5 Steps to Transform Messy Functions into Production-Ready Code
In a data science project, writing poorly designed functions can introduce maintenance hurdles and diminish the code’s readability.
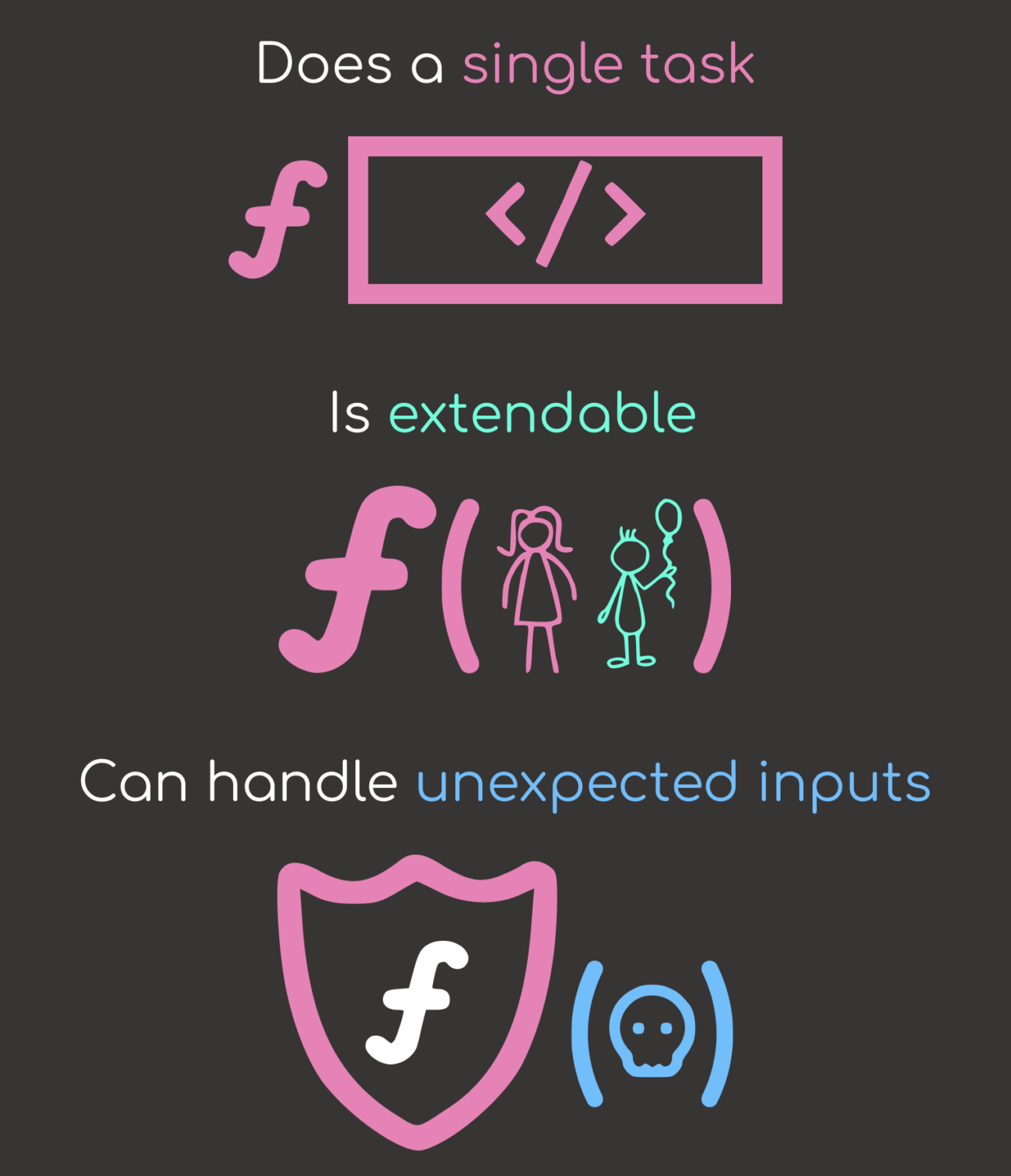
In this article, you will learn how to create a function that:
Perform a single, well-defined task
Can be extended without modifying the original code
Are capable of handling inputs with unexpected variations
By following these principles, you’ll be able to create functions that are not only effective but also easy to maintain and understand.
5 Steps to Transform Messy Functions into Production-Ready Code Read More »








