Motivation
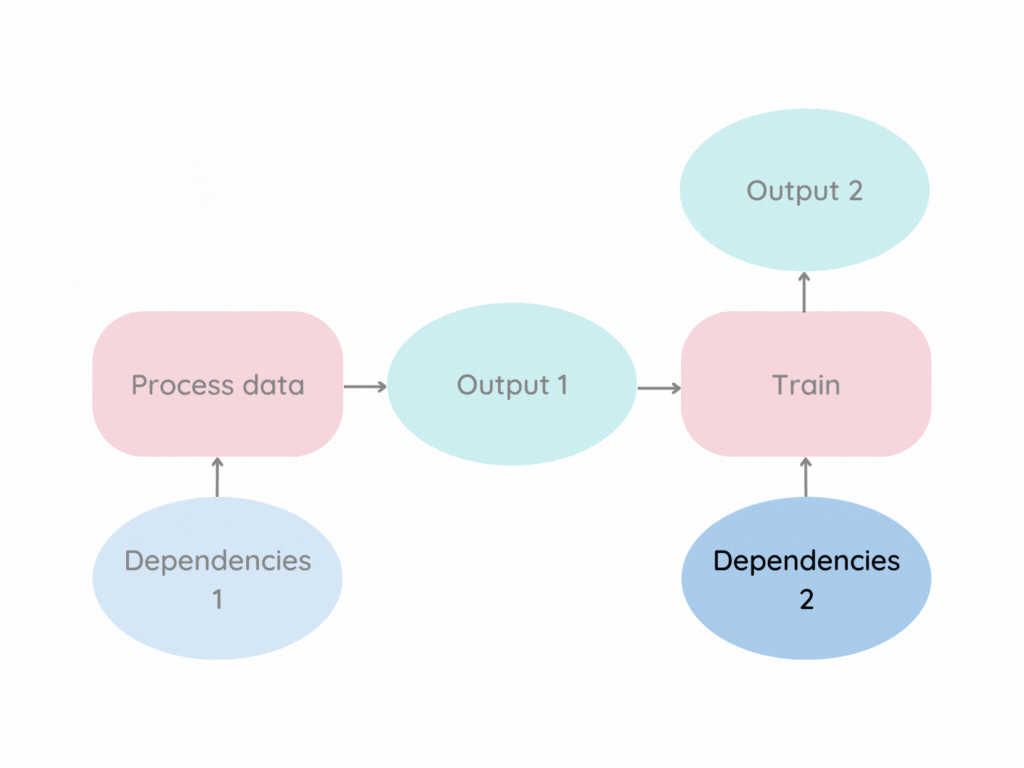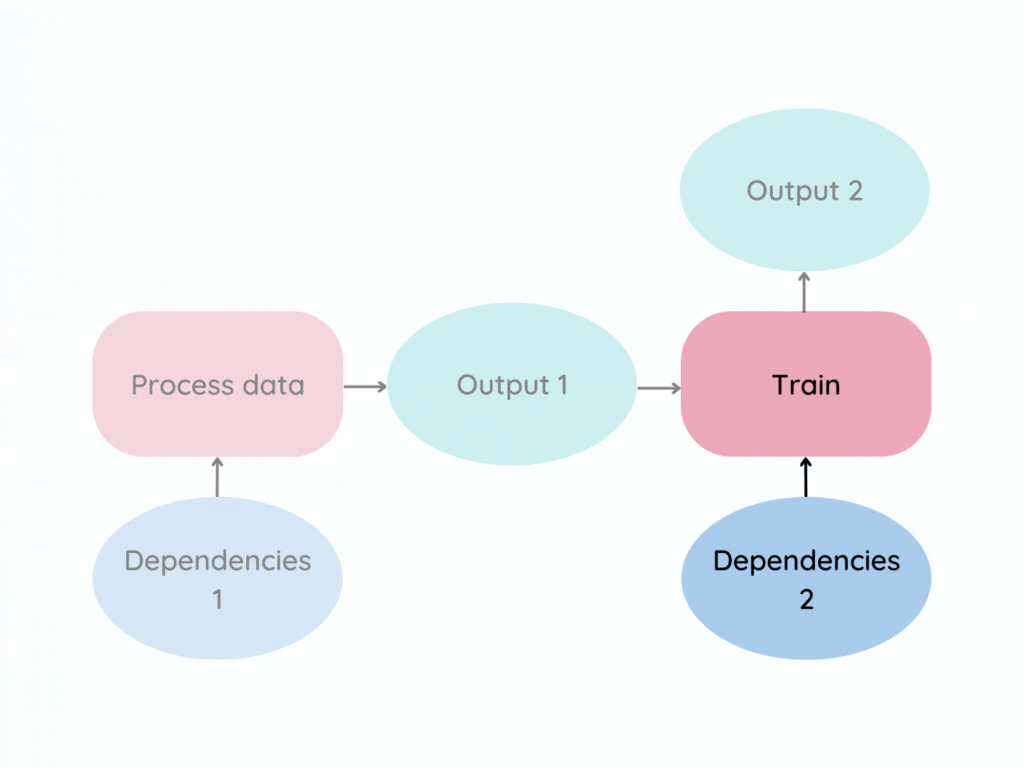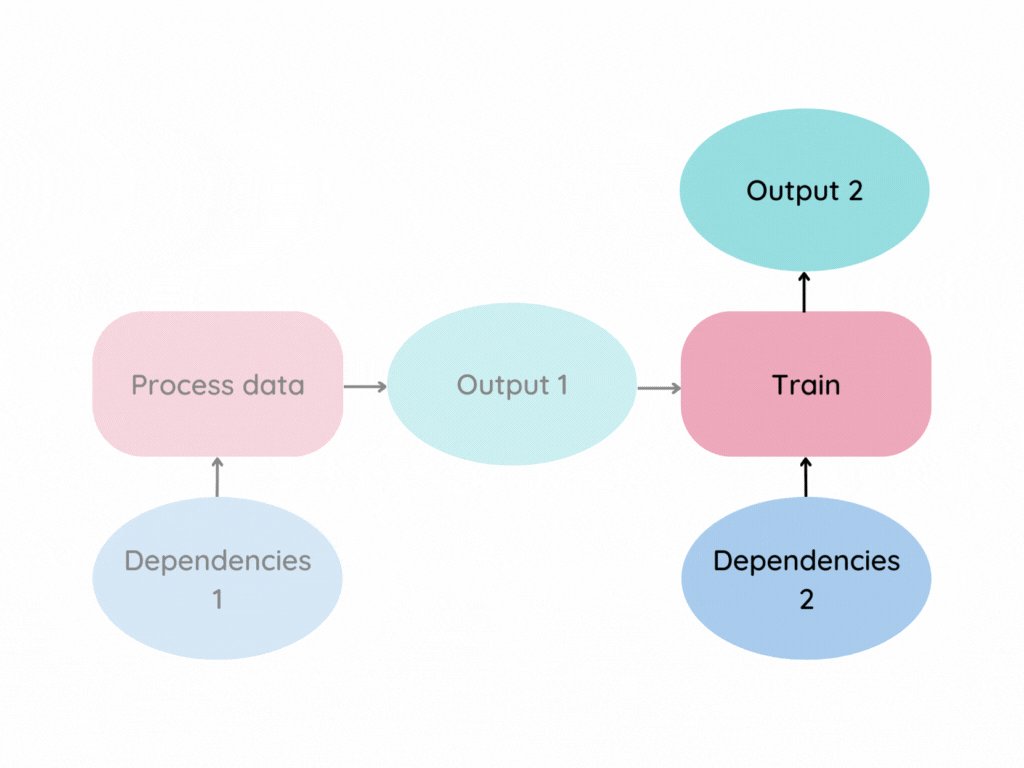
Imagine your data pipeline looks similar to the graph below.

The pink box represents a stage, which is an individual data process. Dependencies are the files that a stage depends on, such as parameters, Python scripts, or input data.
Now imagine Dependencies 2 changes. The standard approach is to rerun the entire pipeline.

This approach works but is inefficient. Wouldn’t it be better to run only the stages whose dependencies changed?
