

[htyoutube controls=”1″ start =”10″ end=”40″ thumbnailresolution=”recommended” thumbnail=””]4w2ly3WuL40[/htyoutube]
Motivation
Data drift occurs when the distribution of input features in the production environment differs from the training data, leading to potential inaccuracies and decreased model performance.

To mitigate the impact of data drift on model performance, we can design a workflow that detects drift, notifies the data team, and triggers model retraining.

Workflows
The workflow comprises the following tasks:
- Fetch reference data from the Postgres database.
- Get the current production data from the web.
- Detect data drift by comparing the reference and current data.
- Append the current data to the existing Postgres database.
- When there is data drift, the following actions are taken:
- Send a Slack message to alert the data team.
- Retrain the model to update its performance.
- Push the updated model to S3 for storage.
This workflow is scheduled to run at specific times, such as 11:00 AM every Monday.
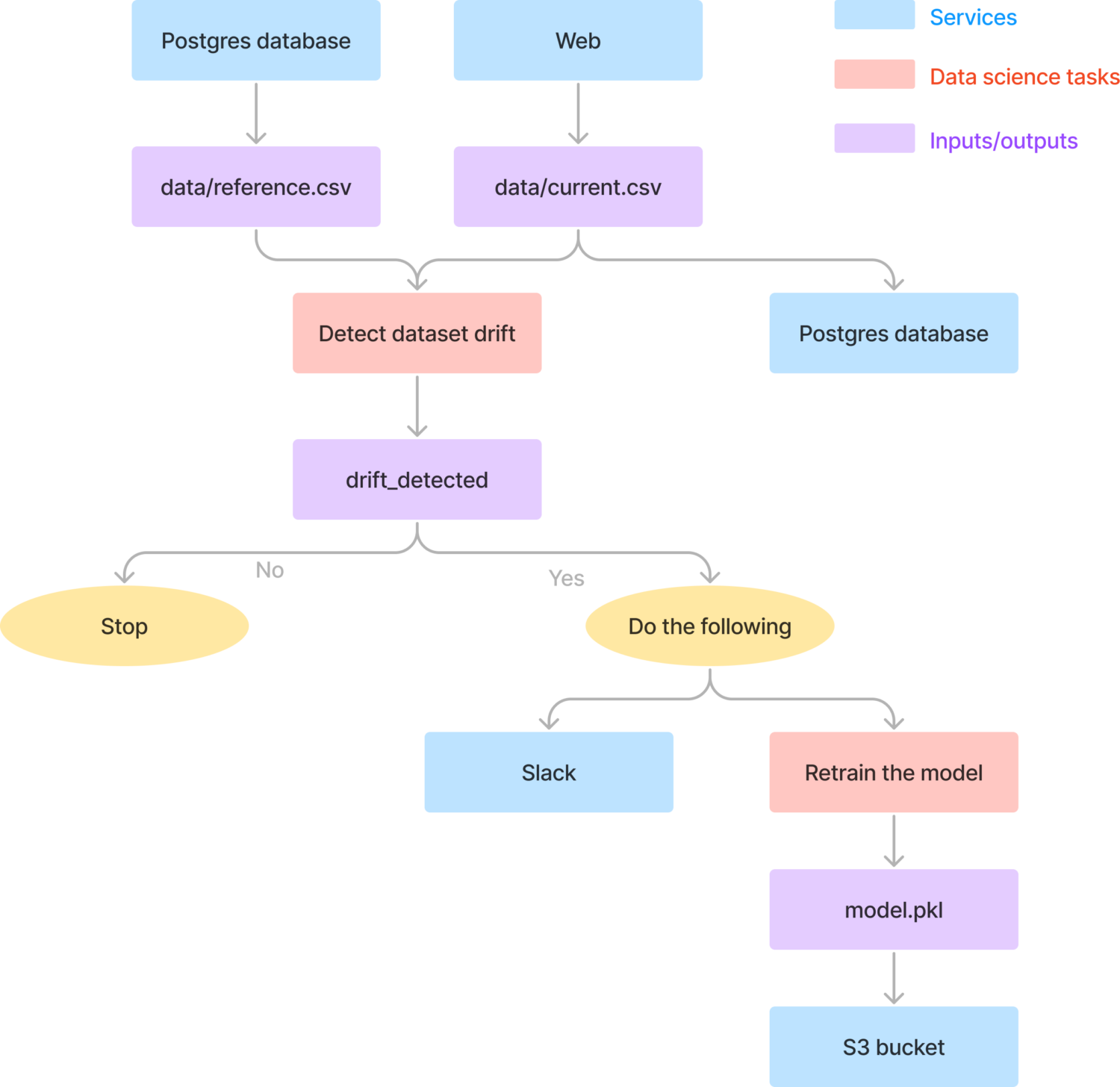
Overall, the workflow includes two types of tasks: data science and data engineering tasks.
Data science tasks, represented by pink boxes, are performed by data scientists and involve data drift detection, data processing, and model training.
Data engineering tasks, represented by blue and purple boxes, are performed by data engineers and involve tasks related to data movement and sending notifications.
Data Science Tasks
Detect Data Drift
To detect data drift, we will create a Python script that takes two CSV files “data/reference.csv” (reference data) and “data/current.csv” (current data).
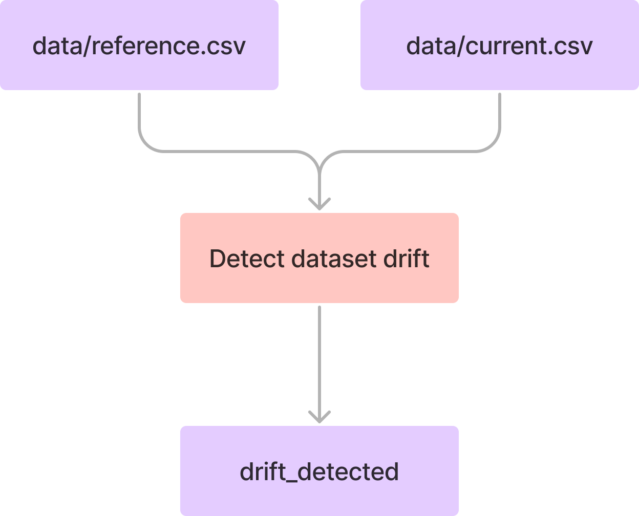
We will use Evidently, an open-source ML observability platform, to compare the reference data, serving as a baseline, with the current production data. If dataset drift is detected, the “drift_detected” output will be True; otherwise, it will be False.
from evidently.metric_preset import DataDriftPreset
from evidently.report import Report
from kestra import Kestra
data_drift_report = Report(metrics=[DataDriftPreset()])
data_drift_report.run(reference_data=reference, current_data=current)
report = data_drift_report.as_dict()
drift_detected = report["metrics"][0]["result"]["dataset_drift"]
if drift_detected:
print("Detect dataset drift")
else:
print("Detect no dataset drift")
Kestra.outputs({"drift_detected": drift_detected})
Retrain the Model
Next, we will create a Python script responsible for model training. This script takes the combined past and current data as input and saves the trained model as a “model.pkl” file.

