
Time series data is unique because it has a temporal order. This means that data from the future shouldn’t influence predictions about the past. However, standard cross-validation techniques like K-Fold randomly shuffle the data, potentially using future information to predict past events.
scikit-learn’s TimeSeriesSplit is a specialized cross-validator for time series data. It respects the temporal order of our data, ensuring that we always train on past data and test on future data.
Let’s explore how to use TimeSeriesSplit with a simple example:
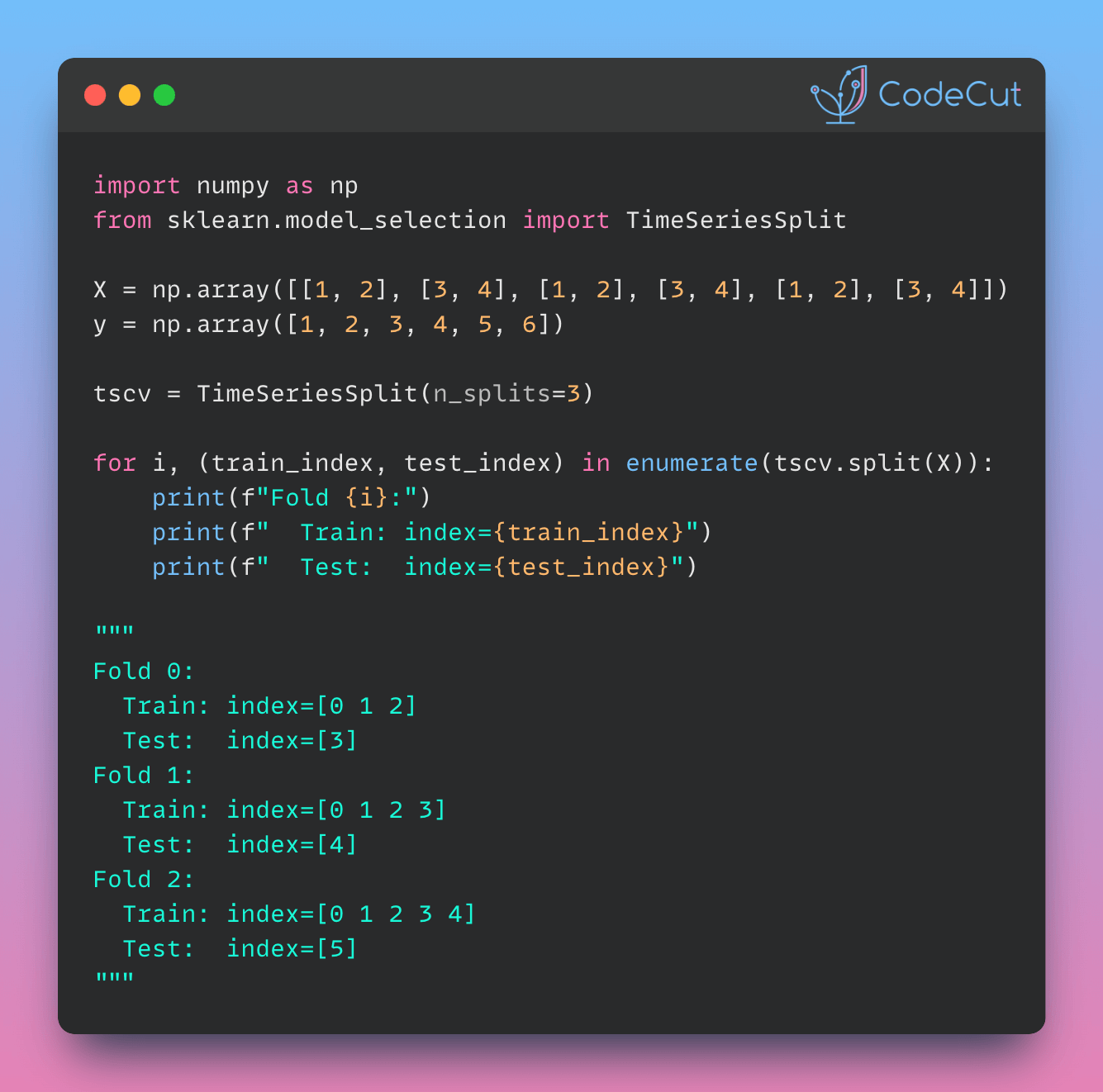
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
tscv = TimeSeriesSplit(n_splits=3)
for i, (train_index, test_index) in enumerate(tscv.split(X)):
print(f"Fold {i}:")
print(f" Train: index={train_index}")
print(f" Test: index={test_index}")Fold 0:
Train: index=[0 1 2]
Test: index=[3]
Fold 1:
Train: index=[0 1 2 3]
Test: index=[4]
Fold 2:
Train: index=[0 1 2 3 4]
Test: index=[5]From the outputs, we can see that:
- Temporal Integrity: The split always respects the original order of the data.
- Growing Training Set: With each fold, the training set expands to include more historical data.
- Forward-Moving Test Set: The test set is always a single future sample, progressing with each fold.
- No Data Leakage: Future information is never used to predict past events.
This approach mimics real-world forecasting scenarios, where models use historical data to predict future outcomes.


