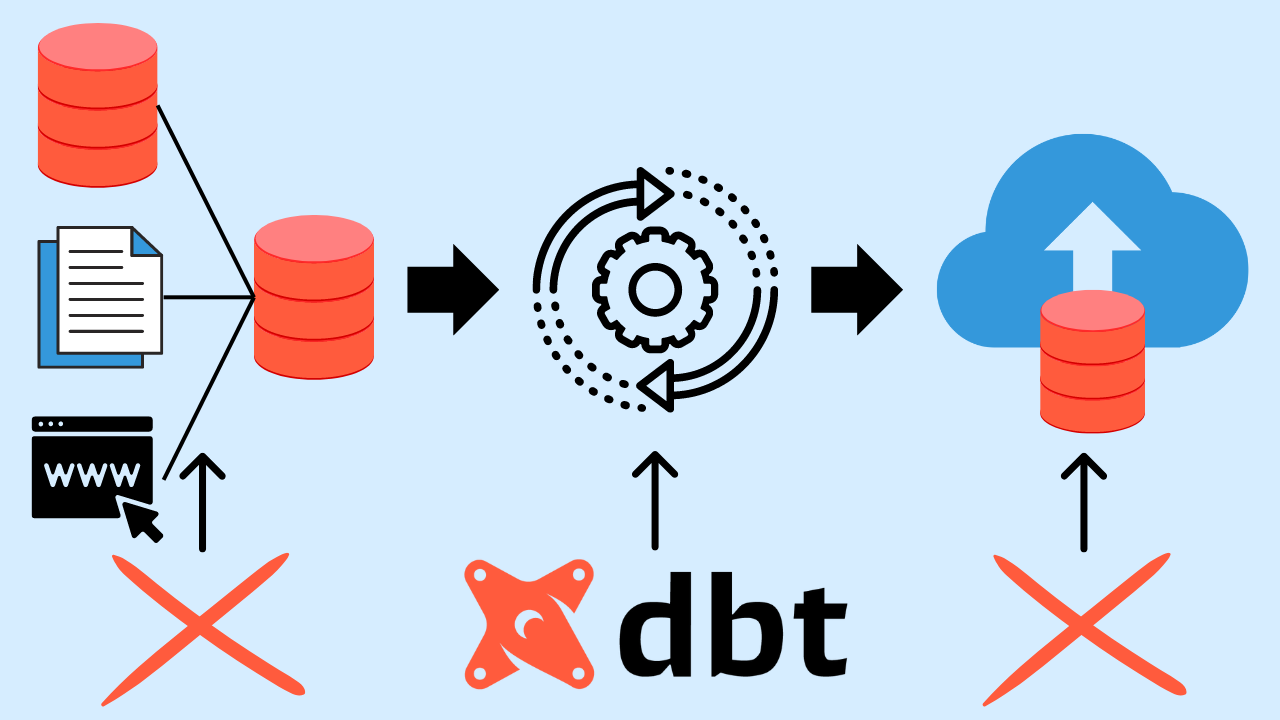
Motivation
If your organization is looking to create a data-driven product, you should consider having efficient data pipelines to:
- Stay competitive: Quick access to data and its analysis through efficient data pipelines accelerates decision-making and keeps you ahead of your competition.
- Reduce costs: The time and effort required to collect and transform data can be significantly reduced with efficient data pipelines, which can reduce costs and enable employees to focus on higher-level tasks that require human intelligence.
One tool that has gained popularity in recent years for managing data pipelines is dbt (data build tool).
While dbt can provide significant benefits for managing and modeling data, it may not be the best tool for every situation. In this article, we’ll explore the use cases of dbt to determine whether dbt is a good fit for your organization.
Feel free to play and fork the source code of this article here.
What is dbt?
dbt is an open-source tool for transforming data in a data warehouse. With dbt, users can write SQL queries that transform data and create repeatable workflows that can be easily tested and automated.
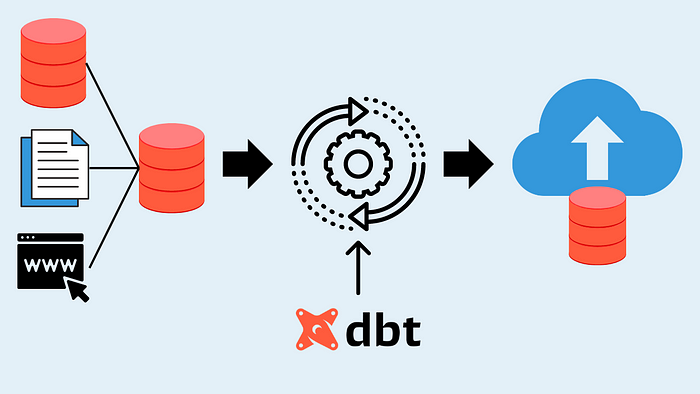
When Should You Consider dbt
You should consider using dbt when:
- You have a data warehouse: dbt is an effective tool for organizing, transforming, and testing data in a data warehouse environment.
- Your data pipeline is complex: dbt’s modular approach can help break down complex pipelines into smaller pieces, making it easier to debug, test, and make changes to your pipeline.
- Your data changes frequently: dbt’s snapshot allows you to track changes in data over time.
- Transparency is essential to your organization: dbt can automatically generate documentation for your pipeline. It also provides insights into the data transformation process through data lineage.
- Data quality is essential to your organization: dbt can test your models to help you catch errors early and ensure that your data is accurate.
Before diving into some helpful features of dbt, we need to first set up the dbt environment. This will allow you to easily follow along with the discussion.
Setup dbt
Install dbt
This article uses BigQuery as a data warehouse for dbt, to install dbt’s adapter for BigQuery, type:
pip install dbt-bigqueryFollow this instruction if you want to use other dbt’s adapters.
Create a project
To initialize a dbt project called dbt_demo, type the following:
dbt init dbt_demoThe following is the project directory.

Modularity
dbt’s modular approach allows you to break down a complex pipeline into smaller pieces.
