humidity pressure
0 25.5 60.0 1013.2
1 27.8 55.5 1015.7
2 23.2 62.3 1012.8
Maximum humidity of original data: 62.3In this improved version, we create a copy of the input DataFrame using df.copy() before performing any modifications. This approach preserves the original data and returns a new, normalized DataFrame.
This method is particularly useful in data science projects where you often need to compare results before and after transformations or when you want to apply different processing steps to the same original dataset. It also helps prevent unexpected behavior in other parts of your code that might rely on the original, unmodified data.