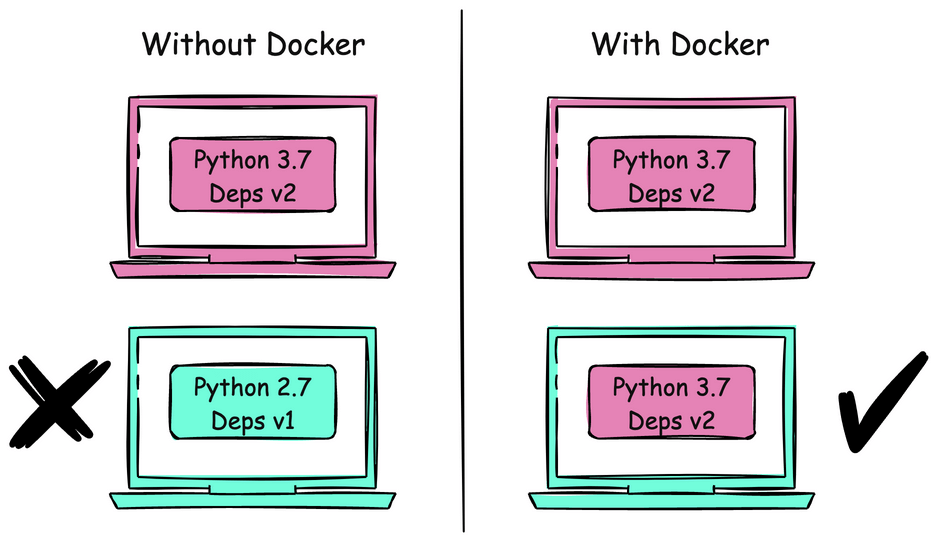
Motivation
Reproducible environments are crucial for modern software development and data science projects. Ensuring that code runs consistently across different machines and maintaining identical development environments among team members is essential for collaboration and deployment.
When working on data science projects, team members often face difficulties when code that works perfectly on one machine fails on another due to different versions of libraries or system dependencies.
import pandas as pd
# On Machine 1 (Python 3.8)
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]
})
# Using walrus operator for efficient filtering and analysis
if (filtered := df[df['A'] > 2]).shape[0] > 0:
print(f"Found {filtered.shape[0]} rows where A > 2")
# On Machine 2 (Python 3.7)
# SyntaxError: invalid syntax
# The walrus operator ':=' was introduced in Python 3.8This example demonstrates how different Python versions or package versions can lead to inconsistent behavior across different environments, causing frustration and delays in collaborative projects.
Introduction to Docker
Docker is a platform that enables developers to package applications and their dependencies into lightweight, portable containers. These containers include everything needed to run the application: code, runtime, system tools, libraries, and settings.
Docker can be installed by downloading the Docker Desktop application from the official website.
Environment Sharing with Docker
Docker solves environment inconsistencies by creating isolated containers that package all dependencies and can be shared across team members.
Setting up a data science environment with Docker:
Create a Dockerfile:
FROM python:3.8-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY script.py .
CMD ["python", "script.py"]Create requirements.txt:
pandas==1.5.3Create script.py with the Python 3.8 features:
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]
})
if (filtered := df[df['A'] > 2]).shape[0] > 0:
print(f"Found {filtered.shape[0]} rows where A > 2")Build and run the Docker container:
# Build the Docker image
docker build -t python38-analysis .
# Run the container
docker run python38-analysisOutput:
Found 3 rows where A > 2Let’s break down these commands:
docker build -t python38-analysis .:
docker build: Command to create a Docker image from a Dockerfile-t python38-analysis: Tags the image with the name “python38-analysis” for easy reference.: Specifies the build context (current directory containing Dockerfile)
docker run python38-analysis:
docker run: Creates and starts a new container from the imagepython38-analysis: The name of the image to run
Share the environment through Docker Hub:
# Log in to Docker Hub
docker login
# Tag the image with your Docker Hub username
docker tag python38-analysis username/python38-analysis:latest
# Push the image to Docker Hub
docker push username/python38-analysis:latestTeam members can then use the environment:
# Pull the image
docker pull username/python38-analysis:latest
# Run the container
docker run username/python38-analysis:latestOutput:
Found 3 rows where A > 2Conclusion
Docker provides a robust solution for sharing development environments across team members and ensuring consistent behavior across different machines. By containerizing your data science project and sharing it through Docker Hub, you can:
- Eliminate “it works on my machine” problems
- Maintain version control for your development environment
- Enable easy onboarding of new team members
- Facilitate seamless deployment to production