To demonstrate this, we will use the austin_bikeshare dataset from BigQuery public datasets.
Create a new SQL file in the models directory, named models/trips_per_property.sql with the following code:
WITH stations AS (
SELECT
station_id, council_district,
CASE
WHEN property_type IN ('parkland', 'sidewalk', 'nonmetered_parking') THEN 'free_parking'
ELSE property_type
END AS property_type,
FROM
`bigquery-public-data.austin_bikeshare.bikeshare_stations`
WHERE
property_type IN (
'parkland',
'sidewalk',
'nonmetered_parking',
'paid_parking'
)
),
trips AS (
SELECT
start_station_id
FROM
`bigquery-public-data.austin_bikeshare.bikeshare_trips`
WHERE
start_station_id is NOT NULL
)
SELECT
stations.property_type,
COUNT(*) AS trips,
FROM
trips
JOIN stations ON trips.start_station_id = stations.station_id
GROUP BY
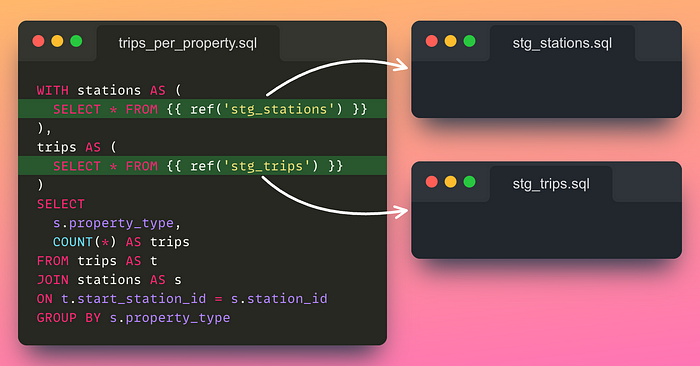
stations.property_typeSince this model contains multiple data transformations, it can be difficult to maintain and test.
We could separate the model into different models by doing the following:
- Create two files
stg_stations.sqlandstg_trips.sqlunder themodelsdirectory. - Replace the existing
stationsCTE andtripsCTE with the following SQL code:
- In the
stg_trips.sqlfile, write the SQL code from thetripsCTE in the original model.
-- models/stg_trips.sql
SELECT start_station_id
FROM `bigquery-public-data.austin_bikeshare.bikeshare_trips`
WHERE start_station_id is NOT NULL- In the
stg_stations.sqlfile, write the SQL code from thestationsCTE in the original model.
-- models/stg_stations.sql
SELECT
station_id, council_district,
CASE
WHEN property_type IN ('parkland', 'sidewalk', 'nonmetered_parking') THEN 'free_parking'
ELSE property_type
END AS property_type,
FROM
`bigquery-public-data.austin_bikeshare.bikeshare_stations`
WHERE
property_type IN ('parkland', 'sidewalk', 'nonmetered_parking', 'paid_parking')By breaking down the model into multiple models, you can now reuse the data models in other models:
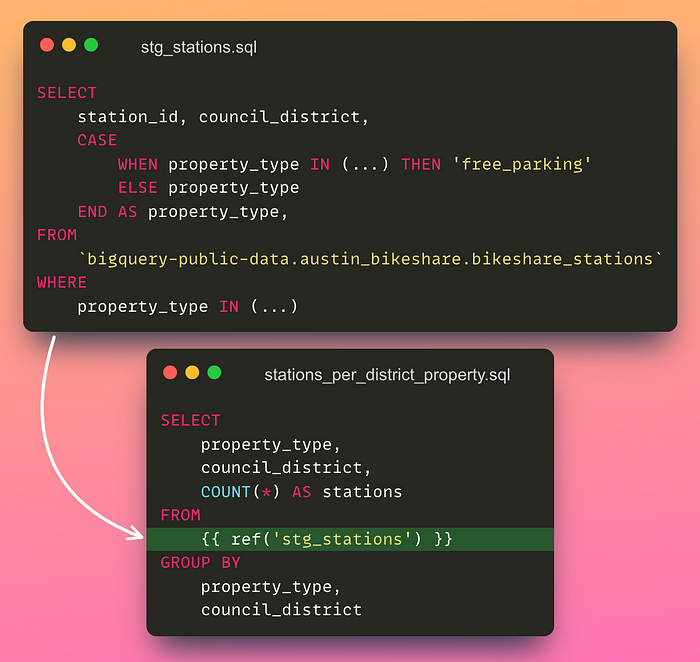
Your team members can also work on the different parts of the project simultaneously.
Because each module is self-contained, it can be easily tested and validated.
Code Reusability
Using macros in dbt simplifies the process of reusing SQL code fragments across various models.
To demonstrate, we will create a macro called get_end_time in the macros/get_end_time.sql file. This micro gets an end time based on a start time and duration.
# macros/get_end_time.sql
{% macro get_end_time(start_time, duration_minutes) %}
(SELECT TIMESTAMP_ADD({{ start_time }}, INTERVAL {{ duration_minutes }} MINUTE) AS end_time)
{% endmacro %}Think of the get_end_time macro as a Python function that can be used repeatedly to generate a value based on the inputs provided.

Another model can now use this micro with specific values for start_time and duration_minutes:
SELECT
start_station_id,
start_time,
end_station_id,
{{ get_end_time('start_time', 'duration_minutes') }} AS end_time
FROM
`bigquery-public-data.austin_bikeshare.bikeshare_trips`
WHERE
start_station_id IS NOT NULL AND end_station_id IS NOT NULL Testing
With dbt, you can easily verify the correctness of your models. For instance, to ensure the stg_stations model is correct, you may want to check that:
- The
station_idcolumn is non-null and has unique values. - The
property_typecolumn only has the values ‘free_parking’ or ‘paid_parking’.
