
Semantic search enables content discovery based on meaning rather than just keywords. This approach uses vector embeddings – numerical representations of text that capture semantic essence.
By converting text to vector embeddings, we can quantify semantic similarity between different pieces of content in a high-dimensional vector space. This allows for comparison and search based on underlying meaning, surpassing simple keyword matching.
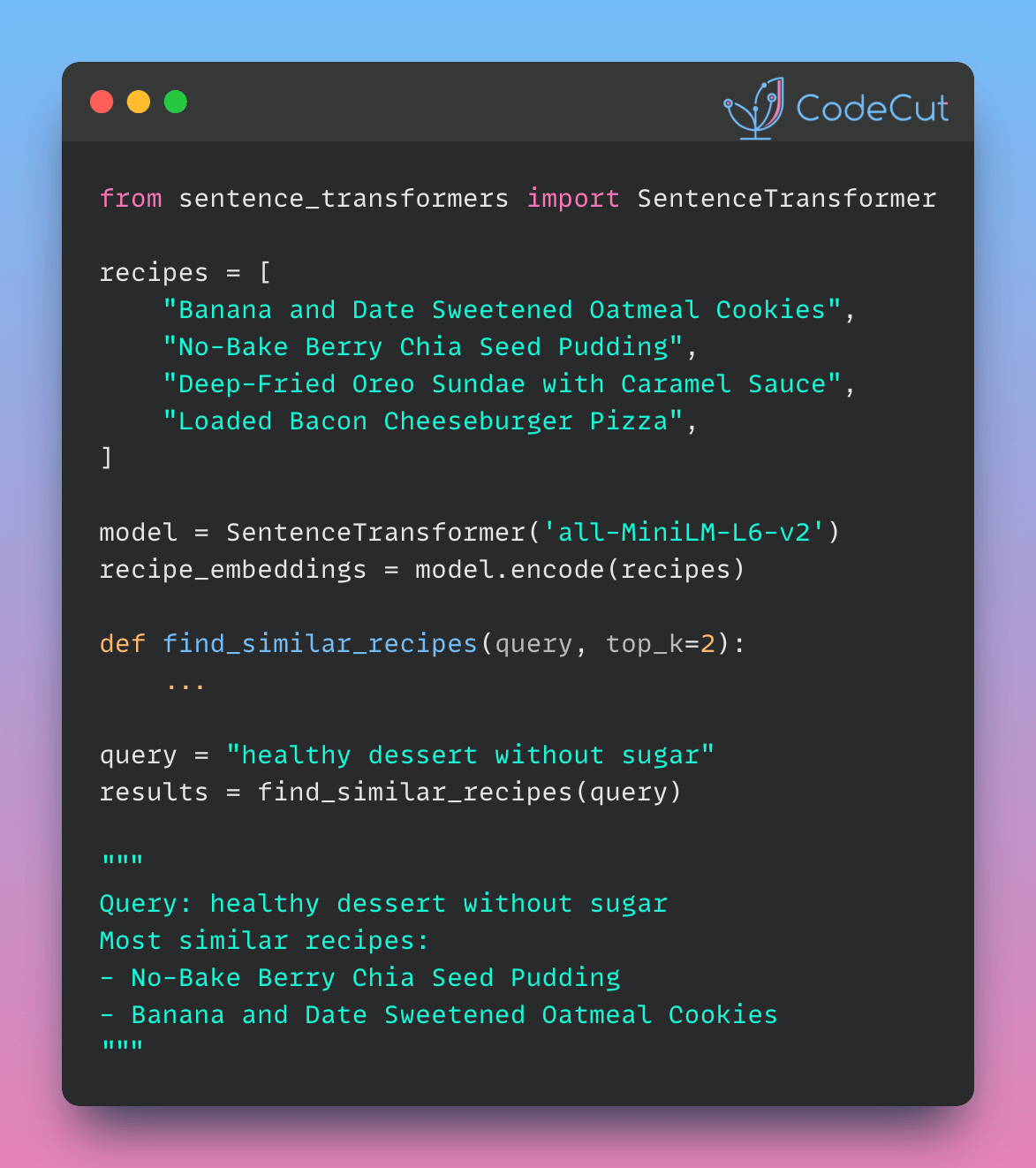
Here’s a Python implementation of semantic search for recipe recommendations using sentence-transformers:
- Import necessary libraries for creating sentence embeddings and calculating similarity:
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity- Create a list of recipe titles that we’ll use for our search:
recipes = [
"Banana and Date Sweetened Oatmeal Cookies",
"No-Bake Berry Chia Seed Pudding",
"Deep-Fried Oreo Sundae with Caramel Sauce",
"Loaded Bacon Cheeseburger Pizza",
]- Load a pre-trained model for creating sentence embeddings
model = SentenceTransformer('all-MiniLM-L6-v2')- Create vector representations (embeddings) for all the recipe titles.
recipe_embeddings = model.encode(recipes)- Define search function that takes a query and number of results to return. It creates an embedding for the query, calculates similarities with all recipes, and returns the top k similar recipes.
def find_similar_recipes(query, top_k=2):
query_embedding = model.encode([query])
similarities = cosine_similarity(query_embedding, recipe_embeddings)[0]
top_indices = similarities.argsort()[-top_k:][::-1]
return [(recipes[i], similarities[i]) for i in top_indices]- Set up a test query and calls the function to find similar recipes.
query = "healthy dessert without sugar"
results = find_similar_recipes(query)- Print the query and the most similar recipes with their similarity scores.
print(f"Query: {query}")
print("Most similar recipes:")
for recipe, score in results:
print(f"- {recipe} (Similarity: {score:.2f})")Output:
Query: healthy dessert without sugar
Most similar recipes:
- No-Bake Berry Chia Seed Pudding (Similarity: 0.55)
- Banana and Date Sweetened Oatmeal Cookies (Similarity: 0.43)This implementation successfully identifies healthier dessert options, understanding that ingredients like berries, chia seeds, bananas, and dates are often used in healthy, sugar-free desserts. It excludes clearly unhealthy options, demonstrating comprehension of “healthy” in the dessert context. The score difference (0.55 vs 0.43) indicates that the model considers the chia seed pudding a closer match to the concept of a healthy, sugar-free dessert than the oatmeal cookies.