As a data scientist, mastering Python’s functions and generators is crucial for efficient and scalable data processing. Let’s explore these concepts using familiar analogies and see how they apply to real-world data science scenarios.
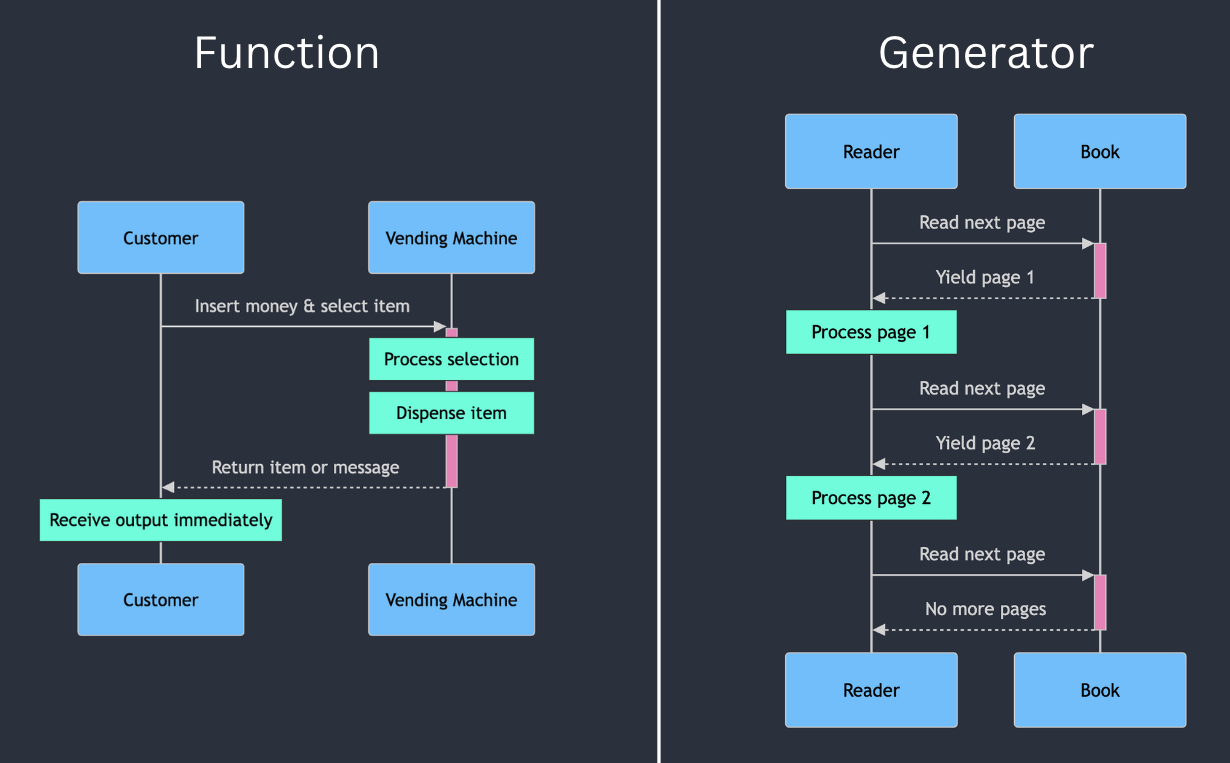
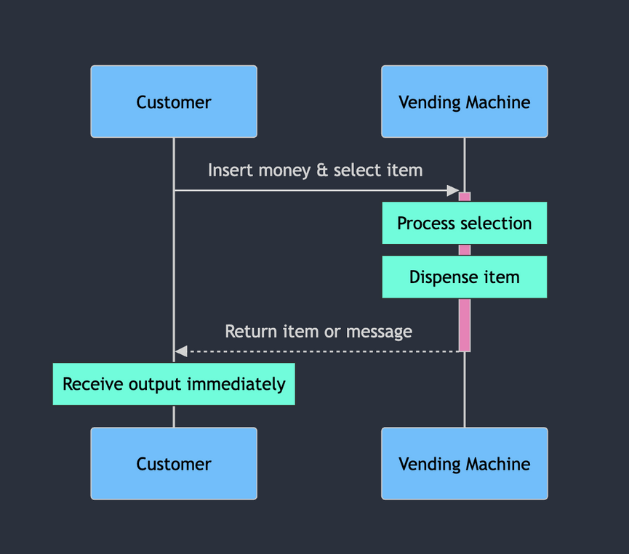
Functions: The Reliable Vending Machine
Think of a function as a vending machine:
- Input and output: You put money in (input) and get a snack out (output).