def train_model(X_train: pd.DataFrame, y_train: pd.Series, model_params: DictConfig):
y_train_log = np.log1p(y_train)
model = Ridge()
scorer = metrics.make_scorer(rmsle, greater_is_better=True)
params = dict(model_params)
grid = GridSearchCV(model, params, scoring=scorer, cv=3, verbose=3)
grid.fit(X_train, y_train_log)
return grid
model = train_model(X_train, y_train, config.model.params)
joblib.dump(model, "model.pkl")Push to GitHub
After finishing developing these two scripts, data scientists can push them to GitHub, allowing data engineers to use them in creating workflows.
View the GitHub repository for these files here:
Data Engineering Tasks
Popular orchestration libraries such as Airflow, Prefect, and Dagster require modifications to the Python code to use their functionalities.
When Python scripts are tightly integrated into the data workflows, the overall codebase can become more complex and harder to maintain. Without independent Python script development, data engineers may need to modify the data science code to add orchestration logic.

On the other hand, Kestra, an open-source library, allows you to develop your Python scripts independently and then seamlessly incorporate them into data workflows using YAML files.
This way, data scientists can focus on model processing and training, while data engineers can focus on handling orchestration.
Thus, we will use Kestra to design a more modular and efficient workflow.
Clone the detect-data-drift-pipeline repository to get the docker-compose file for Kestra, then run:
docker compose up -dNavigate to localhost:8080 to access and explore the Kestra UI.