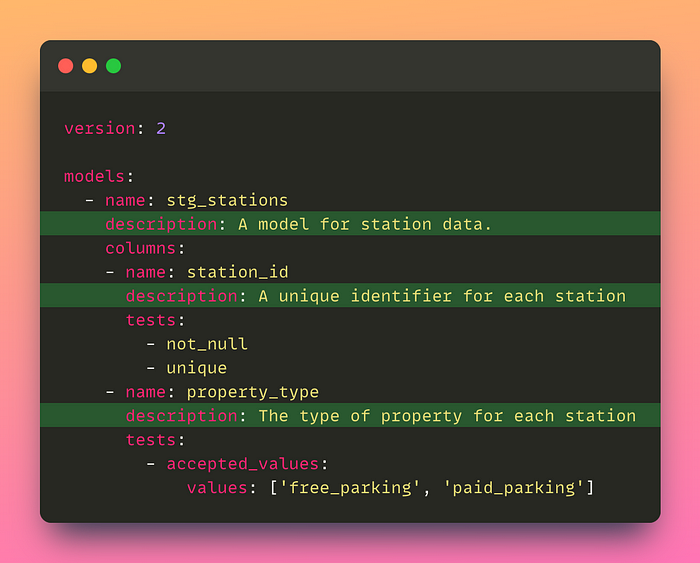
To test the stg_stations model, create a new YAML file in the models directory, named models/schema.yml with the following content.
version: 2
models:
- name: stg_stations
columns:
- name: station_id
tests:
# Should not contain null values.
- not_null
# Should be unique
- unique
- name: property_type
tests:
# Should be either 'free_parking' or 'paid_parking'.
- accepted_values:
values: ['free_parking', 'paid_parking']Then run dbt test to run all of the tests.
