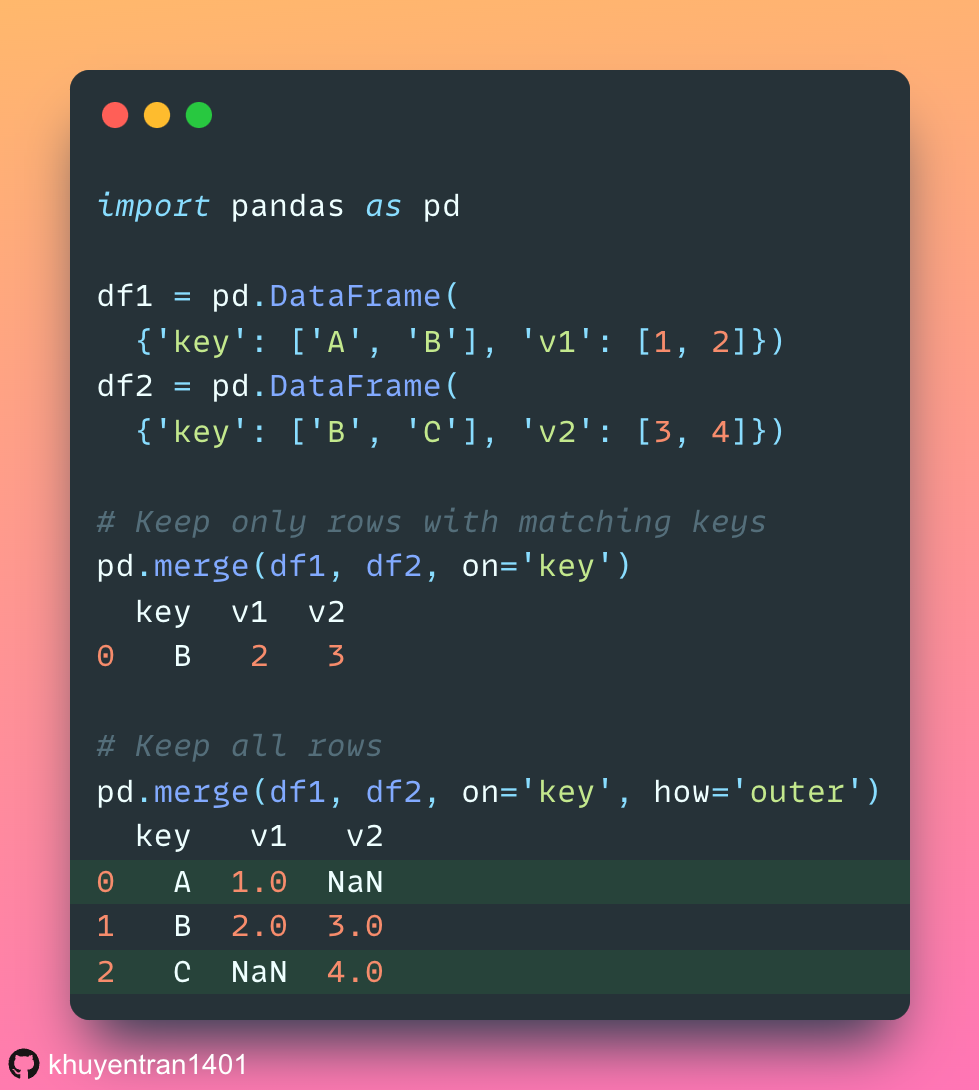
Version Your Pandas DataFrame with Delta Lake
To undo errors, avoid losing data, and reproduce results, it is crucial to implement a version control system for your data.
