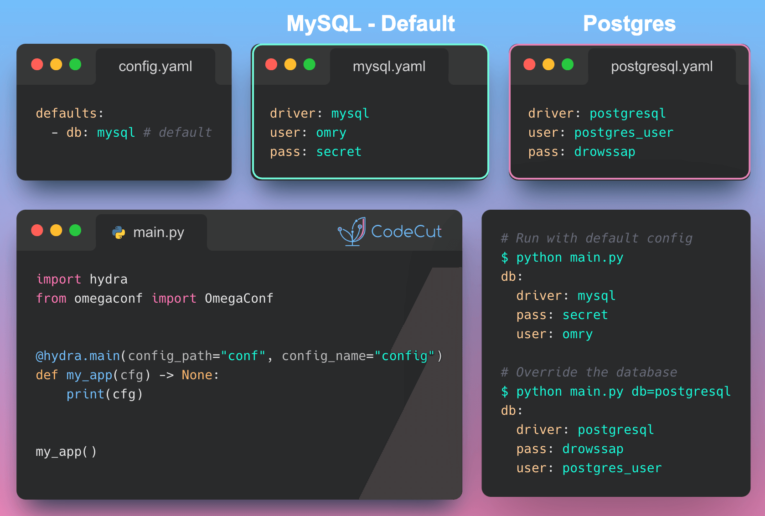
Using MLflow to log models offers distinct advantages over Pickle. Here’s a detailed look at the benefits:
Managing Library Versions
Problem
Different machine learning models may depend on various versions of the same library, leading to compatibility conflicts. Manually tracking and configuring the correct environment for each model can be tedious and error-prone.
Solution
MLflow automatically logs all dependencies, allowing users to easily recreate the exact environment necessary to run the model. This feature simplifies deployment and enhances reproducibility.
Documenting Inputs and Outputs
Problem
The expected inputs and outputs of a model are often not well-documented, making it challenging for others to utilize the model correctly.
Solution
MLflow defines a clear schema for inputs and outputs, ensuring that users know precisely what data to provide and what to expect in return. This clarity fosters better collaboration and reduces confusion.
Example Implementation
To demonstrate the advantages of MLflow, let’s implement a simple logistic regression model and log it.
Logging the Model
import mlflow
from mlflow.models import infer_signature
import numpy as np
from sklearn.linear_model import LogisticRegression
with mlflow.start_run():
X = np.array([-2, -1, 0, 1, 2, 1]).reshape(-1, 1)
y = np.array([0, 0, 1, 1, 1, 0])
lr = LogisticRegression()
lr.fit(X, y)
signature = infer_signature(X, lr.predict(X))
model_info = mlflow.sklearn.log_model(
sk_model=lr, artifact_path="model", signature=signature
)
print(f"Saving data to {model_info.model_uri}")This code will output the location where the model is saved:
Saving data to runs:/f8b0fc900aa14cf0ade8d0165c5a9f11/modelUsing the Logged Model
To use the logged model later, you can load it with the model_uri:
import mlflow
import numpy as np
model_uri = "runs:/1e20d72afccf450faa3b8a9806a97e83/model"
sklearn_pyfunc = mlflow.pyfunc.load_model(model_uri=model_uri)
data = np.array([-4, 1, 0, 10, -2, 1]).reshape(-1, 1)
predictions = sklearn_pyfunc.predict(data)Inspecting Model Artifacts
Check the saved artifacts in mlruns/0/1e20d72afccf450faa3b8a9806a97e83/artifacts/model:
MLmodel model.pkl requirements.txt
conda.yaml python_env.yamlUnderstanding Model Configuration
The MLmodel file contains critical information about the model, including its dependencies and input/output specifications:
artifact_path: model
flavors:
python_function:
env:
conda: conda.yaml
virtualenv: python_env.yaml
loader_module: mlflow.sklearn
model_path: model.pkl
predict_fn: predict
python_version: 3.11.6
sklearn:
code: null
pickled_model: model.pkl
serialization_format: cloudpickle
sklearn_version: 1.4.1.post1
mlflow_version: 2.15.0
model_size_bytes: 722
model_uuid: e7487bc3c4ab417c965144efcecaca2f
run_id: 1e20d72afccf450faa3b8a9806a97e83
signature:
inputs: '[{"type": "tensor", "tensor-spec": {"dtype": "int64", "shape": [-1, 1]}}]'
outputs: '[{"type": "tensor", "tensor-spec": {"dtype": "int64", "shape": [-1]}}]'
params: null
utc_time_created: '2024-08-02 20:58:16.516963'Environment Specifications
The conda.yaml and python_env.yaml files detail the dependencies required for the model, ensuring a consistent runtime environment. Here’s a look at conda.yaml:
# conda.yaml
channels:
- conda-forge
dependencies:
- python=3.11.6
- pip<=24.2
- pip:
- mlflow==2.15.0
- cloudpickle==2.2.1
- numpy==1.23.5
- psutil==5.9.6
- scikit-learn==1.4.1.post1
- scipy==1.11.3
name: mlflow-envAnd for python_env.yaml and requirements.txt:
# python_env.yaml
python: 3.11.6
build_dependencies:
- pip==24.2
- setuptools
- wheel==0.40.0
dependencies:
- -r requirements.txt# requirements.txt
mlflow==2.15.0
cloudpickle==2.2.1
numpy==1.23.5
psutil==5.9.6
scikit-learn==1.4.1.post1
scipy==1.11.3