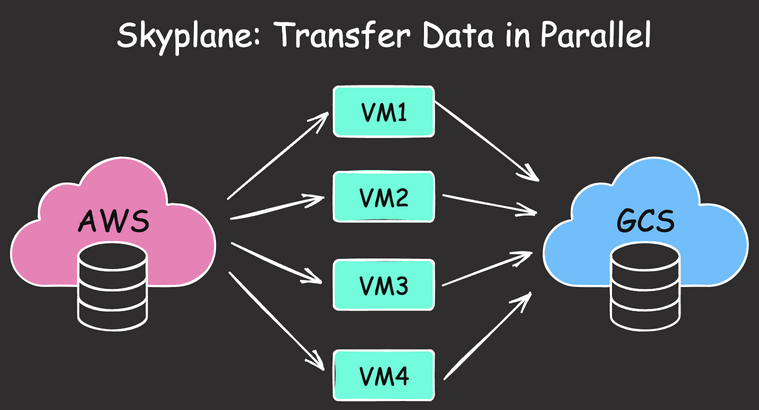
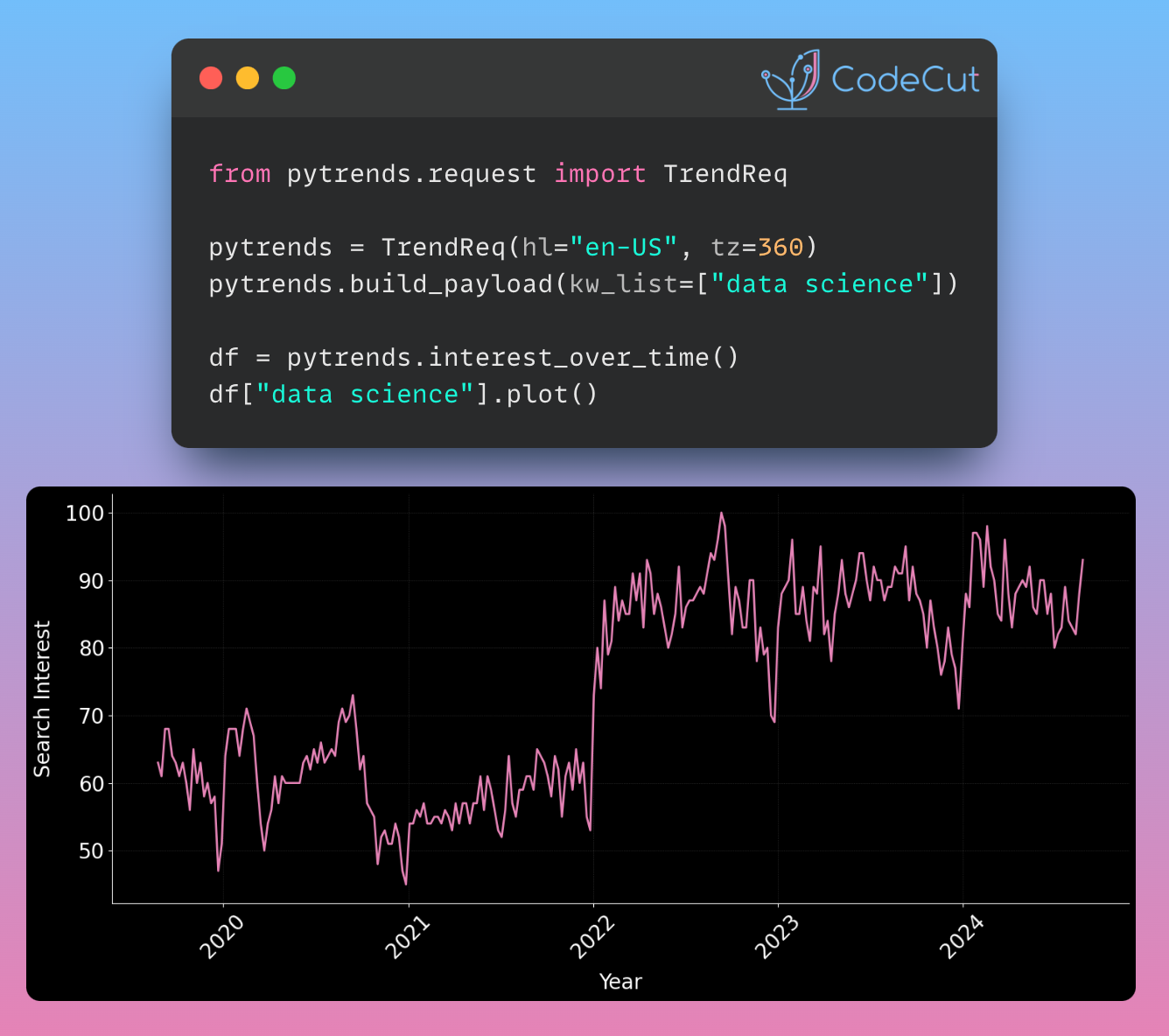
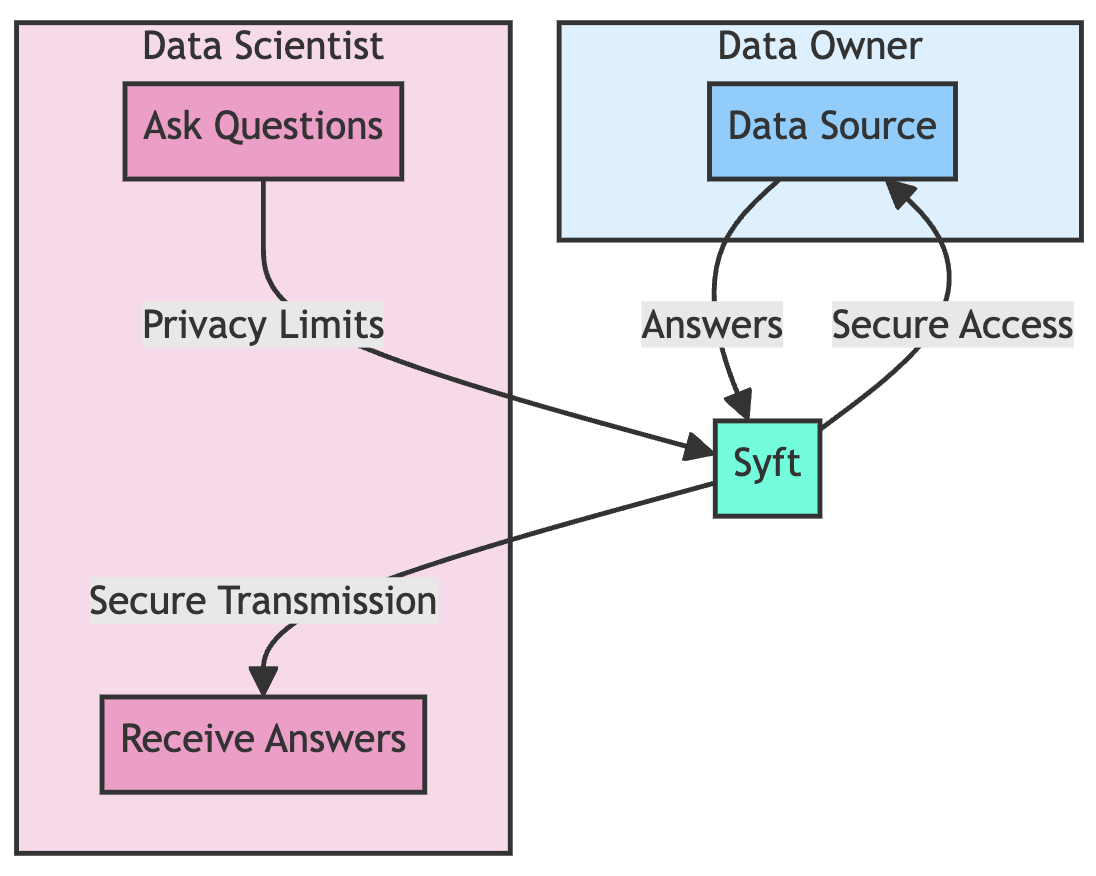
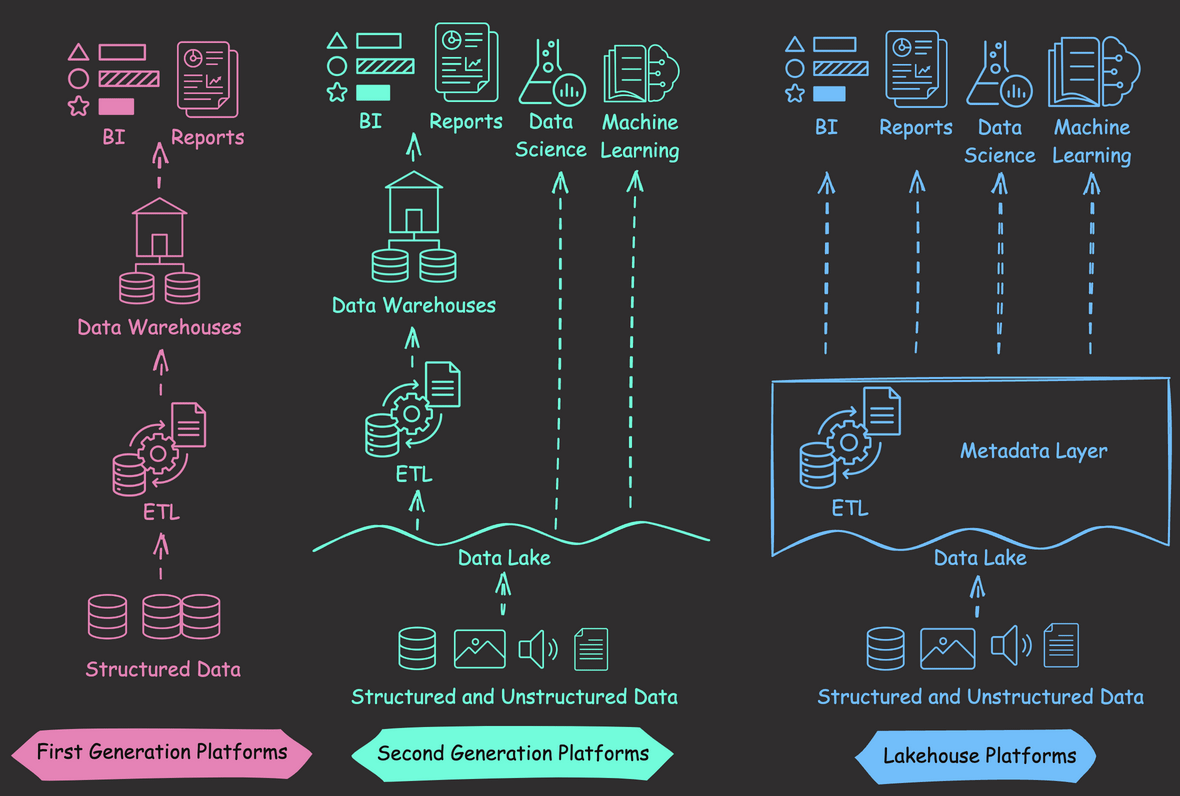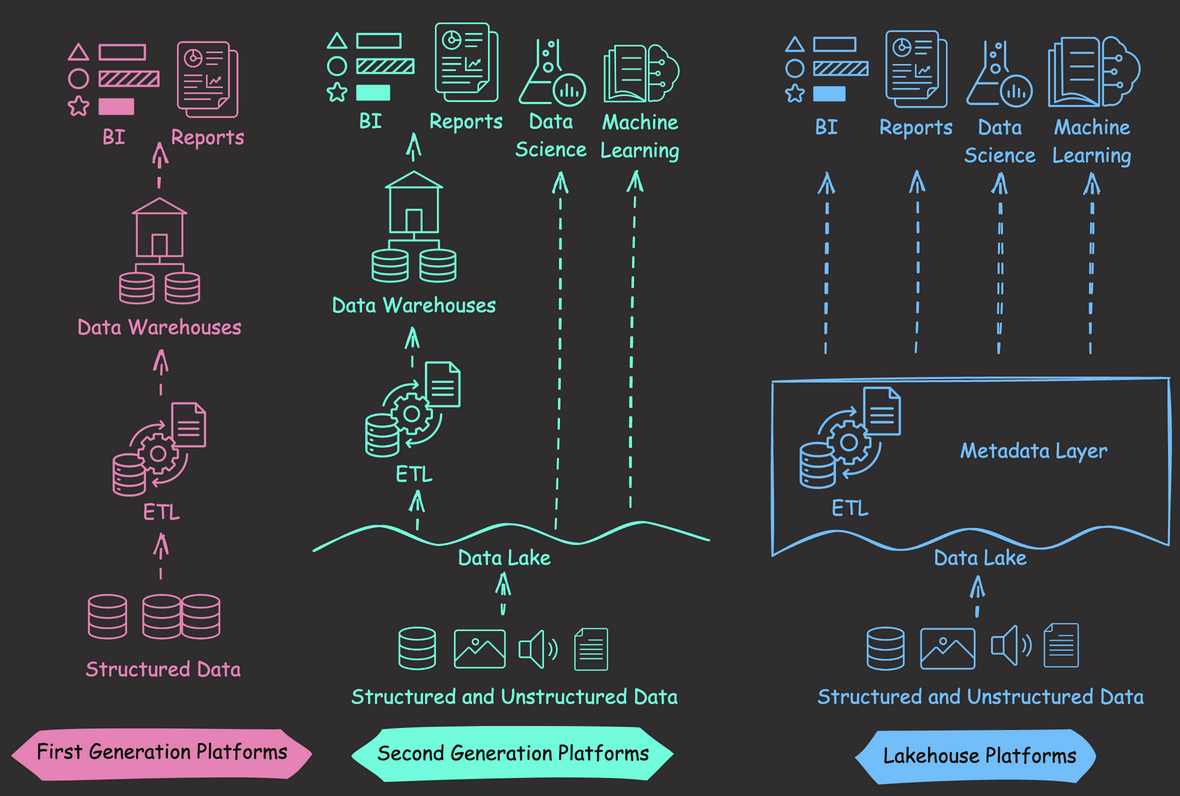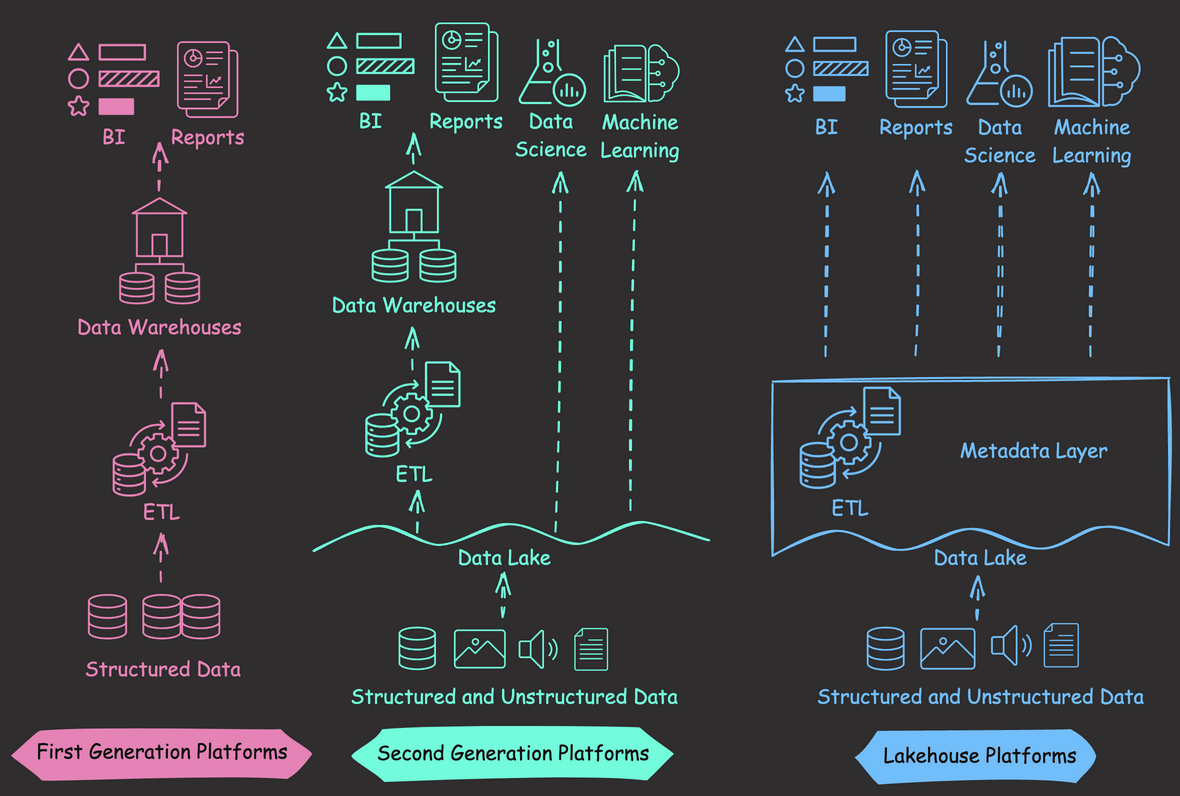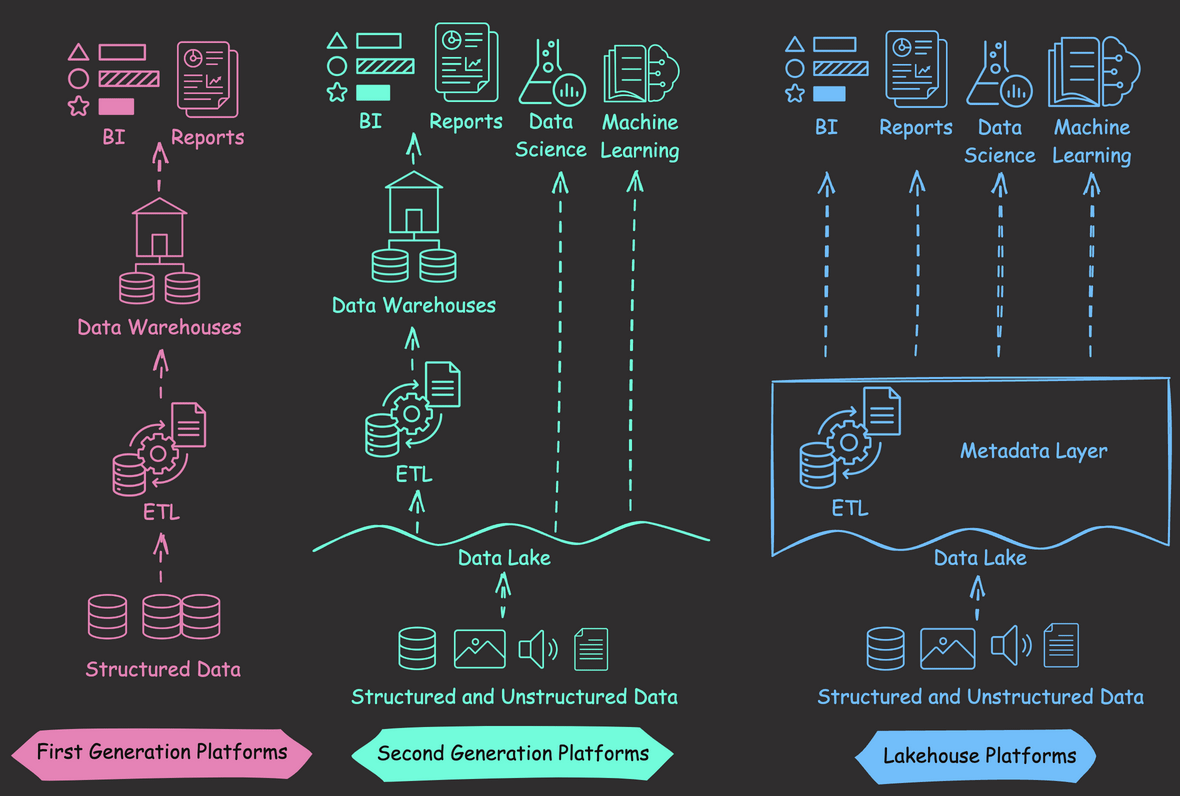