Follow these instructions to configure the required environment for this tutorial.
Before developing the target flows, let’s get familiar with Kestra by creating some simple flows.
Access Postgres Tables From a Python Script
We will create a flow that includes the following tasks:
getReferenceTable: Exports a CSV file from a Postgres table.saveReferenceToCSV: Creates a local CSV file that can be accessed by the Python task.runPythonScript: Reads the local CSV file with Python.
To enable data passing between the saveReferenceToCSV and runPythonScript tasks, we will place these two tasks in the same working directory by enclosing them inside the wdir task.
id: get-reference-table
namespace: dev
tasks:
- id: getReferenceTable
type: io.kestra.plugin.jdbc.postgresql.CopyOut
url: jdbc:postgresql://host.docker.internal:5432/
username: "{{secret('POSTGRES_USERNAME')}}"
password: "{{secret('POSTGRES_PASSWORD')}}"
format: CSV
sql: SELECT * FROM reference
header: true
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: saveReferenceToCSV
type: io.kestra.core.tasks.storages.LocalFiles
inputs:
data/reference.csv: "{{outputs.getReferenceTable.uri}}"
- id: runPythonScript
type: io.kestra.plugin.scripts.python.Script
beforeCommands:
- pip install pandas
script: |
import pandas as pd
df = pd.read_csv("data/reference.csv")
print(df.head(10))
Executing the flow will show the following logs:

Parameterize Flow with Inputs
Let’s create another flow that can be parameterized with inputs. This flow will have the following inputs: startDate, endDate, and dataURL.
The getCurrentCSV task can access these inputs using the {{inputs.name}} notation.
id: get-current-table
namespace: dev
inputs:
- name: startDate
type: STRING
defaults: "2011-03-01"
- name: endDate
type: STRING
defaults: "2011-03-31"
- name: dataURL
type: STRING
defaults: "https://raw.githubusercontent.com/khuyentran1401/detect-data-drift-pipeline/main/data/bikeride.csv"
tasks:
- id: getCurrentCSV
type: io.kestra.plugin.scripts.python.Script
beforeCommands:
- pip install pandas
script: |
import pandas as pd
df = pd.read_csv("{{inputs.dataURL}}", parse_dates=["dteday"])
print(f"Getting data from {{inputs.startDate}} to {{inputs.endDate}}")
df = df.loc[df.dteday.between("{{inputs.startDate}}", "{{inputs.endDate}}")]
df.to_csv("current.csv", index=False)
The values of these inputs can be specified in each flow execution.