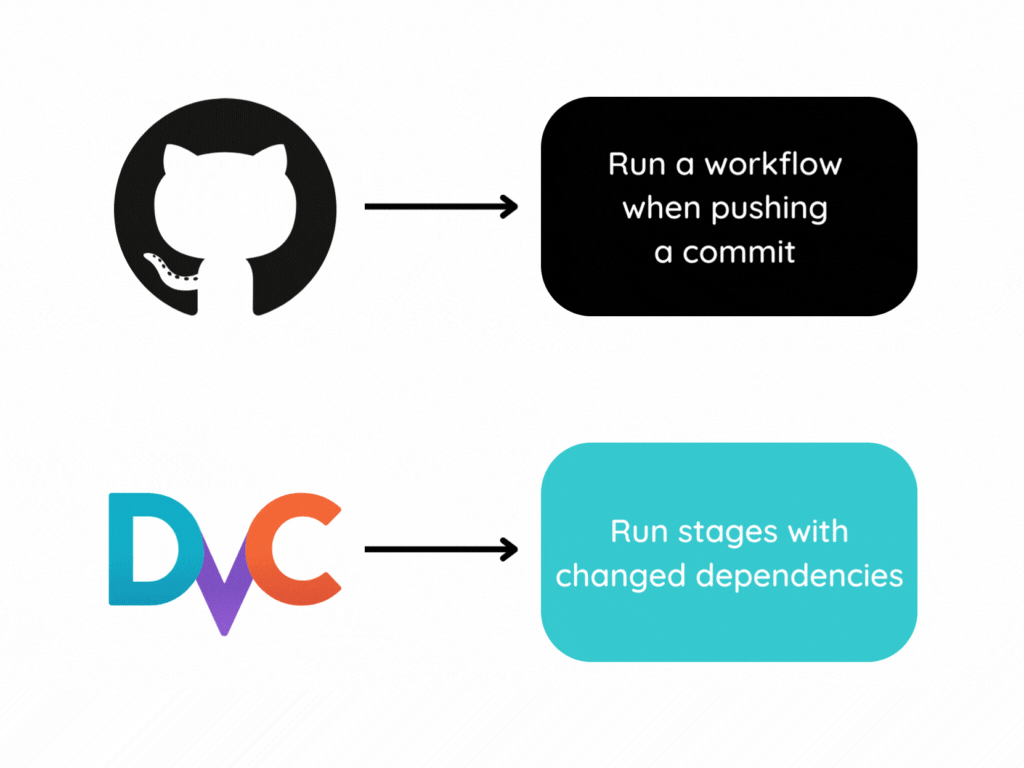
That is when the combination of DVC and GitHub Actions comes in handy. In this article, you will learn how to:
- Use GitHub Actions to run a workflow when you push a commit
- Use DVC to run stages with modified dependencies
Ultimately, combining these two tools will help reduce the friction and the time needed to experiment with different parameters, code, or data.
The code used in this article can be found here.
Run Modified Data Processes with DVC Pipelines
DVC is a system for data version control. It is essentially like Git but is used for data.
DVC pipelines allow you to specify the individual data processes (called stages) that produce a final result.
Pipeline Stages
Let’s create a DVC pipeline by creating two stages in the file dvc.yaml. In summary,
- The
process_datastage processes raw data - The
trainstage trains the processed data
stages:
process_data: # process raw data
cmd: python src/process_data.py
params:
- config/process/process_1.yaml:
deps:
- data/raw
- src/process_data.py
outs:
- data/intermediate
train: # train processed data
cmd: python src/segment.py
params:
- config/main.yaml:
deps:
- data/intermediate
- src/segment.py
outs:
- data/final
- model/cluster.pkl
plots:
- imageDetails of the code above:
cmdspecifies the command to run the stagedepsspecifies the files the stage depends onparamsspecifies a special kind of dependency: parameteroutsspecifies the directory for the outputs of the stageplotsspecifies a special kind of output: plot
Reproduce
To run the pipeline in dvc.yaml, type:
dvc reproOutput:
Running stage 'process_data'
Updating lock file 'dvc.lock'
Running stage 'train':
Updating lock file 'dvc.lock' The first time you run this command, DVC:
- Runs every stage in the pipeline
- Caches the run’s results
- Creates the
dvc.lockfile. This file describes the data to use and the commands to generate the pipeline results.
