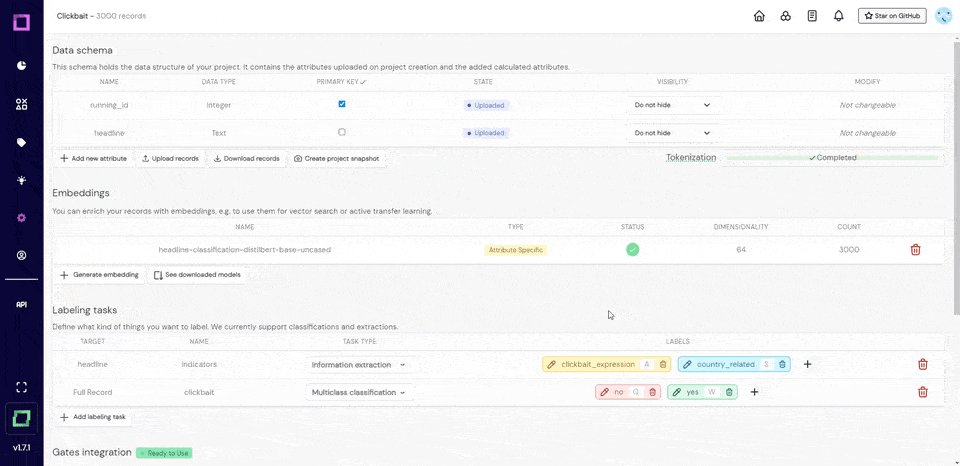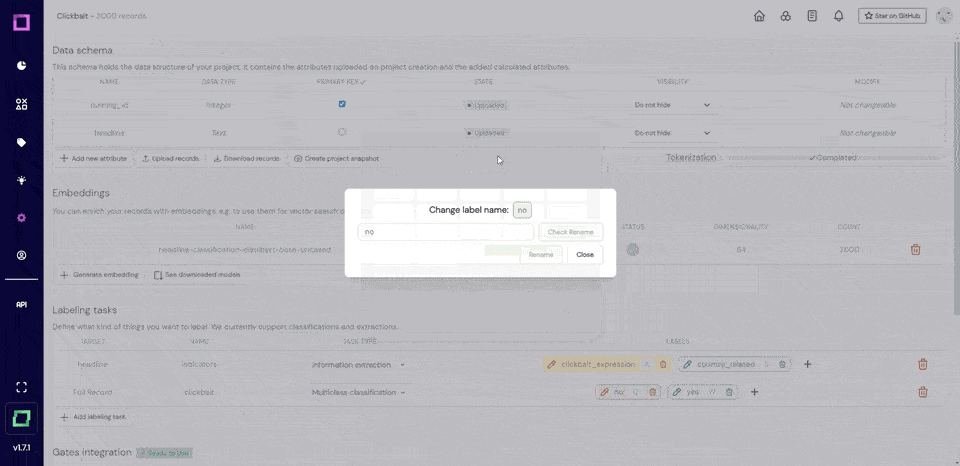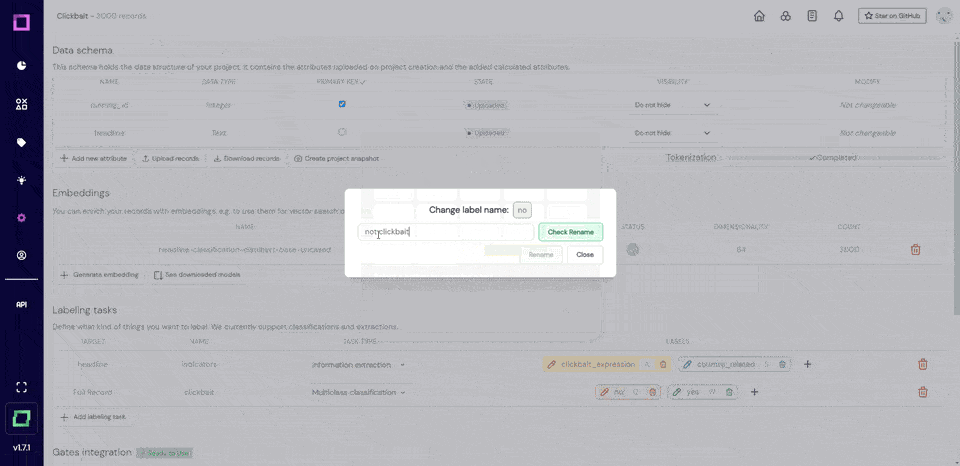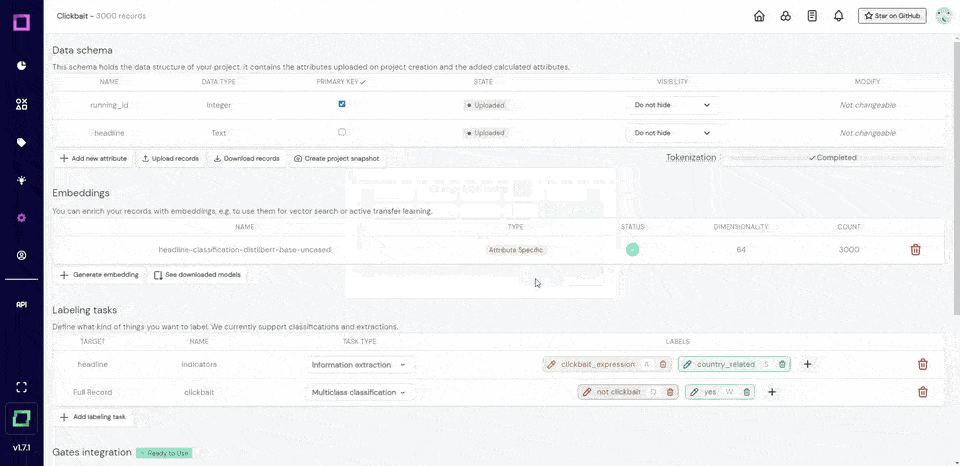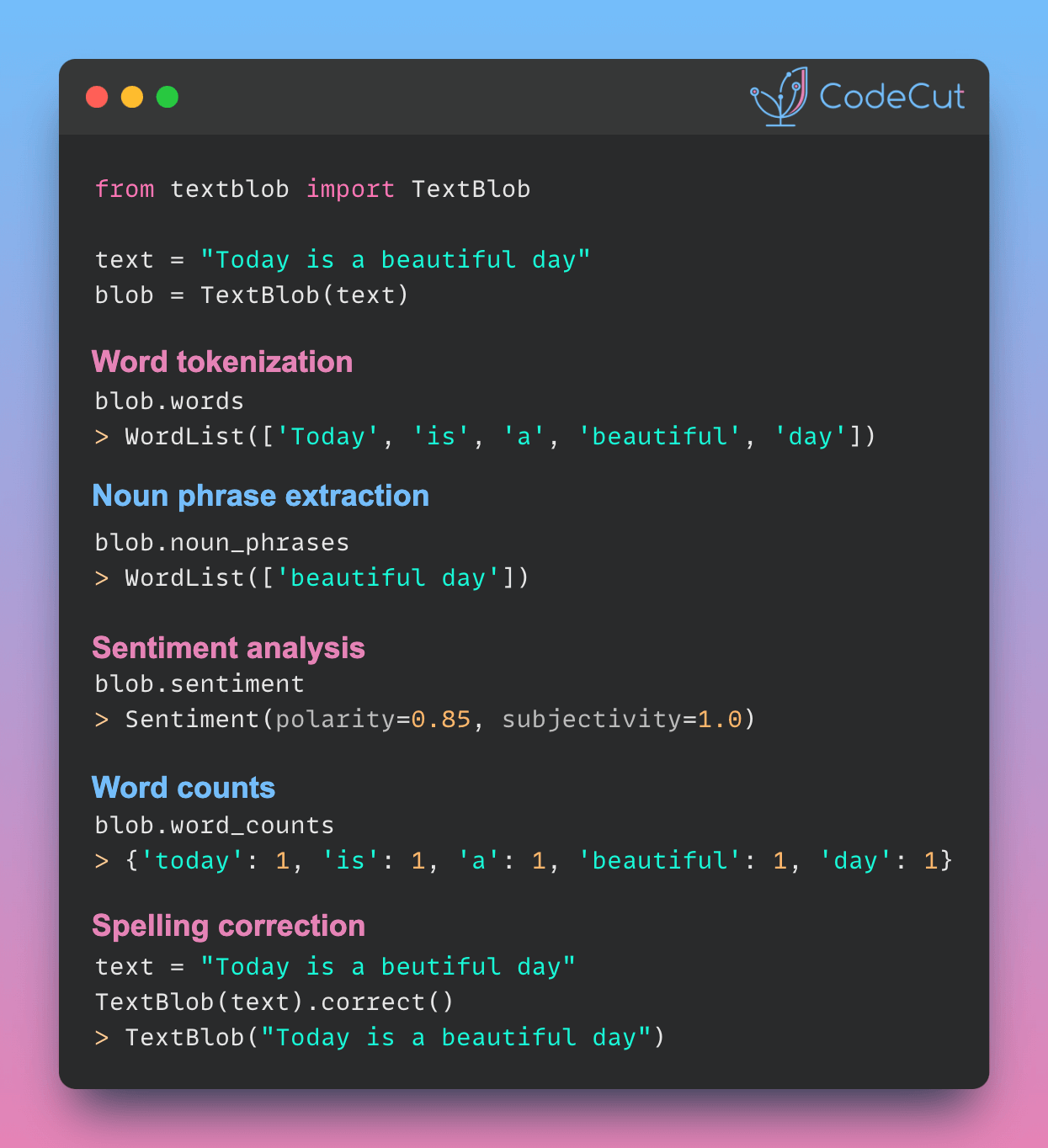

To quickly analyze text, including determining its sentiment, tokenization, noun phrase and word frequency analysis, and spelling correction, use TextBlob.
To use TextBlob, start with creating a new instance of the TextBlob class with the text “Today is a beautiful day”.
from textblob import TextBlob
text = "Today is a beautiful day"
blob = TextBlob(text)Tokenize words:
blob.wordsWordList(['Today', 'is', 'a', 'beautiful', 'day'])Extract noun phrases:
blob.noun_phrasesWordList(['beautiful day'])Analyze sentiment:
blob.sentimentSentiment(polarity=0.85, subjectivity=1.0)Count words:
blob.word_countsdefaultdict(int, {'today': 1, 'is': 1, 'a': 1, 'beautiful': 1, 'day': 1})Correct spelling:
text = "Today is a beutiful day"
blob = TextBlob(text)
blob.correct()TextBlob("Today is a beautiful day")