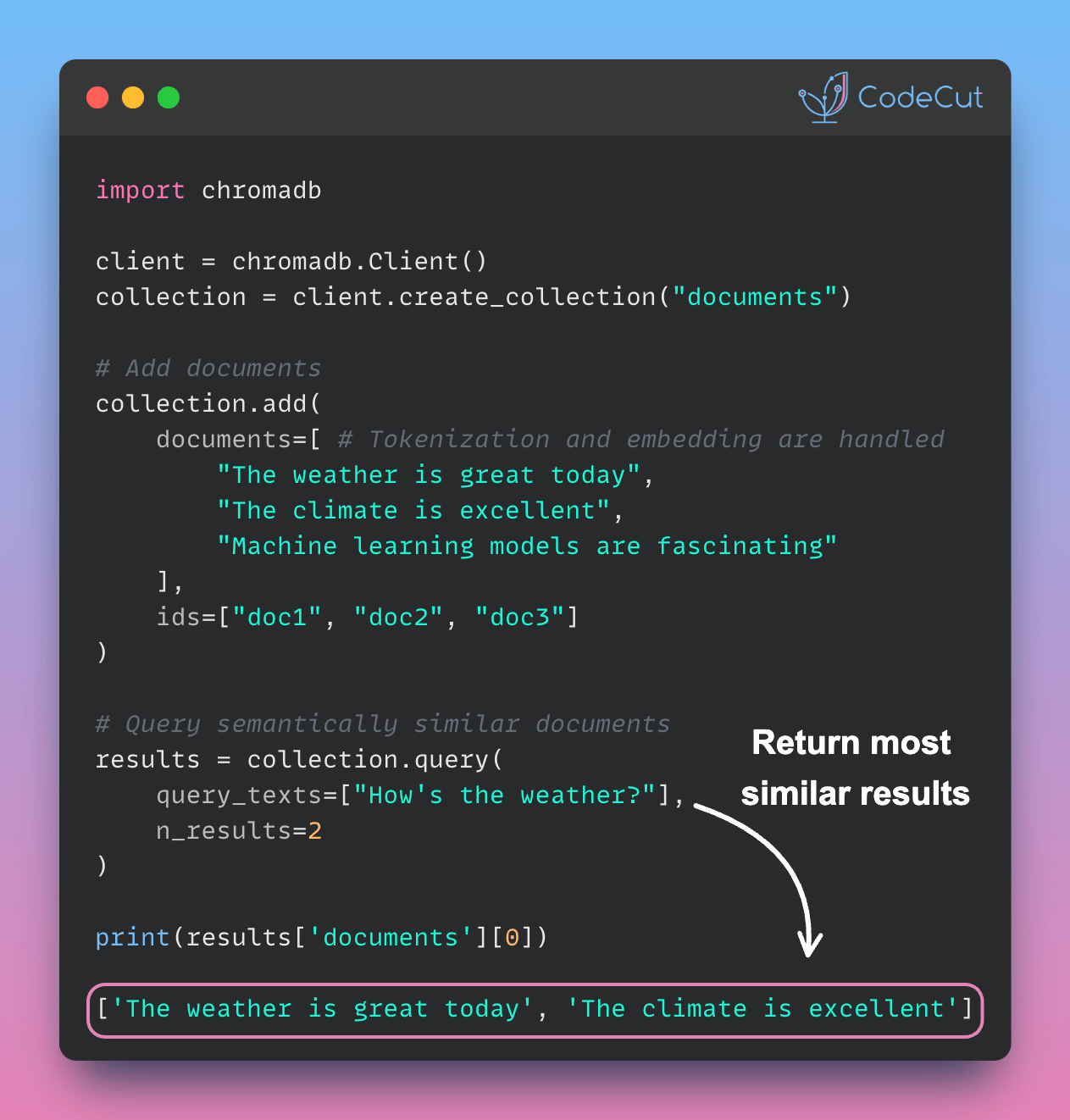

Writing and maintaining web scraping code requires constant updates due to changing HTML structures and complex selectors, which results in brittle code and frequent breakages.
With Parsera, you can scrape websites by simply describing what data you want to extract in plain language, letting LLMs handle the complexity of finding the right elements.