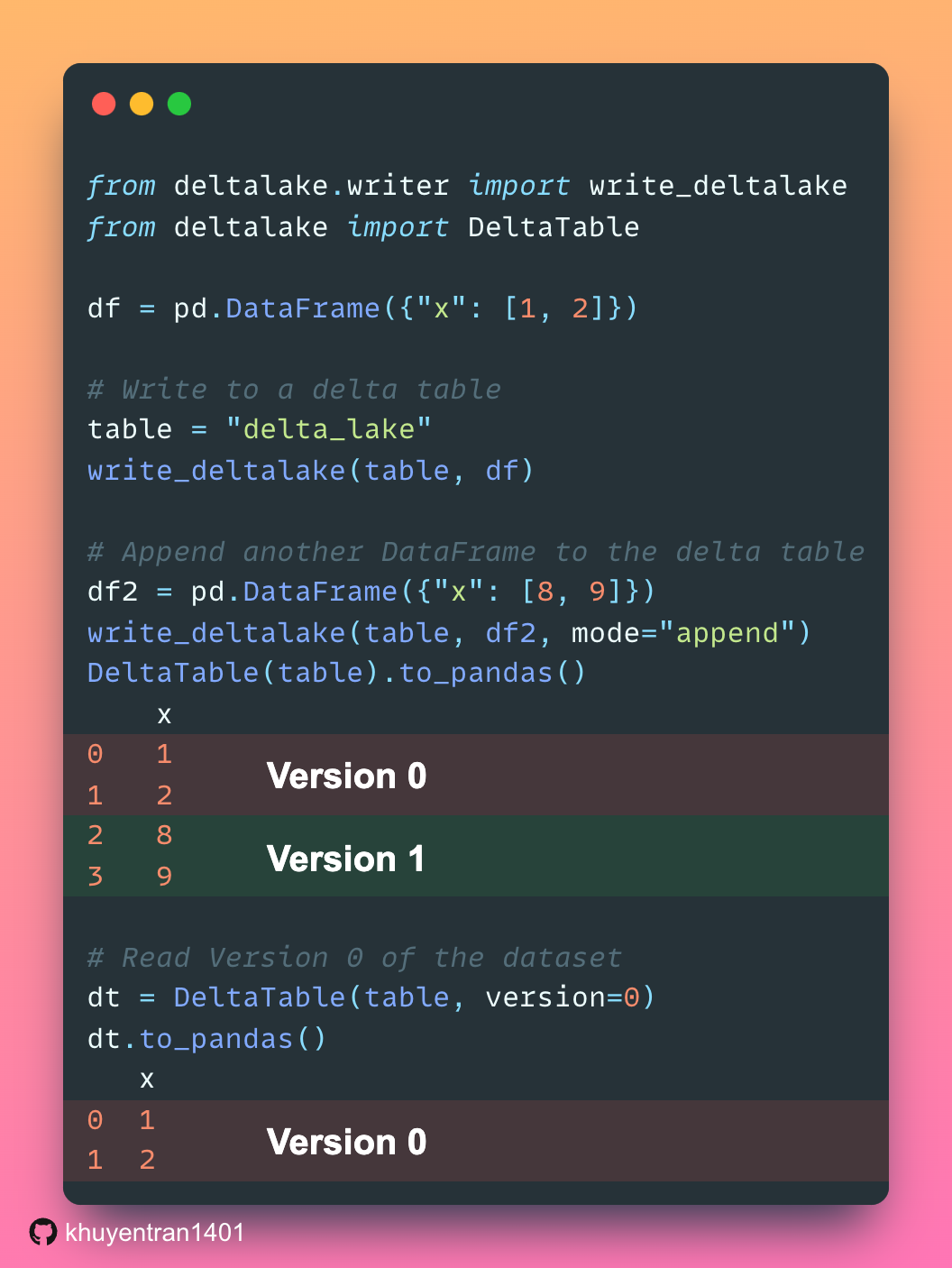
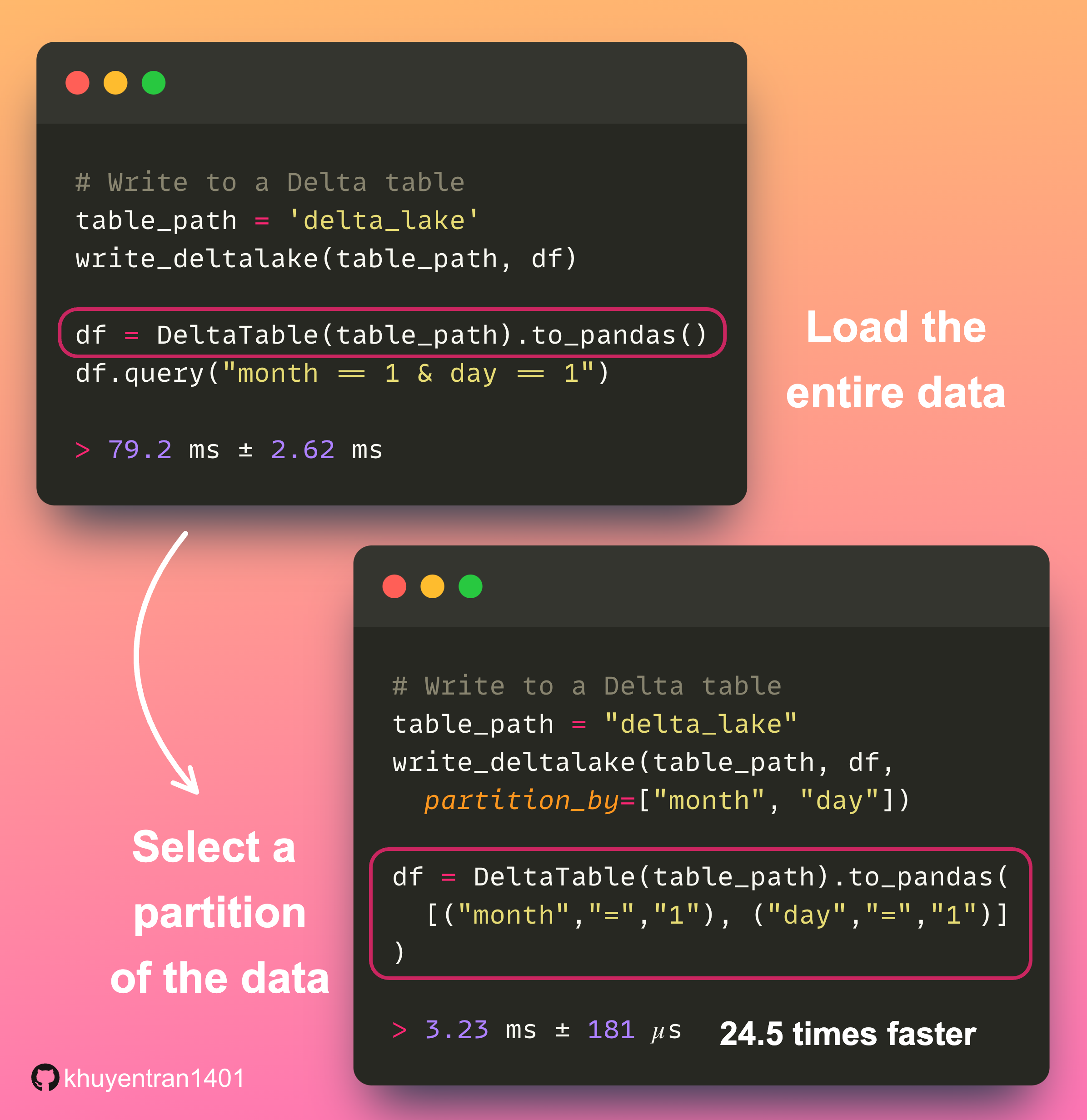
Data Analysis & ManipulationAnalyze DataManage DataFeature EngineerSQLMachine Learning & AIMachine LearningNatural Language ProcessingTime SeriesLLMCode QualityPython TipsPython-UtilitiesCode