- Reusability: The machine can be used multiple times by different people.
- Self-contained: All the logic and items are contained within the machine.
- Immediate result: You get your snack right away after inputting money and making a selection.
Example in Python:
def vending_machine(money, selection):
items = {"A1": "Chips", "B2": "Chocolate", "C3": "Soda"}
if selection in items and money >= 1.50:
return f"Here's your {items[selection]}. Enjoy!"
else:
return "Invalid selection or insufficient funds."
result = vending_machine(2.00, "B2")
print(result) # Output: Here's your Chocolate. Enjoy!Use Case in Data Science
Functions are invaluable in data science projects for tasks like:
- Data Preprocessing: Create reusable functions for cleaning, normalizing, or encoding data.
- Feature Engineering: Develop functions to create new features or transform existing ones.
- Model Evaluation: Encapsulate complex evaluation metrics or cross-validation procedures.
Functions shine when you need to perform specific, repeatable tasks across your project, just like how a vending machine consistently delivers snacks on demand.
Generators: The Bookmarked Novel
Imagine a long novel that you’re reading slowly over time:
- On-demand progression: You only read one page at a time, moving forward as needed.
- State preservation: Your bookmark keeps track of where you left off, allowing you to resume easily.
- Memory efficiency: You don’t need to memorize the entire book, just the current page you’re reading.
- One-way traversal: Typically, you read forward, not backward through the pages.
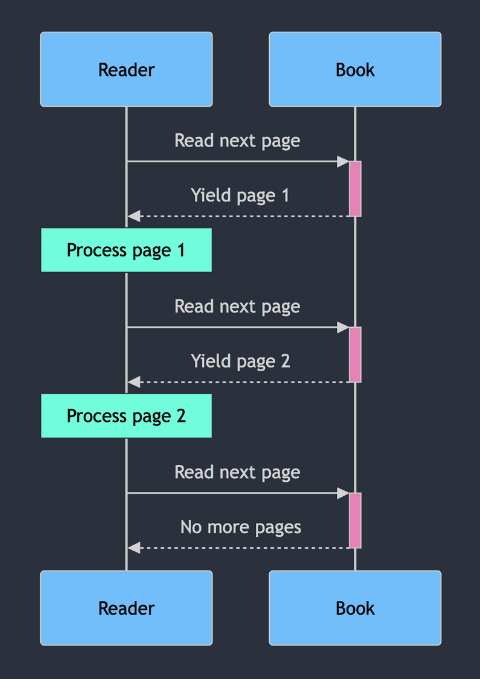
Example in Python:
def story_pages():
yield "Once upon a time..."
yield "There was a Python programmer..."
yield "Who loved to code all day..."
story = story_pages()
print(next(story)) # Output: Once upon a time...
print(next(story)) # Output: There was a Python programmer...Use Case in Data Science
Generators are useful when you need to work with large datasets or computationally expensive sequences.
Suppose you have a large CSV file containing millions of rows of data, and you want to process this data in chunks to avoid loading the entire dataset into memory at once. You can use a generator function with yield to read the data in smaller chunks and process it one chunk at a time.
import csv
def process_sales_data(file_path):
running_total = 0
with open(file_path, 'r') as file:
csv_reader = csv.DictReader(file)
for row in csv_reader:
# Extract date and sale amount from each row
date = row['Date']
sale_amount = float(row['Amount'])
# Update the running total
running_total += sale_amount
# Yield a dictionary with the processed data
yield {
'Date': date,
'Sale': sale_amount,
'RunningTotal': running_total
}
# Usage example
file_path = 'sales_data.csv'
# Process the data
for result in process_sales_data(file_path):
print(f"Date: {result['Date']}, "
f"Sale: ${result['Sale']:.2f}, "
f"Running Total: ${result['RunningTotal']:.2f}")
# The last result will contain the final total
final_result = result
print(f"\nTotal Sales: ${final_result['RunningTotal']:.2f}")Output:
Date: 2023-05-01, Sale: $100.50, Running Total: $100.50
Date: 2023-05-02, Sale: $75.25, Running Total: $175.75
Date: 2023-05-03, Sale: $200.00, Running Total: $375.75
Date: 2023-05-04, Sale: $50.75, Running Total: $426.50
Date: 2023-05-05, Sale: $150.00, Running Total: $576.50
Total Sales: $576.50Conclusion: Choosing the Right Tool
- Use functions when you need quick, repeatable operations on your data. They’re perfect for encapsulating logic that you’ll use multiple times throughout your project.
- Use generators when working with large datasets or streams of data. They allow you to process data incrementally, saving memory and enabling real-time analysis.