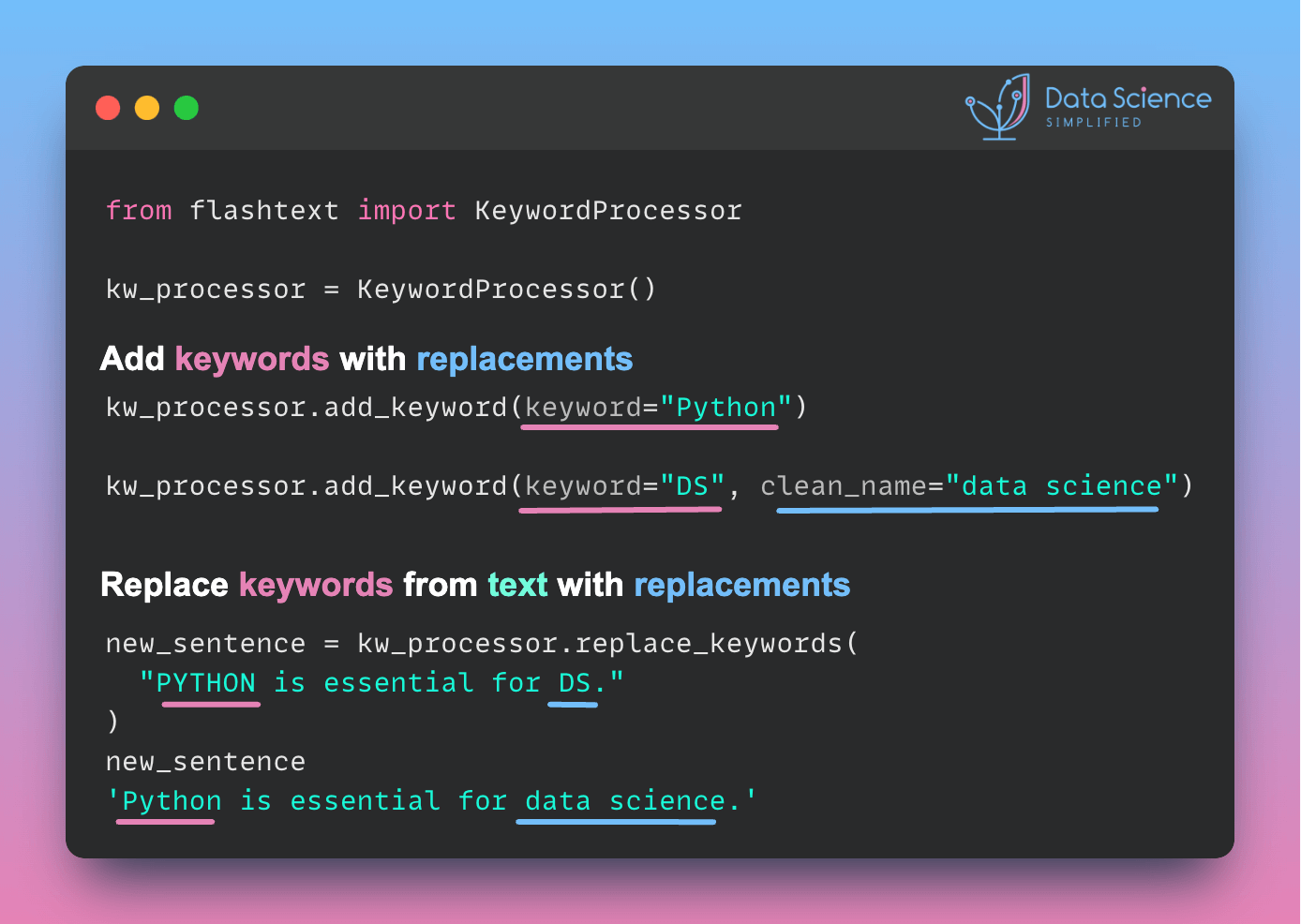
Efficient Keyword Extraction and Replacement with FlashText
If you want to perform fast keyword extraction and replacement in text, use FlashText.
Efficient Keyword Extraction and Replacement with FlashText Read More »
If you want to perform fast keyword extraction and replacement in text, use FlashText.
Efficient Keyword Extraction and Replacement with FlashText Read More »
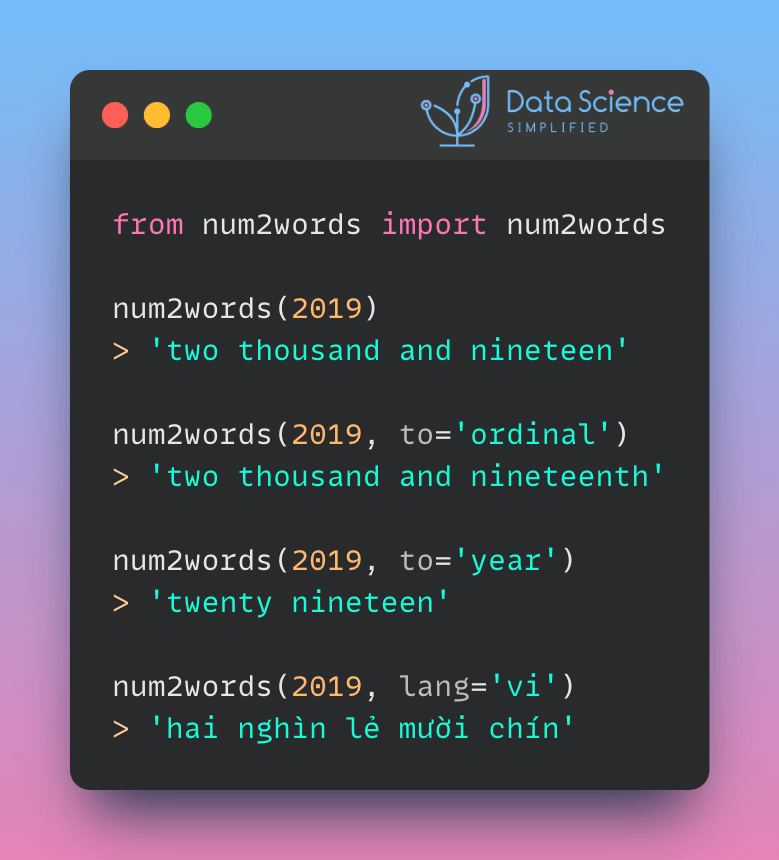
When data contains both a numerical value (2019) and a written expression (‘two thousand and nineteen’) that represent the same quantity, it’s essential for them to match for accurate NLP interpretation.
This can be achieved by using num2words, which helps convert numbers to their word equivalent. The library can also generate ordinal numbers and support multiple languages.