Load a CSV File into a Postgres Table
The following flow does the following tasks:
getCurrentCSV: Runs a Python script to create a CSV file in the working directory.saveFiles: Sends the CSV file from the working directory to Kestra’s internal storage.saveToCurrentTable: Loads the CSV file into a Postgres table.
id: save-current-table
namespace: dev
tasks:
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: getCurrentCSV
type: io.kestra.plugin.scripts.python.Script
beforeCommands:
- pip install pandas
script: |
import pandas as pd
data_url = "https://raw.githubusercontent.com/khuyentran1401/detect-data-drift-pipeline/main/data/bikeride.csv"
df = pd.read_csv(data_url, parse_dates=["dteday"])
df.to_csv("current.csv", index=False)
- id: saveFiles
type: io.kestra.core.tasks.storages.LocalFiles
outputs:
- current.csv
- id: saveToCurrentTable
type: io.kestra.plugin.jdbc.postgresql.CopyIn
url: jdbc:postgresql://host.docker.internal:5432/
username: "{{secret('POSTGRES_USERNAME')}}"
password: "{{secret('POSTGRES_PASSWORD')}}"
from: "{{outputs.saveFiles.uris['current.csv']}}"
table: current
format: CSV
header: true
delimiter: ","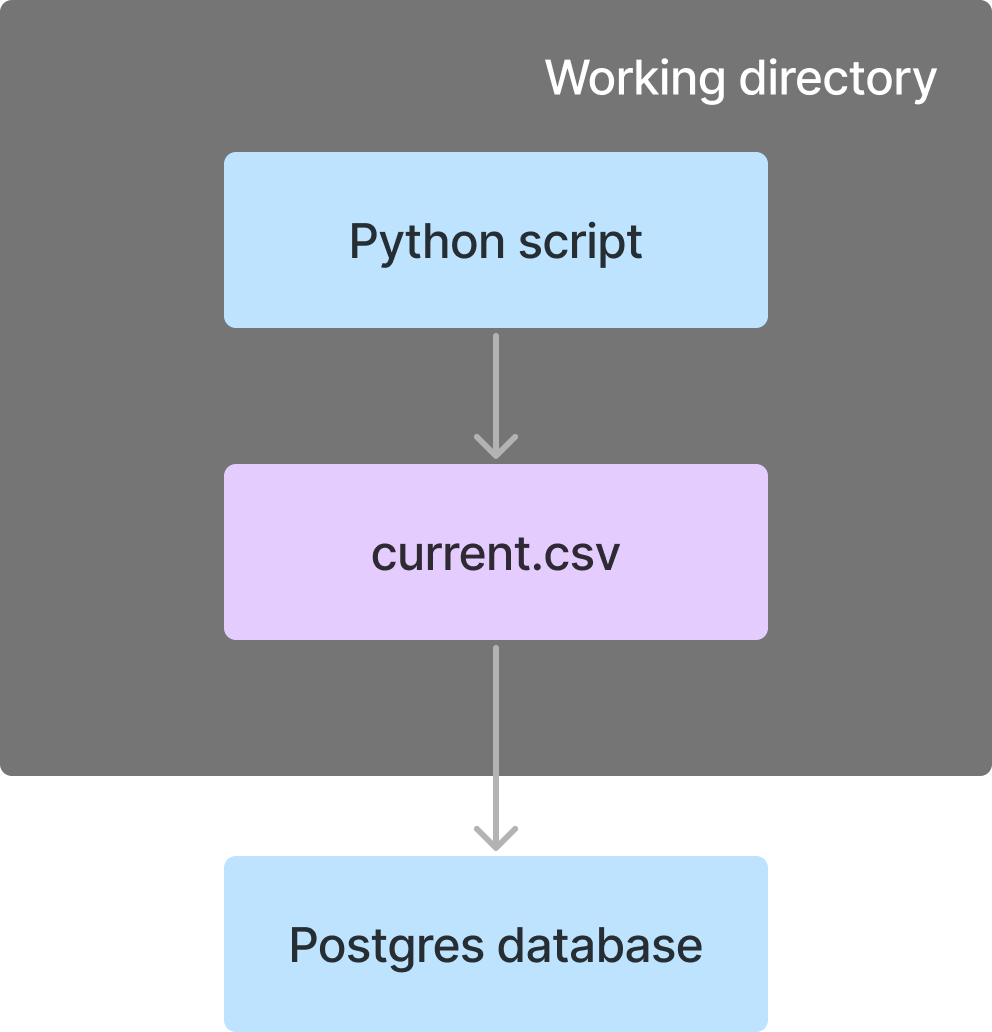
After running this flow, you will see the resulting data in the “current” table within your Postgres database.

Run a File From a GitHub Repository
This flow includes the following tasks:
cloneRepository: Clones a public GitHub repositoryrunPythonCommand: Executes a Python script from a CLI
Both of these tasks will operate within the same working directory.
id: clone-repository
namespace: dev
tasks:
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: cloneRepository
type: io.kestra.plugin.git.Clone
url: https://github.com/khuyentran1401/detect-data-drift-pipeline
branch: main
- id: runPythonCommand
type: io.kestra.plugin.scripts.python.Commands
commands:
- python src/example.py
After running the flow, you will see the following logs:

Run a Flow on Schedule
We will create another flow that runs a flow based on a specific schedule. The following flow runs at 11:00 AM every Monday.
id: triggered-flow
namespace: dev
tasks:
- id: hello
type: io.kestra.core.tasks.log.Log
message: Hello world
triggers:
- id: schedule
type: io.kestra.core.models.triggers.types.Schedule
cron: "0 11 * * MON"Upload to S3
This flow includes the following tasks:
createPickle: Generates a pickle file in PythonsavetoPickle: Transfers the pickle file to Kestra’s internal storageupload: Uploads the pickle file to an S3 bucket
id: upload-to-S3
namespace: dev
tasks:
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: createPickle
type: io.kestra.plugin.scripts.python.Script
script: |
import pickle
data = [1, 2, 3]
with open('data.pkl', 'wb') as f:
pickle.dump(data, f)
- id: saveToPickle
type: io.kestra.core.tasks.storages.LocalFiles
outputs:
- data.pkl
- id: upload
type: io.kestra.plugin.aws.s3.Upload
accessKeyId: "{{secret('AWS_ACCESS_KEY_ID')}}"
secretKeyId: "{{secret('AWS_SECRET_ACCESS_KEY_ID')}}"
region: us-east-2
from: '{{outputs.saveToPickle.uris["data.pkl"]}}'
bucket: bike-sharing
key: data.pkl
After running this flow, the data.pkl file will be uploaded to the “bike-sharing” bucket.

