Grab your coffee. Here are this week’s highlights.
📅 Today’s Picks
Marker: Smart PDF Extraction with Hybrid LLM Mode
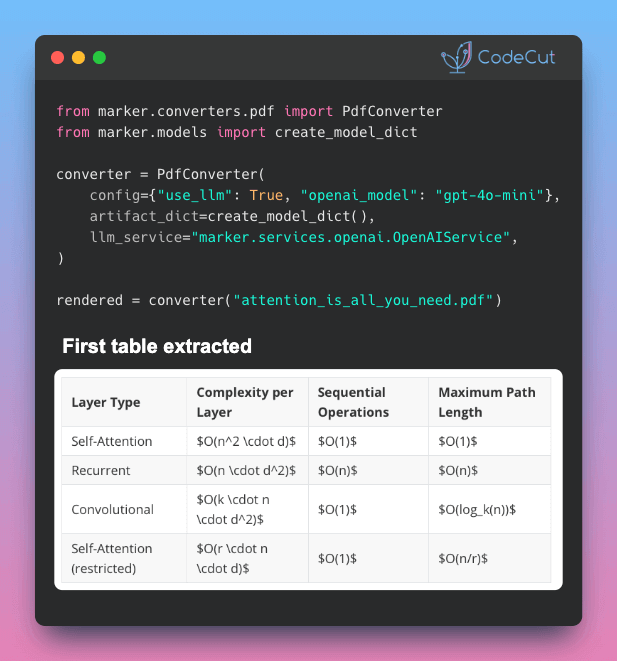
Problem
Standard OCR pipelines often miss inline math, split tables across pages, and lose the relationships between form fields.
Sending the full document to an LLM can improve accuracy, but it’s slow and expensive at scale.
Solution
Marker‘s hybrid mode takes a more targeted approach:
- Its deep learning pipeline handles the bulk of conversion
- Then an LLM steps in only for the hard parts: table merging, LaTeX formatting, and form extraction
Marker supports OpenAI, Gemini, Claude, Ollama, and Azure out of the box.
Qdrant: Fast Vector Search in Rust with a Python API

Problem
Building semantic search typically starts with storing vectors in Python lists and computing cosine similarity manually.
But brute-force comparison scales linearly with your dataset, making every query slower as your data grows.
Solution
Qdrant is a vector search engine built in Rust that indexes your vectors for fast retrieval.
Key features:
- In-memory mode for local prototyping with no server setup
- Seamlessly scale to millions of vectors in production with the same Python API
- Built-in support for cosine, dot product, and Euclidean distance
- Sub-second query times even for millions of vectors
📚 Latest Deep Dives
PDF Table Extraction: Docling vs Marker vs LlamaParse Compared
Extracting tables from PDFs can be surprisingly difficult. A table that looks neatly structured in a PDF is actually saved as text placed at specific coordinates on the page. This makes it difficult to preserve the original layout when extracting the table.
This article will introduce three Python tools that attempt to solve this problem: Docling, Marker, and LlamaParse.
☕️ Weekly Finds
Dify [LLM] – Open-source LLM app development platform with AI workflow, RAG pipeline, and agent capabilities
PageIndex [RAG] – Document index for vectorless, reasoning-based RAG
MCP Server Chart [Data Visualization] – A visualization MCP server for generating 25+ visual charts using AntV
Looking for a specific tool? Explore 70+ Python tools →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.