Now let’s say we change the src/segment.py file, which is dependent of the train stage. When you run dvc repro again, you will see the following:
Stage 'process_data' didn't change, skipping
Running stage 'train':
Updating lock file 'dvc.lock' From the output, we can see that DVC only runs the train stage because it:
- Detects changes in the
trainstage - Doesn’t detect changes in the
process_datastage.
This prevents us from wasting time on unnecessary reruns.
To track the changes in the pipeline with Git, run:
git add dvc.lockTo send the updates to the remote storage, type:
dvc pushRun the Pipeline When Pushing a Commit with GitHub Actions
GitHub Actions allows you to automate your workflows, making it faster to build, test, and deploy your code.
We will use GitHub Actions to run the DVC pipeline when committing the changes to GitHub.
Start with creating a file called run_pipline.yaml under the .github/workflows directory:
.github
└── workflows
└── run_pipeline.yamlThis is how the run_pipeline.yaml file looks like:
name: Run code
on:
push:
branches:
- dvc-pipeline
paths:
- config/**
- src/**
- data/*
jobs:
run_code:
name: Run code
runs-on: ubuntu-latest
container: khuyentran1401/customer_segmentation:dvc
steps:
- name: Check out the current repository
id: checkout
uses: actions/checkout@v2
- name: Pull data from DVC
run: |
dvc remote modify origin --local auth basic
dvc remote modify origin --local user ${{ secrets.DAGSHUB_USERNAME }}
dvc remote modify origin --local password ${{ secrets.DAGSHUB_TOKEN }}
dvc pull
- name: Run the pipeline with DVC
run: dvc repro
- name: Push the outcomes to DVC remote storage
run: dvc push
- name: Commit changes in dvc.lock
uses: stefanzweifel/git-auto-commit-action@v4
with:
commit_message: Commit changes in dvc.lock
branch: dvc-pipeline
file_pattern: dvc.lockThe first part of the file specifies the events that cause a workflow to run. Here, we tell GitHub Actions that the Run code workflow is triggered when:
- A commit is pushed to the
dvc-pipelinebranch - The push includes the changes to the files in the
configs,src, anddatadirectories
name: Run code
on:
push:
branches:
- dvc-pipeline
paths:
- config/**
- src/**
- data/*A workflow run is made up of one or more jobs. A job includes a set of steps that are executed in order. The second part of the file species the steps inside the run_code job.
jobs:
run_code:
name: Run code
runs-on: ubuntu-latest
container: khuyentran1401/customer_segmentation:dvc
steps:
- name: Check out the current repository
id: checkout
uses: actions/checkout@v2
- name: Pull data from DVC
run: |
dvc remote modify origin --local auth basic
dvc remote modify origin --local user ${{ secrets.DAGSHUB_USERNAME }}
dvc remote modify origin --local password ${{ secrets.DAGSHUB_TOKEN }}
dvc pull
- name: Run the pipeline with DVC
run: dvc repro
- name: Push the outcomes to DVC remote storage
run: dvc push
- name: Commit changes in dvc.lock
uses: stefanzweifel/git-auto-commit-action@v4
with:
commit_message: Commit changes in dvc.lock
branch: dvc-pipeline
file_pattern: dvc.lockAfter finishing writing the workflow, push the file to GitHub.
Let’s try the workflow by changing the file src/segment.py and pushing it to GitHub.
git add .
git commit -m 'edit segment.py'
git push origin dvc-pipelineWhen you click the Actions tab in your repository, you should see a new workflow run called edit segment.py .

Click the run to see more details about which step is running.

Congratulations! We have just succeeded in using GitHub Actions and DVC to:
- Run the workflow when changes are pushed to GitHub
- Rerun only stages with modified dependencies
What’s Next
If you are a data practitioner looking for a faster way to iterate on your data science project, I encourage you to try this. With a bit of initial setup, you will save a lot of time for your team in the long run.