Put Everything Together
Build a Flow to Detect Data Drift
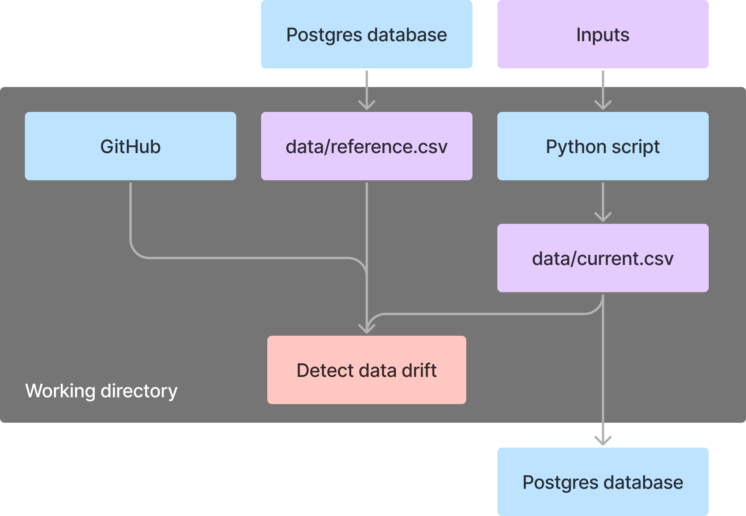
Now, let’s combine what we have learned to create a flow to detect data drift. At 11:0 AM every Monday, this flow executes the following tasks:
- Fetches reference data from the Postgres database.
- Runs a Python script to get the current production data from the web.
- Clones the GitHub repository containing the drift detection code
- Runs a Python script to data drift by comparing the reference and current data.
- Appends the current data to the existing Postgres database.
id: detect-data-drift
namespace: dev
inputs:
- name: startDate
type: STRING
defaults: "2011-03-01"
- name: endDate
type: STRING
defaults: "2011-03-31"
- name: data_url
type: STRING
defaults: "https://raw.githubusercontent.com/khuyentran1401/detect-data-drift-pipeline/main/data/bikeride.csv"
tasks:
- id: getReferenceTable
type: io.kestra.plugin.jdbc.postgresql.CopyOut
url: jdbc:postgresql://host.docker.internal:5432/
username: "{{secret('POSTGRES_USERNAME')}}"
password: "{{secret('POSTGRES_PASSWORD')}}"
format: CSV
sql: SELECT * FROM reference
header: true
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: cloneRepository
type: io.kestra.plugin.git.Clone
url: https://github.com/khuyentran1401/detect-data-drift-pipeline
branch: main
- id: saveReferenceToCSV
type: io.kestra.core.tasks.storages.LocalFiles
inputs:
data/reference.csv: "{{outputs.getReferenceTable.uri}}"
- id: getCurrentCSV
type: io.kestra.plugin.scripts.python.Script
beforeCommands:
- pip install pandas
script: |
import pandas as pd
df = pd.read_csv("{{inputs.data_url}}", parse_dates=["dteday"])
print(f"Getting data from {{inputs.startDate}} to {{inputs.endDate}}")
df = df.loc[df.dteday.between("{{inputs.startDate}}", "{{inputs.endDate}}")]
df.to_csv("data/current.csv", index=False)
- id: detectDataDrift
type: io.kestra.plugin.scripts.python.Commands
beforeCommands:
- pip install -r src/detect/requirements.txt
commands:
- python src/detect/detect_data_drift.py
- id: saveFileInStorage
type: io.kestra.core.tasks.storages.LocalFiles
outputs:
- data/current.csv
- id: saveToCurrentTable
type: io.kestra.plugin.jdbc.postgresql.CopyIn
url: jdbc:postgresql://host.docker.internal:5432/
username: "{{secret('POSTGRES_USERNAME')}}"
password: "{{secret('POSTGRES_PASSWORD')}}"
from: "{{outputs.saveFileInStorage.uris['data/current.csv']}}"
table: current
format: CSV
header: true
delimiter: ","
triggers:
- id: schedule
type: io.kestra.core.models.triggers.types.Schedule
cron: "0 11 * * MON"Build a Flow to Send Slack Messages
Next, we will create a flow to send Slack messages via a Slack Webhook URL when the detectDataDrift task inside the detect-data-drift flow returns drift_detected=true.

