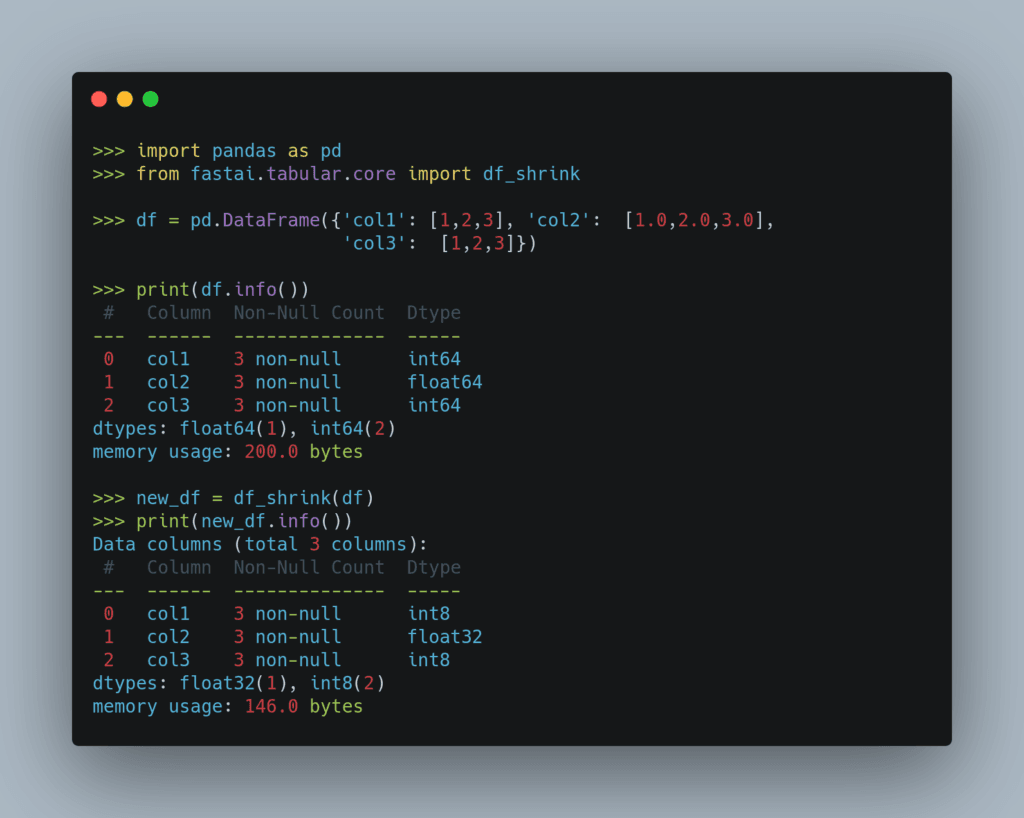
Encode Rare Labels with Feature-engine
When dealing with features with high cardinality, you might want to mark the rare categories as “Other”. Feature-engine’s RareLabelEncoder makes it easy for you to do so.
In the code above, we use RareLabelEncoder to replace categories with the frequency below 0.05 in the column “education” with “Other”.