
🤝 COLLABORATION
What Data Engineers Really Think About Airflow (5.8K Surveyed)
Astronomer analyzed 5.8k+ responses from data engineers on how they are navigating Airflow today and the findings might surprise you.
You’ll learn:
- How early adopters are using Airflow 3 features in production
- Which teams are bringing AI into production and what’s holding others back
- 35.6% believe that Airflow is beneficial to their career
📅 Today’s Picks
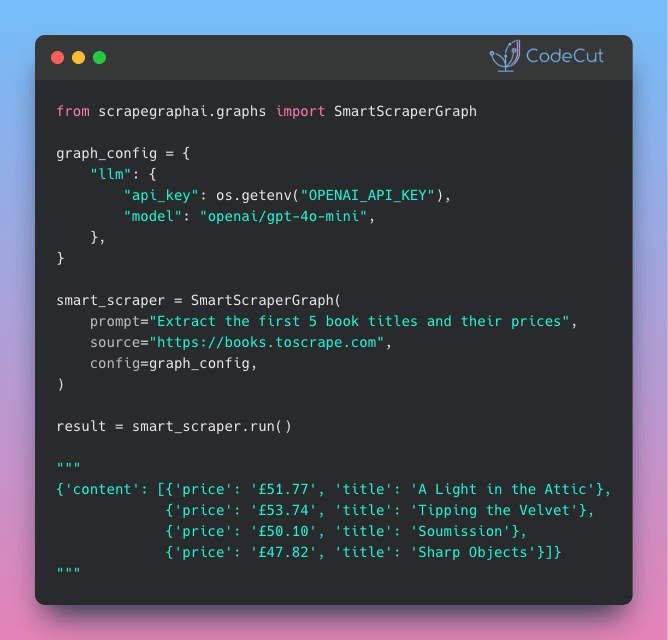
ScrapeGraphAI: Scrape Any Website with Natural Language

Problem
Traditional scraping with BeautifulSoup follows a familiar pattern: fetch HTML, inspect elements in DevTools, and write CSS selectors to extract your data.
But websites don’t stay static. When the HTML structure changes, your selectors break and you’re back to rewriting code.
Solution
ScrapeGraphAI uses LLMs to extract data from natural language descriptions. Simply describe what you want in plain English, and the LLM figures out the extraction logic automatically.
Key features:
- Self-healing scrapers that adapt when websites are redesigned
- Type-safe output with Pydantic schema validation
- Built-in JavaScript rendering for React, Vue, and Angular sites
- Multi-page scraping with SearchGraph for research tasks
- Cloud or local models via OpenAI, Anthropic, or Ollama
Plus, ScrapeGraphAI is open source! Install it with “pip install scrapegraphai”.
🔄 Worth Revisiting
Analyze GitHub Repositories with LangChain Document Loaders
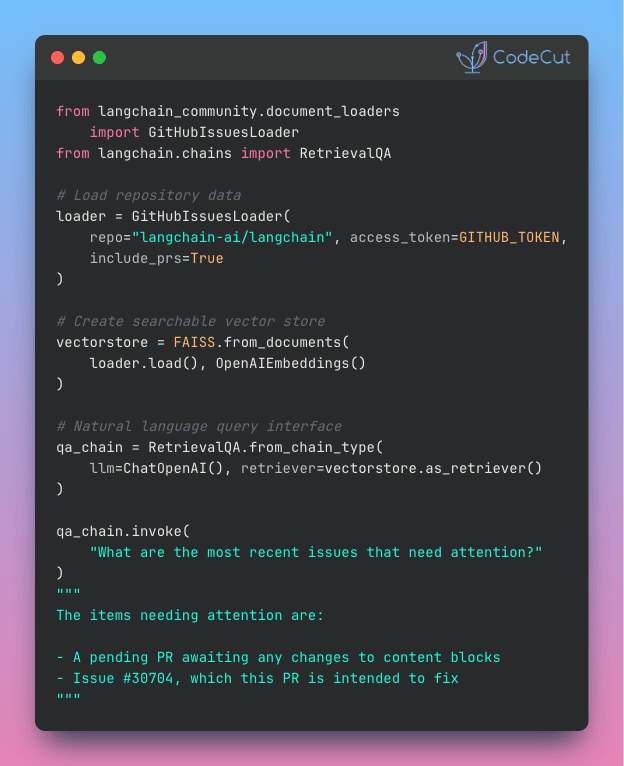
Problem
Are you tired of manually searching through hundreds of GitHub issues with keyword search to find what you need?
Solution
With LangChain’s GitHubIssuesLoader, you can load repository issues into a vector store and query them with natural language instead of exact keywords.
You can ask questions like “What feature requests are related to video?” and get instant, relevant answers from your issue history.
☕️ Weekly Finds
hf-mem [ML] – CLI to estimate inference memory requirements for Hugging Face models before downloading
fake2db [Testing] – Create custom test databases populated with fake data for SQLite, MySQL, PostgreSQL, and MongoDB
MiraTTS [LLM] – High-quality text-to-speech model fine-tuned from Spark-TTS with enhanced realism and stability
Looking for a specific tool? Explore 70+ Python tools →
📚 Latest Deep Dives
From CSS Selectors to Natural Language: Web Scraping with ScrapeGraphAI – Web scraping without selector maintenance. ScrapeGraphAI uses LLMs to extract data from any site using plain English prompts and Pydantic schemas.
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.