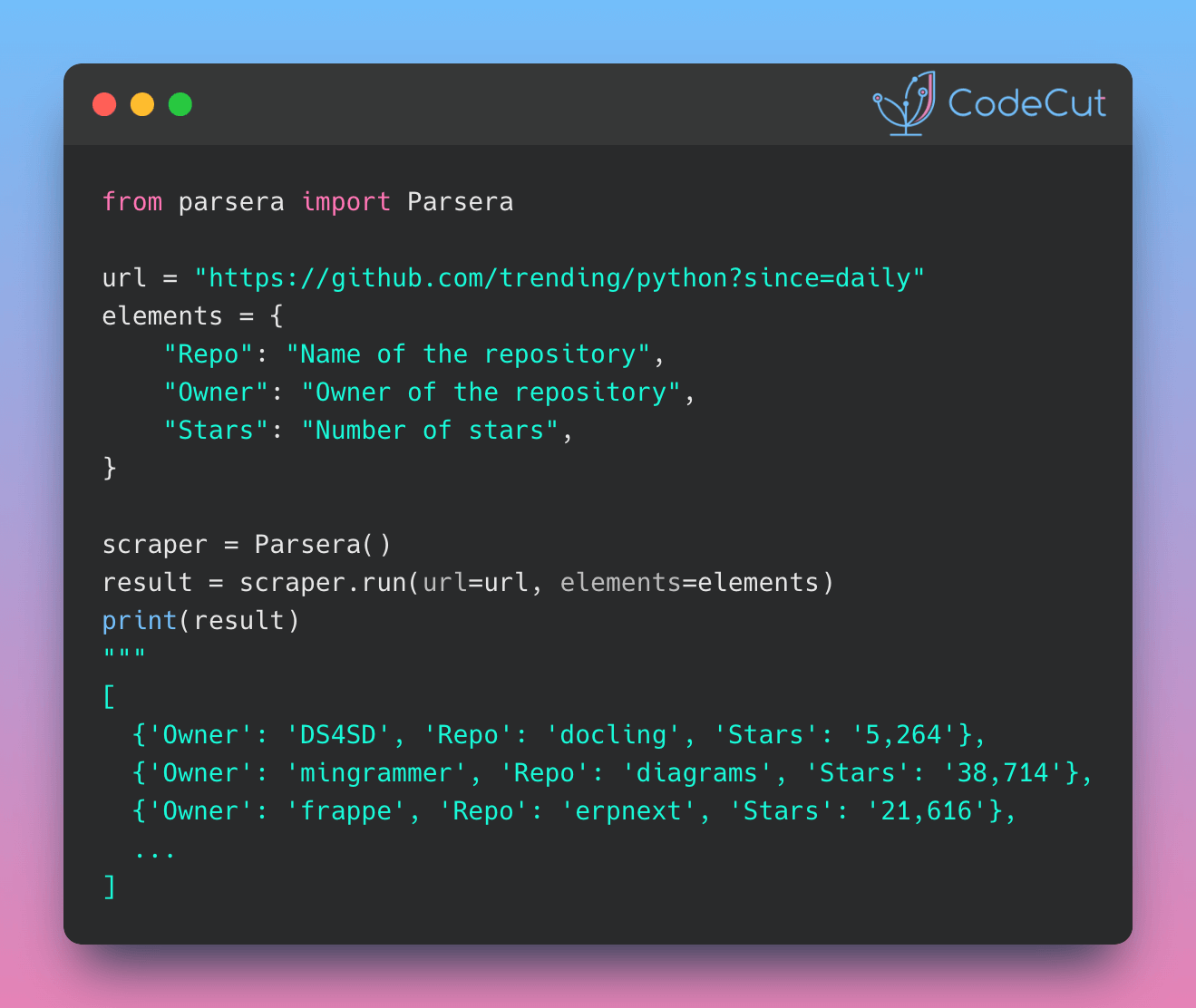
Here’s an example that scrapes GitHub’s trending Python repositories page to collect:
- Fork counts
- Repository names
- Repository owners
- Star counts
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY_HERE"from parsera import Parsera
from pprint import pprint
url = "https://github.com/trending/python?since=daily"
elements = {
"Repository": "Name of the repository",
"Owner": "Owner of the repository",
"Stars": "Number of stars",
"Forks": "Number of forks",
}
scraper = Parsera()
result = scraper.run(url=url, elements=elements)
pprint(result)[{'Forks': '272', 'Owner': 'DS4SD', 'Repository': 'docling', 'Stars': '5,264'},
{'Forks': '2,502',
'Owner': 'mingrammer',
'Repository': 'diagrams',
'Stars': '38,714'},
{'Forks': '3,883',
'Owner': 'All-Hands-AI',
'Repository': 'OpenHands',
'Stars': '34,095'},
{'Forks': '7,288',
'Owner': 'frappe',
'Repository': 'erpnext',
'Stars': '21,616'},
{'Forks': '7,249',
'Owner': 'abi',
'Repository': 'screenshot-to-code',
'Stars': '58,574'},
{'Forks': '46,154',
'Owner': 'donnemartin',
'Repository': 'system-design-primer',
'Stars': '274,420'},
...
]