By catching potential errors early in the transformation process, tests can reduce the risk of errors in downstream applications and analyses.
In addition, tests provide a way to track changes in the data over time and to ensure that the transformation logic remains correct as the underlying data changes.
Documentation
With dbt, you can easily document your models and share the documentation with your team.
To create documentation for your models, follow these steps:
- Add descriptions to your
models/schema.ymlfile.
- Run
dbt docs generateto generate the documentation for your project. - Run
dbt docs servecommand to launch the documentation. - Access the documentation by navigating to http://localhost:8080 in your web browser.
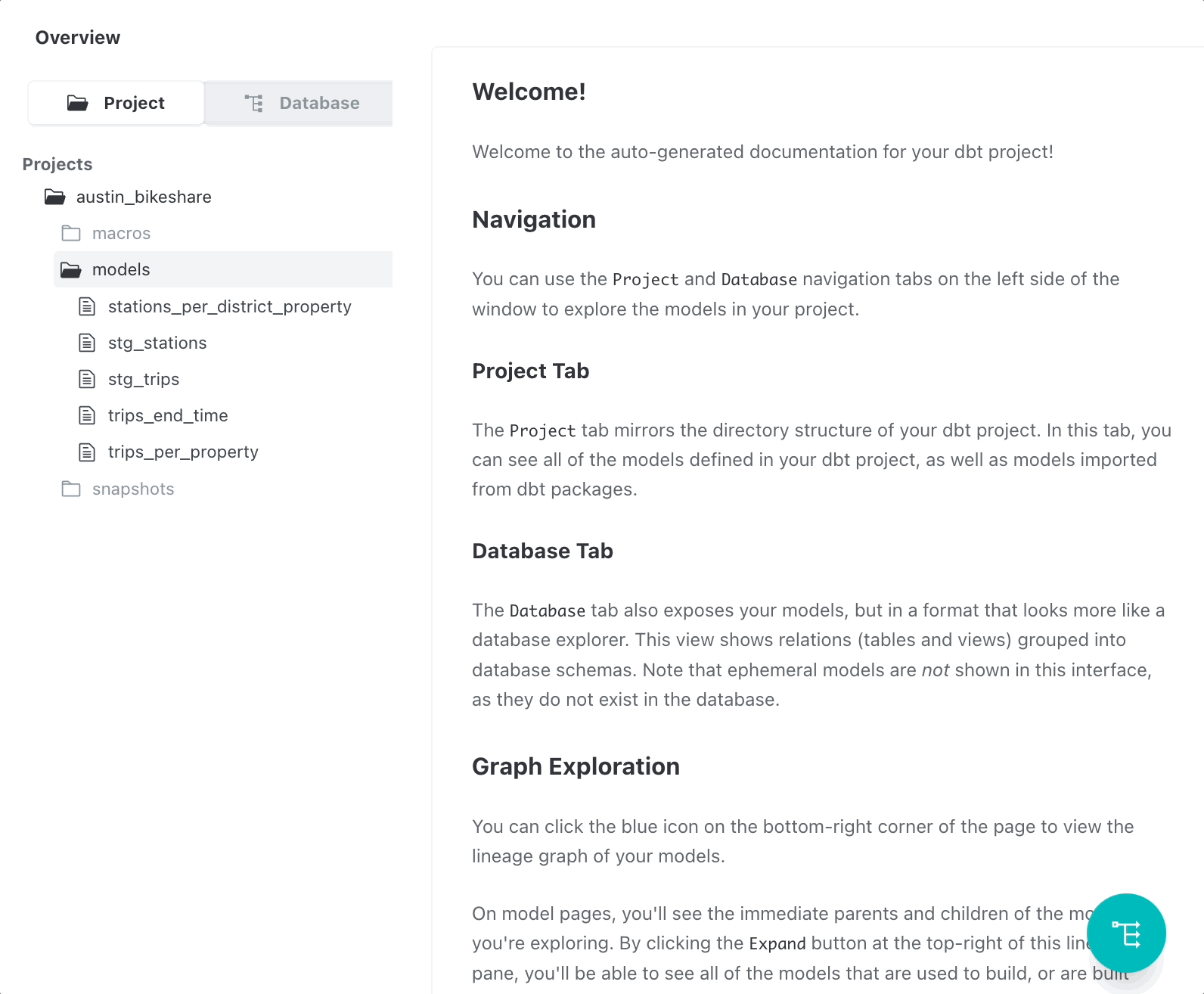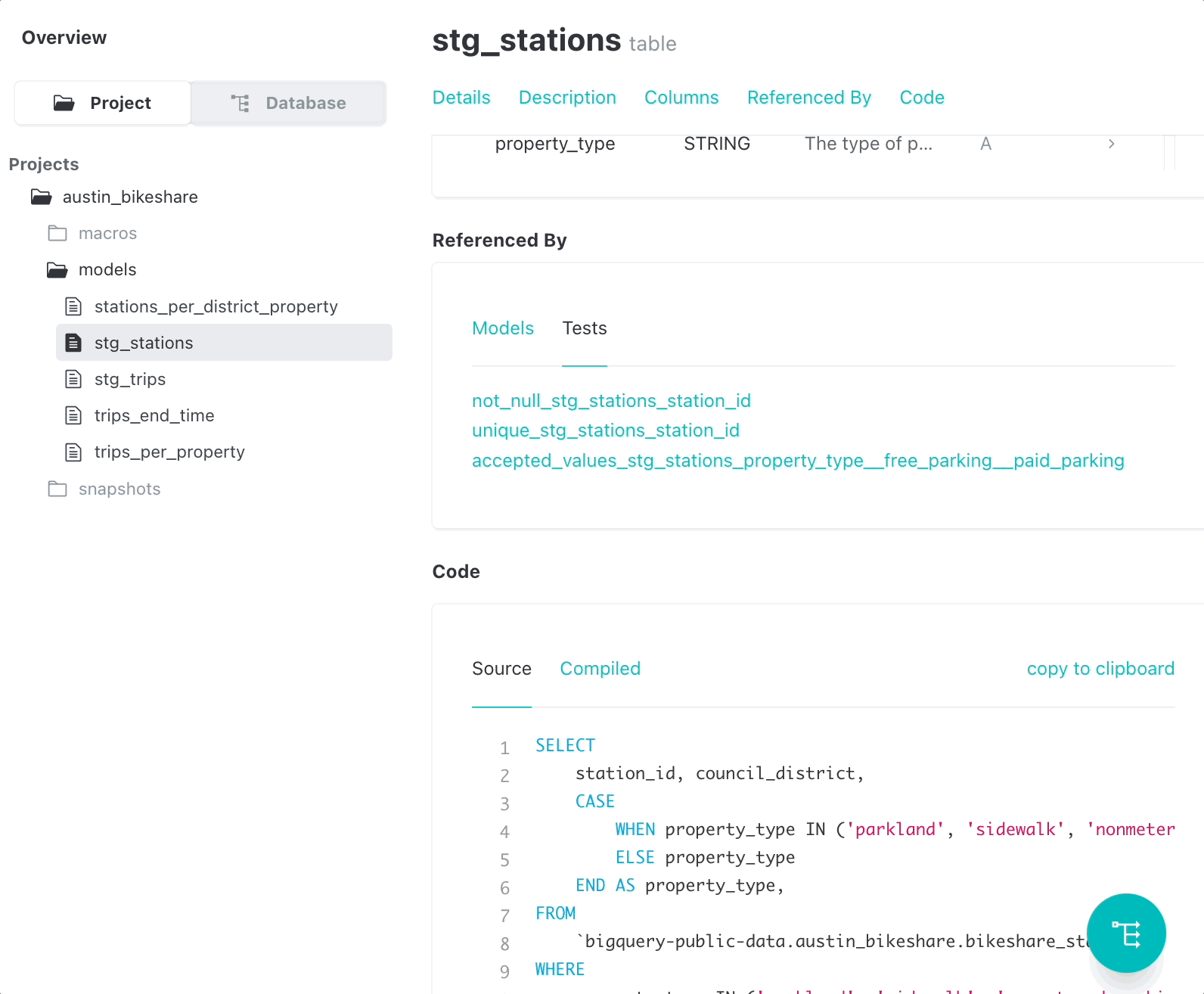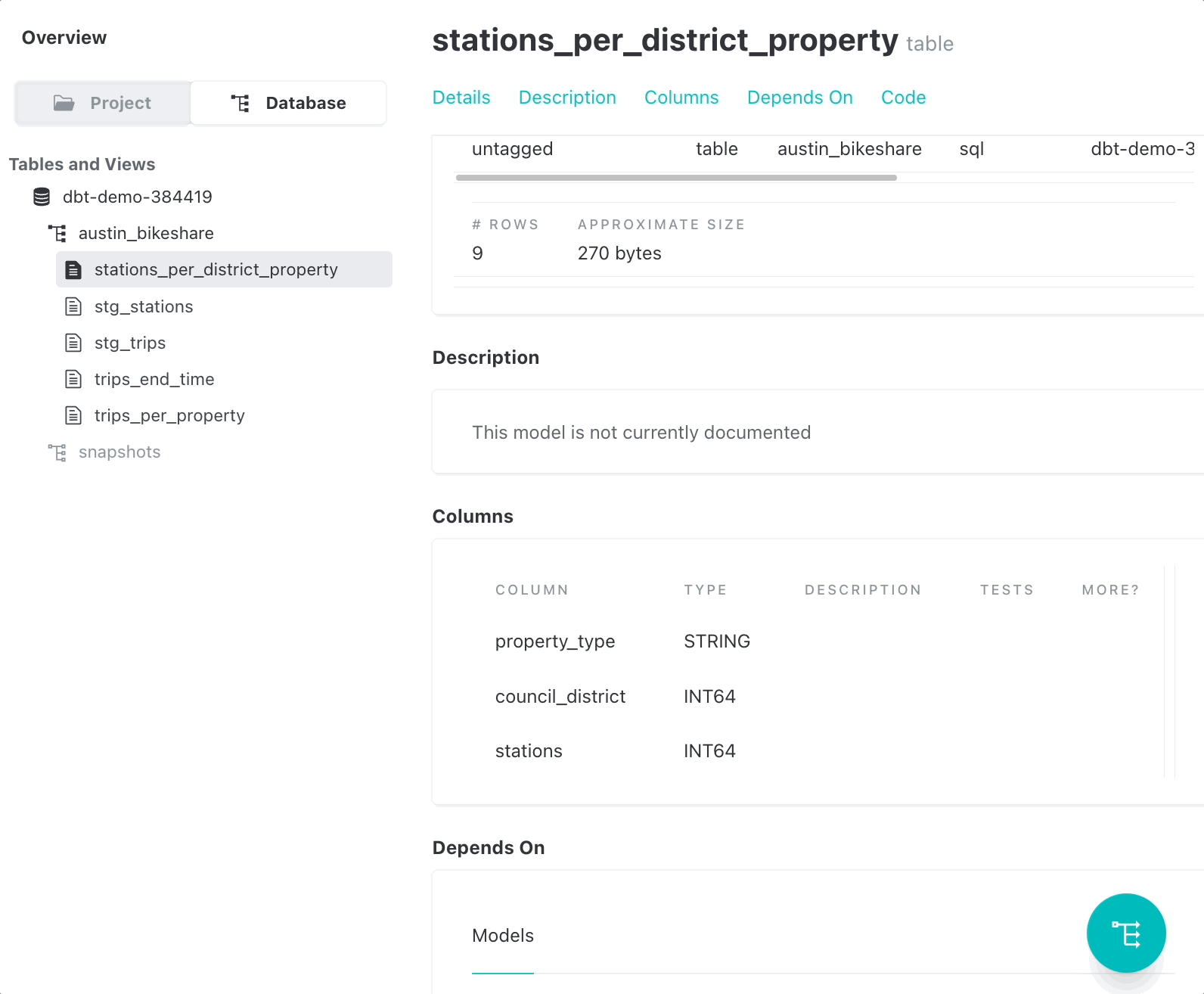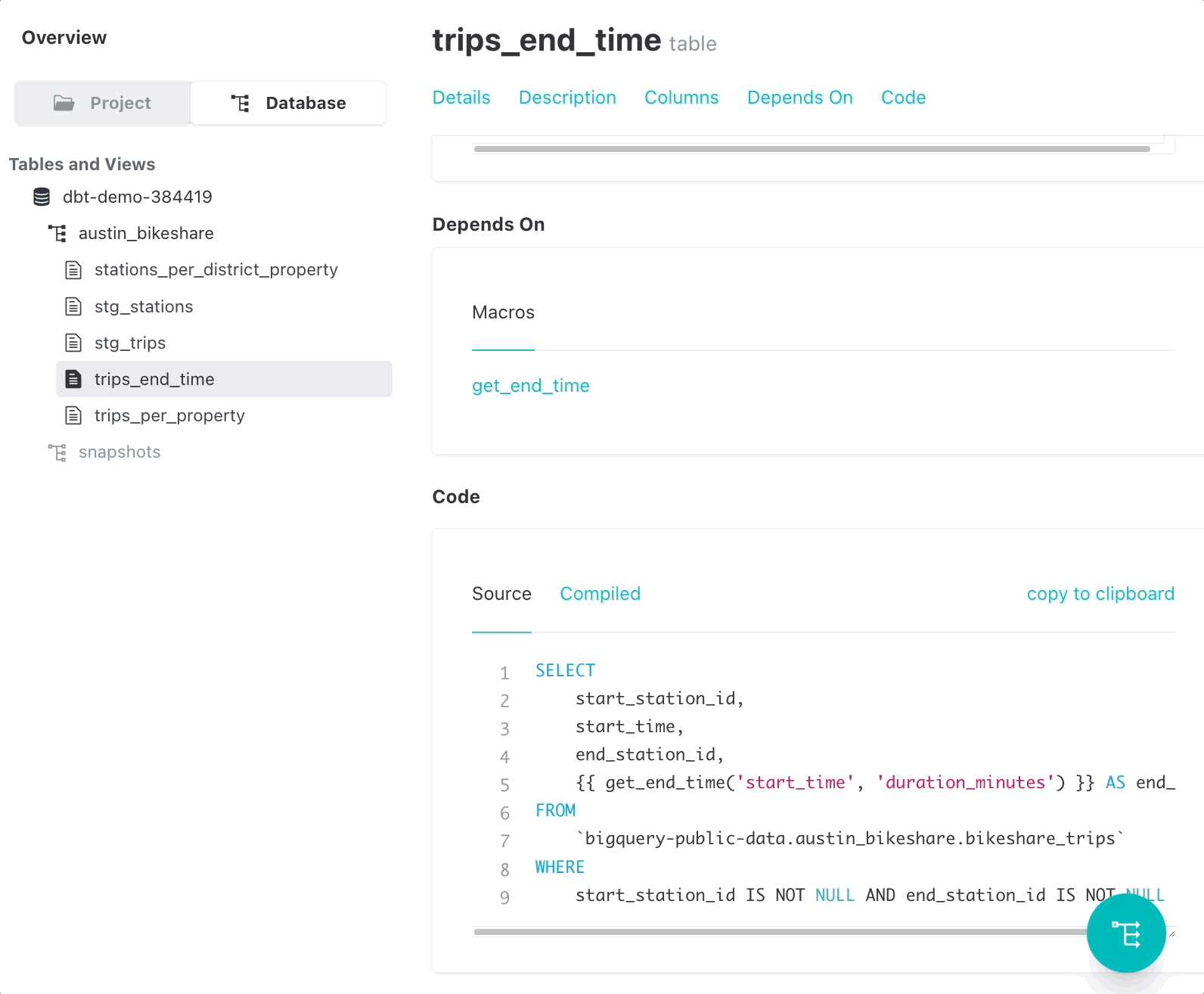
Documenting your data models helps to ensure that everyone who works with the models can comprehend their functionality and purpose.
You can also examine data lineage in the documentation by clicking “View lineage graph.”