If you want to clean, gain insights, and create embeddings from massive unstructured text datasets, use Galatic.
Galatic: Clean and Analyze Massive Text Datasets Read More »
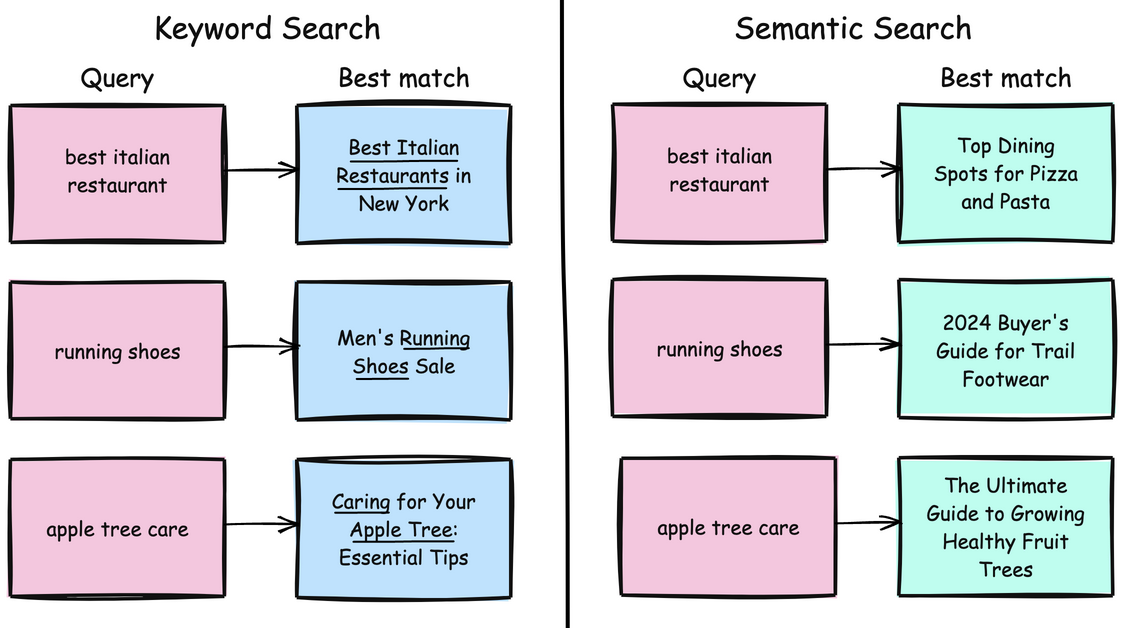
Traditional search systems rely on keywords to retrieve data, whereas semantic search uses natural language understanding to identify results with similar meanings.
txtai is an all-in-one embedding database for semantic search that enables vector search with SQL, topic modeling, retrieval augmented generation, and more.
txtai: All-in-one open-source embeddings database for semantic search Read More »
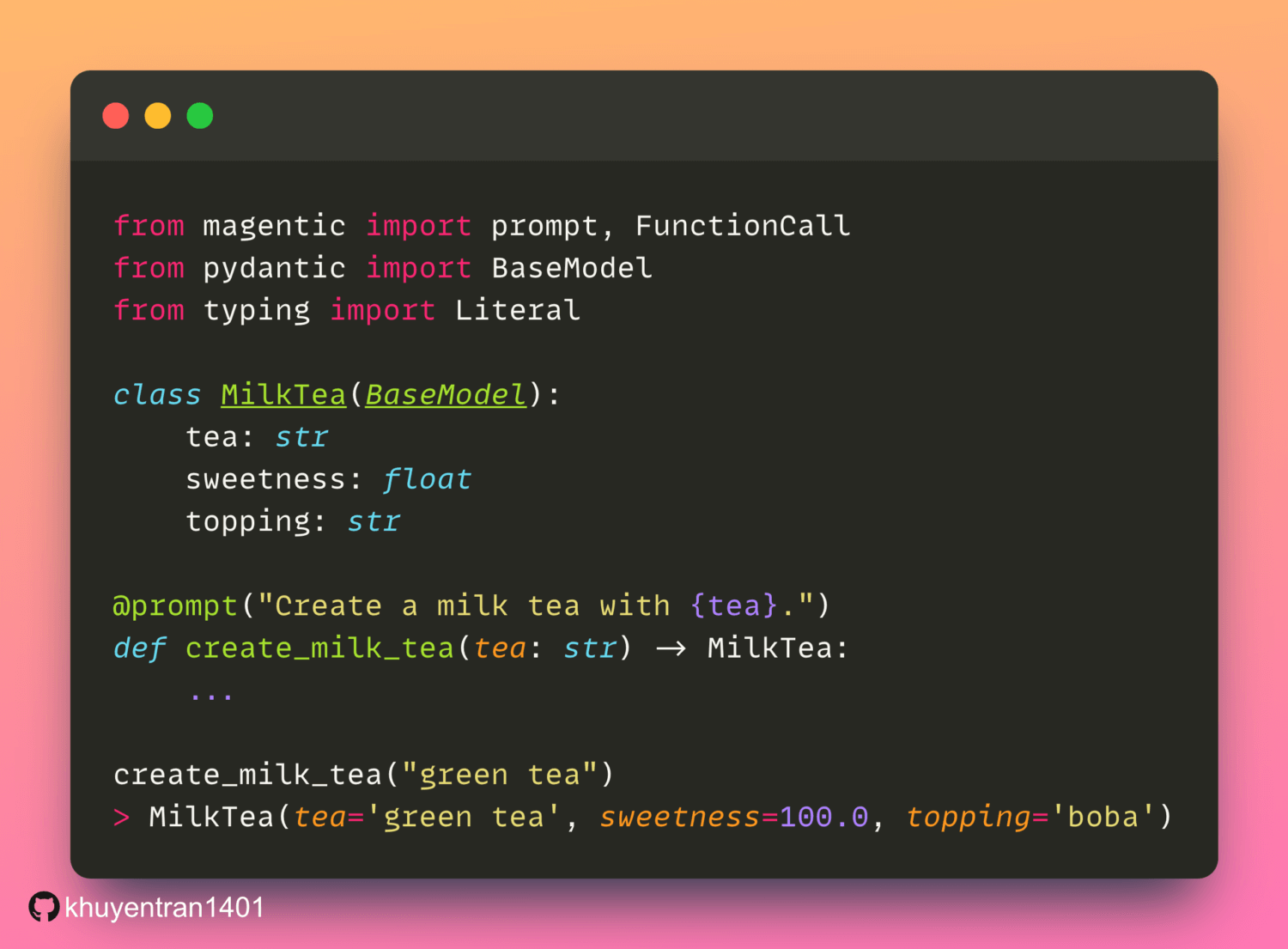
To enhance your code’s natural language skills with LLM effortlessly, try magentic.
With magentic, you can use the @prompt decorator to create functions that return organized LLM results, keeping your code neat and easy to read.
Simplify LLM Integration with Magentic’s @prompt Decorator Read More »

Processing text in a DataFrame often involves writing lengthy code. Texthero simplifies this by enabling one-line preprocessing, including:
– filling missing values
– converting upper case to lower case
– removing digits
– removing punctuation
– removing stopwords
– removing whitespace
Preprocess Text in One Line of Code with Texthero Read More »
If you want to quickly extract meaningful information from an article in a few lines of code, try newspaper3k.
newspaper3k: Extract Information From an Article in Two Lines of Code Read More »

If you want to quickly visualize the frequency of tokens in a collection of text documents, use the combination of scikit-learn’s CountVectorizer and Yellowbrick’s FreqDistVisualizer.
Visualize the Frequency Tokens in a Text Corpora Read More »

If you want to extract a contiguous sequence of words from a text, use textacy.ngrams

ekphrasis allows you to create a pipeline to process text from social media such as Twitter or Facebook.
ekphrasis: Text Processing Tool For Social Media Text Read More »