id: send-slack-message
namespace: dev
tasks:
- id: send
type: io.kestra.plugin.notifications.slack.SlackExecution
url: "{{secret('SLACK_WEBHOOK')}}"
customMessage: Detect data drift
triggers:
- id: listen
type: io.kestra.core.models.triggers.types.Flow
conditions:
- type: io.kestra.core.models.conditions.types.ExecutionFlowCondition
namespace: dev
flowId: detect-data-drift
- type: io.kestra.core.models.conditions.types.VariableCondition
expression: "{{outputs.detectDataDrift.vars.drift_detected}} == true"After running the detect-data-drift flow, the send-slack-message flow will send a message on Slack.

Build a Flow to Retrain the Model
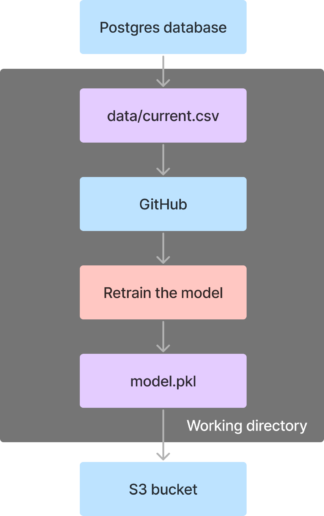
Lastly, we will create a flow to retrain the model. This flow executes the following tasks:
- Exports a CSV file from the current table in the Postgres database
- Clones the GitHub repository containing the model training code
- Runs a Python script to train the model and generates a pickle file
- Uploads the pickle file to S3
id: train-model
namespace: dev
tasks:
- id: getCurrentTable
type: io.kestra.plugin.jdbc.postgresql.CopyOut
url: jdbc:postgresql://host.docker.internal:5432/
username: "{{secret('POSTGRES_USERNAME')}}"
password: "{{secret('POSTGRES_PASSWORD')}}"
format: CSV
sql: SELECT * FROM current
header: true
- id: wdir
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: cloneRepository
type: io.kestra.plugin.git.Clone
url: https://github.com/khuyentran1401/detect-data-drift-pipeline
branch: main
- id: saveCurrentToCSV
type: io.kestra.core.tasks.storages.LocalFiles
inputs:
data/current.csv: "{{outputs.getCurrentTable.uri}}"
- id: trainModel
type: io.kestra.plugin.scripts.python.Commands
beforeCommands:
- pip install -r src/train/requirements.txt
commands:
- python src/train/train_model.py
- id: saveToPickle
type: io.kestra.core.tasks.storages.LocalFiles
outputs:
- model.pkl
- id: upload
type: io.kestra.plugin.aws.s3.Upload
accessKeyId: "{{secret('AWS_ACCESS_KEY_ID')}}"
secretKeyId: "{{secret('AWS_SECRET_ACCESS_KEY_ID')}}"
region: us-east-2
from: '{{outputs.saveToPickle.uris["model.pkl"]}}'
bucket: bike-sharing
key: model.pkl
triggers:
- id: listenFlow
type: io.kestra.core.models.triggers.types.Flow
conditions:
- type: io.kestra.core.models.conditions.types.ExecutionFlowCondition
namespace: dev
flowId: detect-data-drift
- type: io.kestra.core.models.conditions.types.VariableCondition
expression: "{{outputs.detectDataDrift.vars.drift_detected}} == true"After running this flow, the model.pkl file will be uploaded to the “bike-sharing” bucket.

Ideas to Extend This Workflow
Rather than relying on scheduled data pulls to identify data drift, we can leverage Grafana’s outgoing webhook and Kestra’s inbound webhook to establish real-time data monitoring and trigger a flow instantly when data drift occurs. This approach enables the detection of data drift as soon as it happens, eliminating the need to wait for a scheduled script to run.

Let me know in the comments how you think this workflow could be extended and what other use cases you would like to see in future content.
I love writing about data science concepts and playing with different data science tools. You can stay up-to-date with my latest posts by:



3 thoughts on “Build a Fully Automated Data Drift Detection Pipeline”
Hey Khuyen, just a small correction to your blog. The first flowchart (above workflows) has “yes” and “no” labels mixed up. They need to be interchanged. 😊
Yes you are right. Thanks for correcting it. I’ll fix it.
It’s done. Thank you!