OptimizationDevOpsTestingGitCommand LineEnvironment ManagementBetter OutputsToolsNumPyPandasPolarsPySparkDelta LakeDuckDBJupyter NotebookVisualization & ReportingDashboardVisualizationWorkflow & AutomationWorkflow AutomationScrape DataX SDV: Use SDV to Generate Realistic Synthetic Datasets March 19, 2025 Accelerate Cloud Data Transfers with Skyplane’s Parallel Processing March 13, 2025 Generating Synthetic Tabular Data with TabGAN January 26, 2025 Building a High-Performance Data Stack with Polars and Delta Lake January 5, 2025 Delta Lake vs Parquet: Preventing Data Loss During Write Operations October 27, 2024 Ensure Pandas’ Data Integrity with Delta Lake Constraints September 29, 2024 Exploring Google Trends with Pytrends API August 29, 2024 From Complex SQL to Simple Merges: Delta Lake’s Upsert Solution August 20, 2024 Syft: Sensitive Data Collaboration Made Secure June 20, 2024 The Lakehouse Model: Bridging the Gap Between Data Lakes and Warehouses February 5, 2024 Delta Lake: Ensuring Schema Consistency for Clean Data December 1, 2023 Grist: A Hybrid Database/Spreadsheet for Efficient Data Management November 27, 2023 Enhance Query Efficiency with Z Order in Delta Lake October 3, 2023 Version Your Pandas DataFrame with Delta Lake September 8, 2023 Optimize Query Speed with Data Partitioning August 28, 2023 « Previous Page1 Page2 Next »