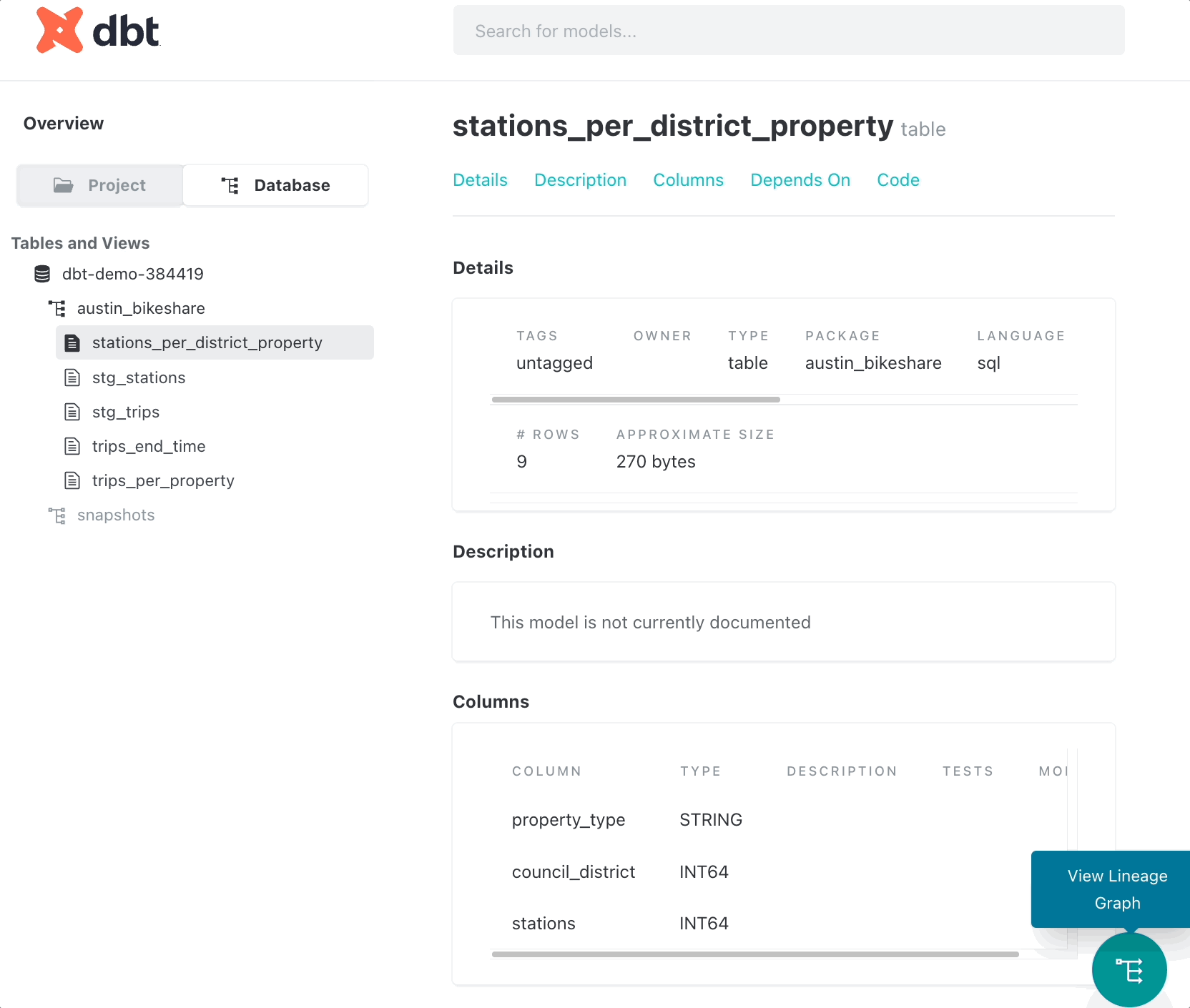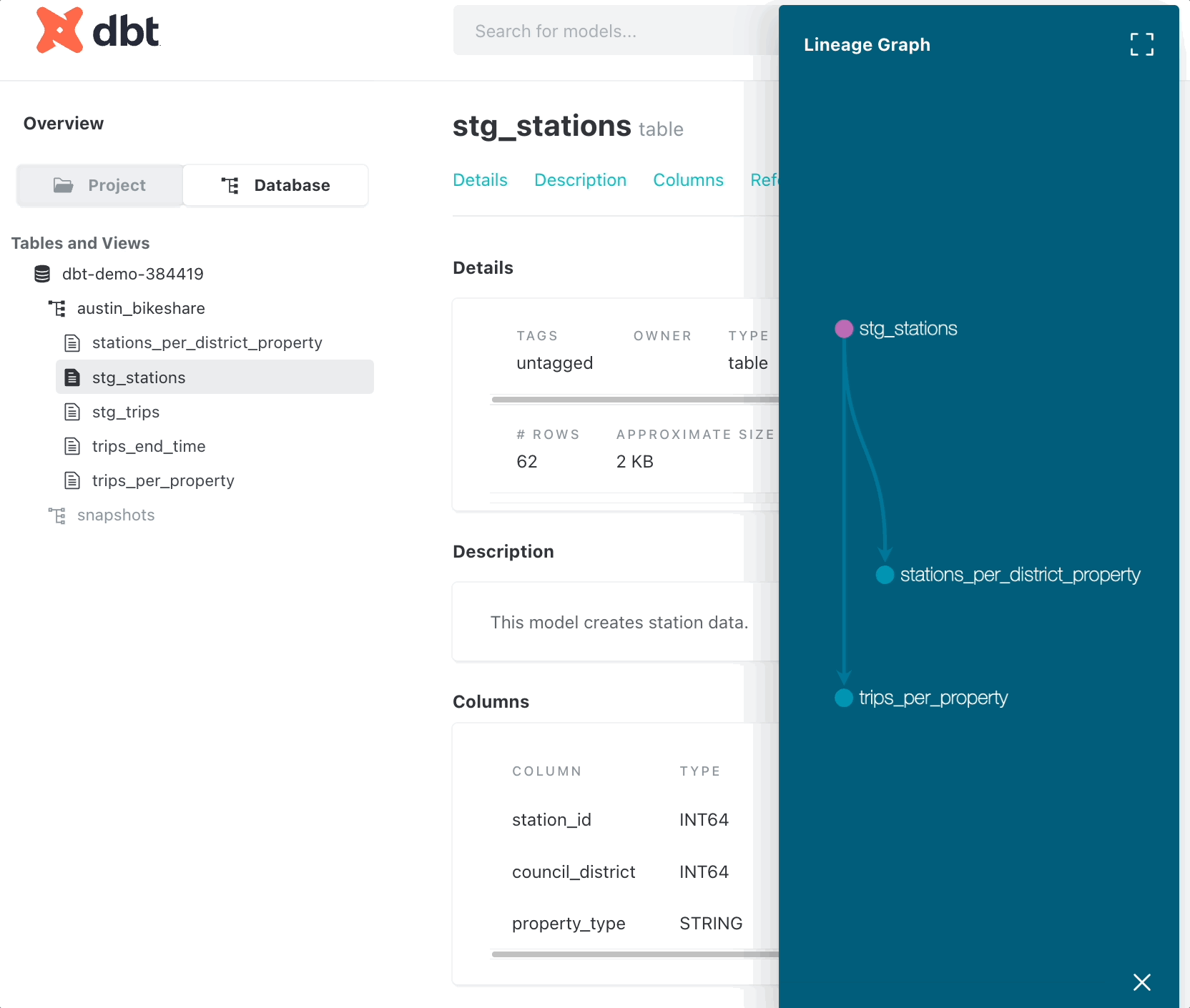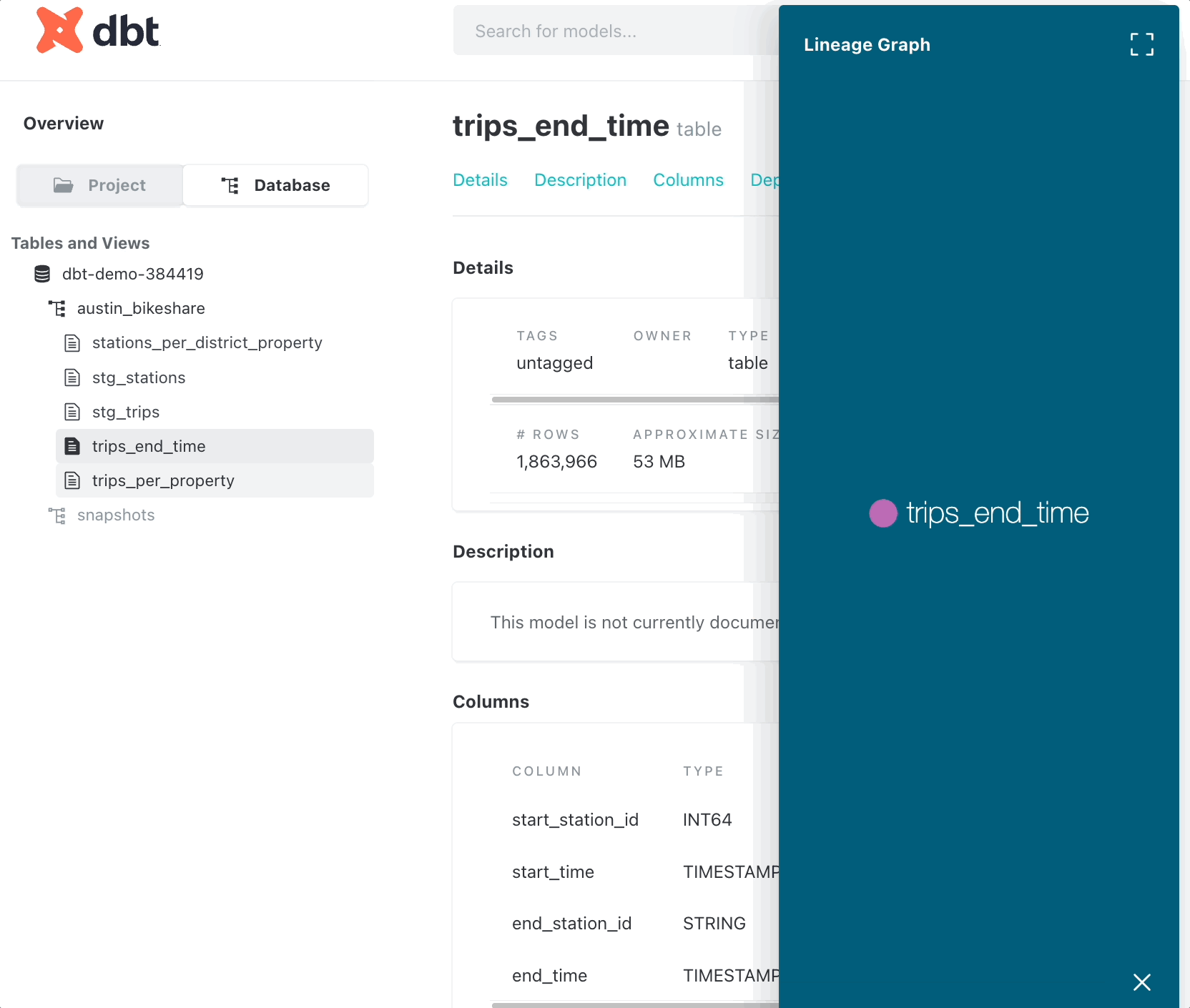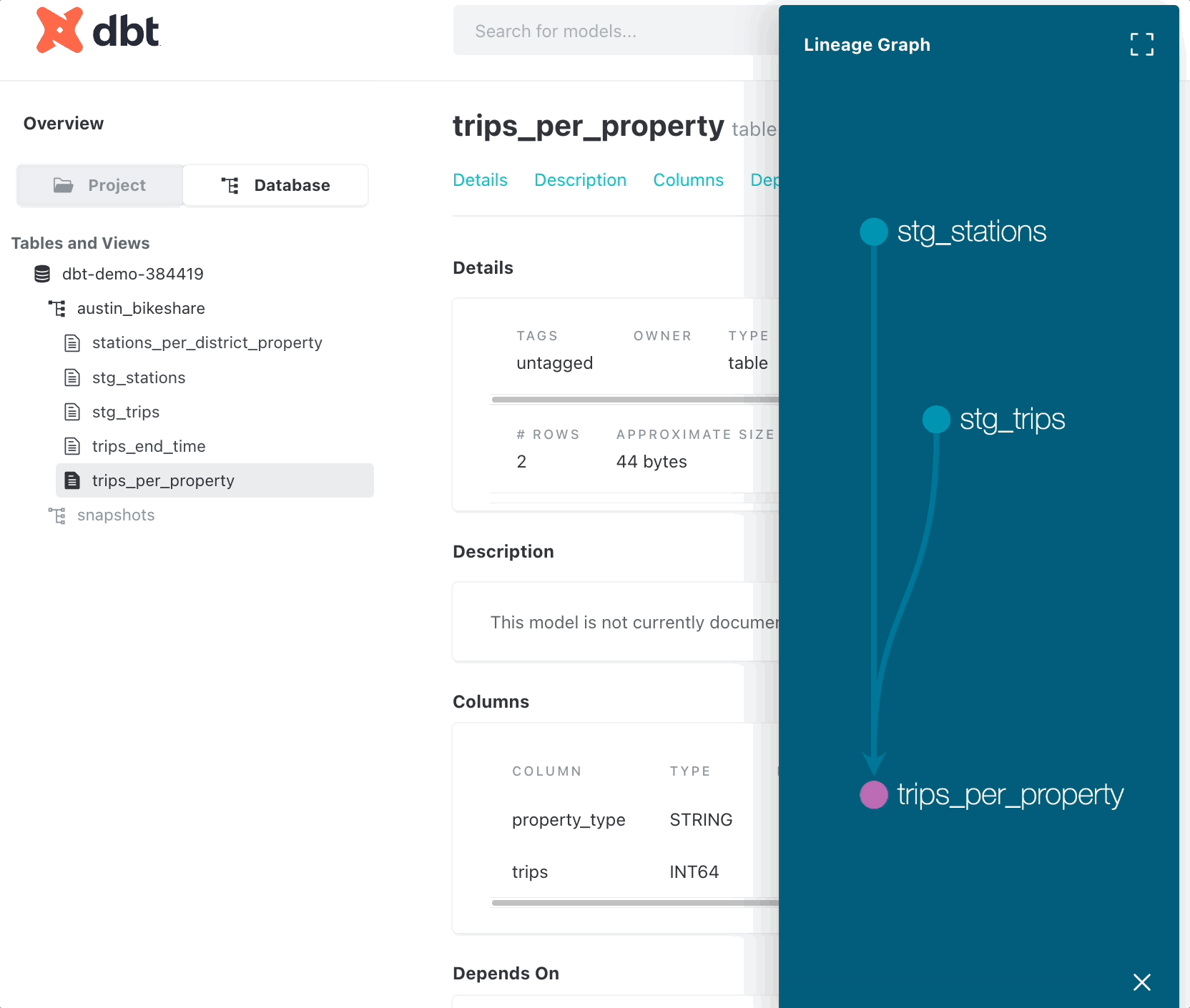
Track changes in data
With dbt, you can track data changes over time through snapshots.
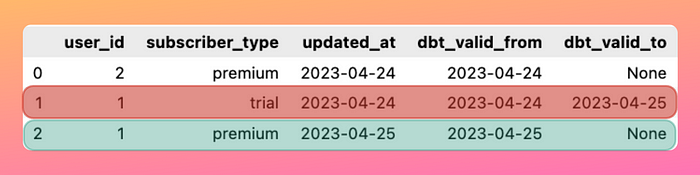
To see why this is useful, imagine you have a subscriber_type table where the subscriber_type field is frequently overwritten as subscribers modify their membership status.
If a user changes their membership from “trial” to “premium”, the record of when the user had the “trial” membership will be lost.
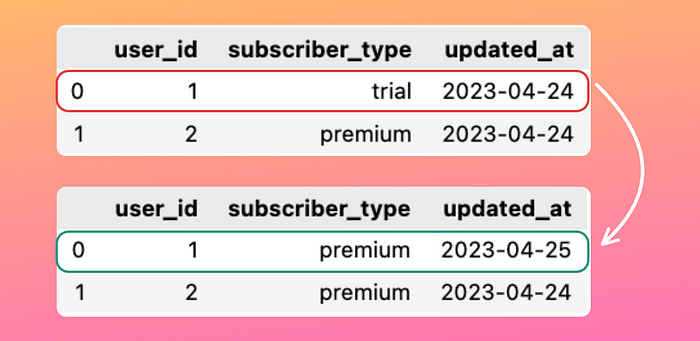
Losing this record can be problematic if we want to use it for other evaluations such as calculating the average time taken by a user to change their subscription.
dbt can snapshot these changes to help you understand how values in a row change over time. Here’s an example of a snapshot table for the previous example:
When You Should Not Use dbt
While dbt can provide significant benefits for managing and modeling data, you should not use dbt when:
- You don’t have a data warehouse: dbt is designed to work specifically with data warehouses, such as Snowflake, Redshift, or BigQuery. If you don’t have a data warehouse, then dbt may not be the right tool for you.
- You want a one-stop shop for ETL: While dbt is an excellent tool for transforming data, it does not offer a complete end-to-end solution for ETL (Extract, Transform, Load) tasks. Other tools are needed for tasks such as data extraction, data cleansing, and data loading.
- You want to visualize your data: dbt is not a data visualization tool. If you want to create visualizations, you will need to use a separate tool or library such as Tableau, Looker, or PowerBI.
- You want advanced feature engineering beyond the limitations of SQL grammar: As SQL is dbt’s primary language, there are some limitations when it comes to feature engineering. If you need to perform advanced feature engineering tasks that go beyond the capabilities of SQL, you may need to use other tools or languages such as Python or R.

Conclusion
In this article, we cover some helpful features of dbt and learn when to and not to use dbt. I hope this article gives you the knowledge needed to decide whether dbt is the right solution for your data pipelines.