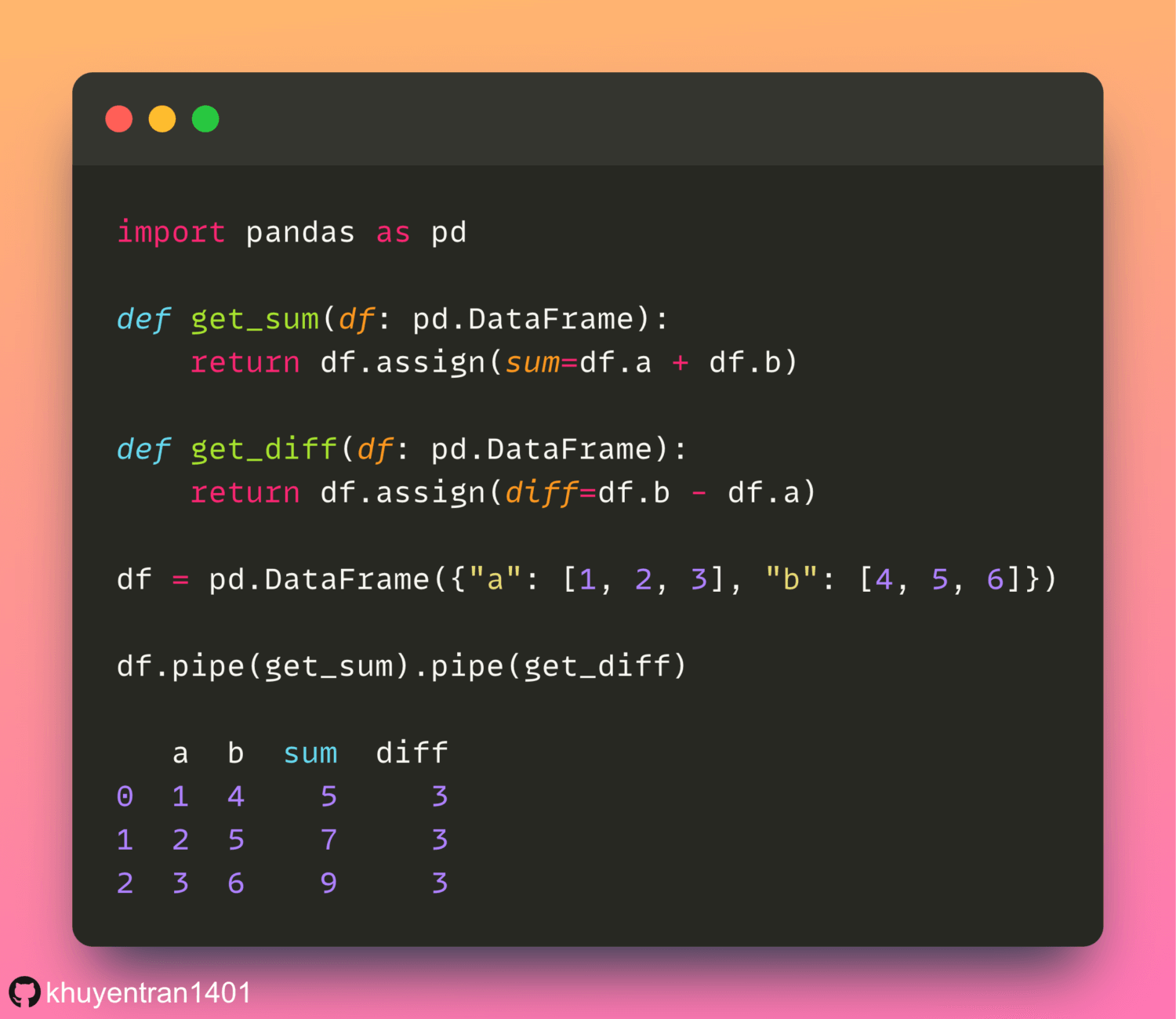
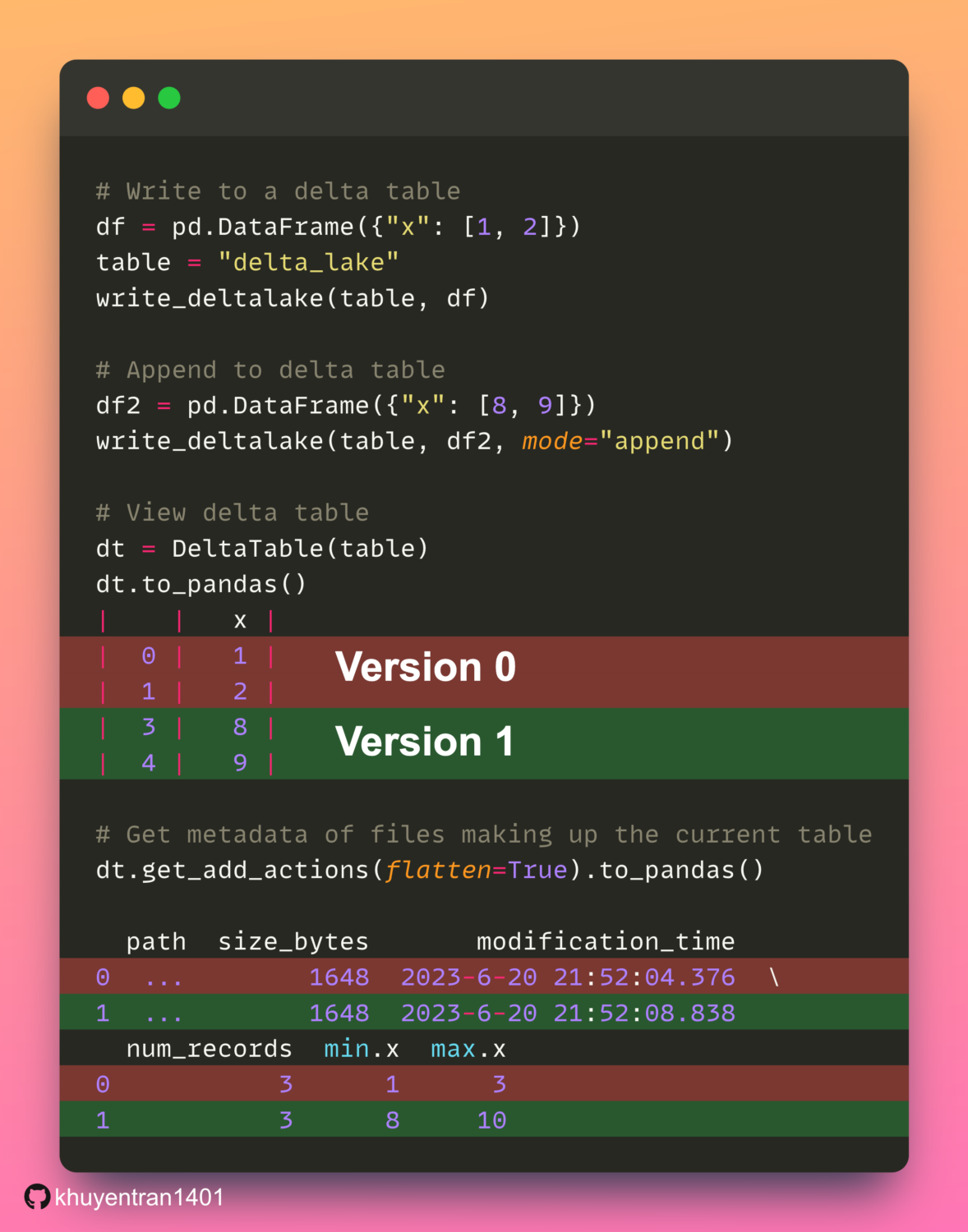
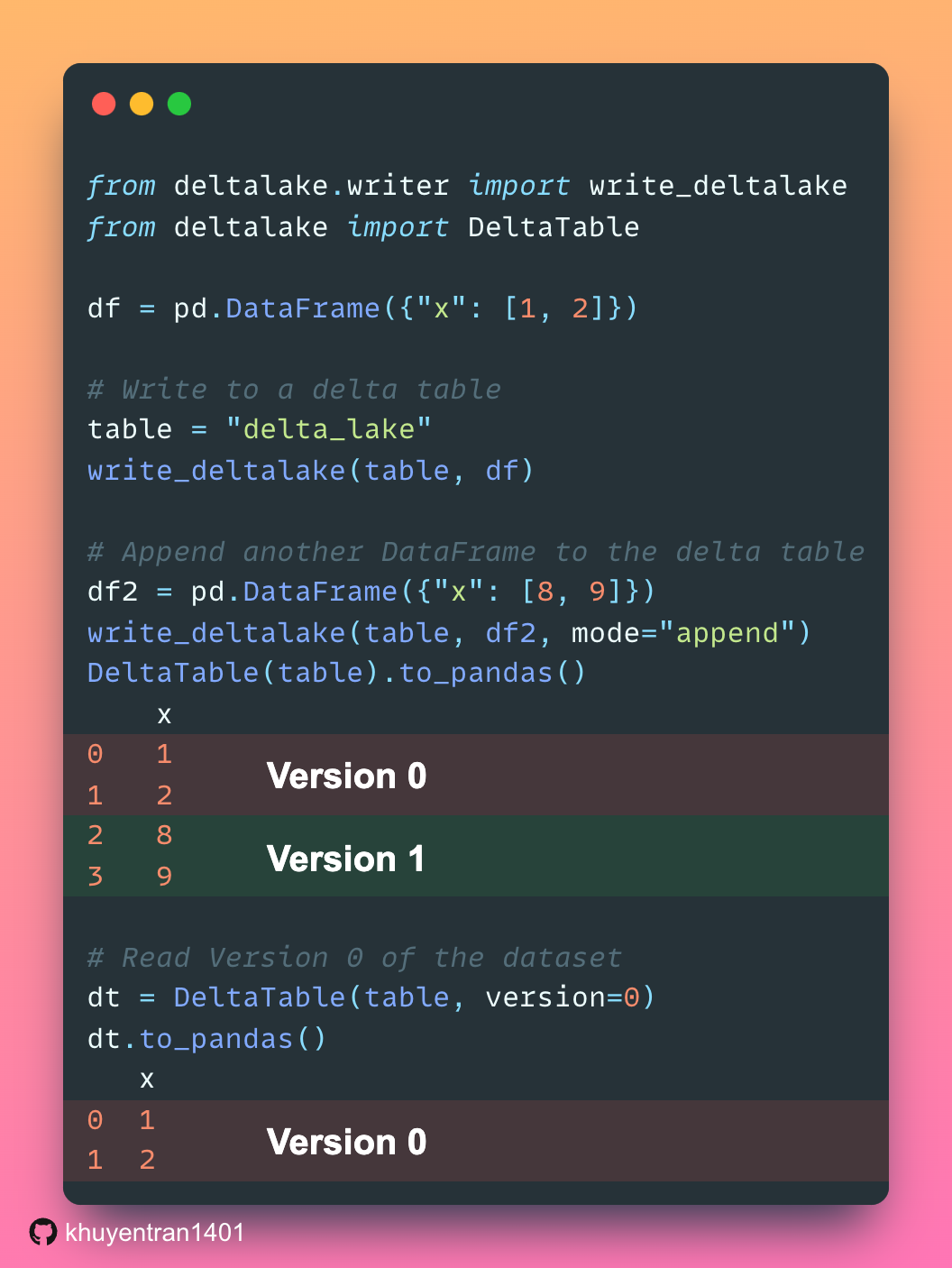
Delta Lake simplifies pandas DataFrame versioning and allows access to prior versions for auditing and debugging.
In the example above, Delta Lake creates two versions of a DataFrame. Version 0 contains the original data, while Version 1 includes the data that was appended.