Skip to content
Explore
Blog
Book
Courses
Explore
Blog
Book
Courses
Generic selectors
Exact matches only
Search in title
Search in content
Post Type Selectors
Filter by Categories
About Article
Analyze Data
Archive
Best Practices
Better Outputs
Blog
Code Optimization
Code Quality
Command Line
Course
Daily tips
Dashboard
Data Analysis & Manipulation
Data Engineer
Data Visualization
DataFrame
Delta Lake
DevOps
DuckDB
Environment Management
Feature Engineer
Git
Jupyter Notebook
LLM
LLM Tools
Machine Learning
Machine Learning & AI
Machine Learning Tools
Manage Data
MLOps
Natural Language Processing
Newsletter Archive
NumPy
Pandas
Polars
PySpark
Python Helpers
Python Tips
Python Utilities
Scrape Data
SQL
Testing
Time Series
Tools
Visualization
Visualization & Reporting
Workflow & Automation
Workflow Automation
Data Analysis & Manipulation
Analyze Data
Manage Data
Feature Engineer
SQL
Machine Learning & AI
Machine Learning
Natural Language Processing
Time Series
LLM
Code Quality
Python Tips
Python-Utilities
Code Optimization
DevOps
Testing
Git
Command Line
Environment Management
Better Outputs
Tools
NumPy
Pandas
Polars
PySpark
Delta Lake
DuckDB
Jupyter Notebook
Visualization & Reporting
Dashboard
Visualization
Workflow & Automation
Workflow Automation
Scrape Data
X
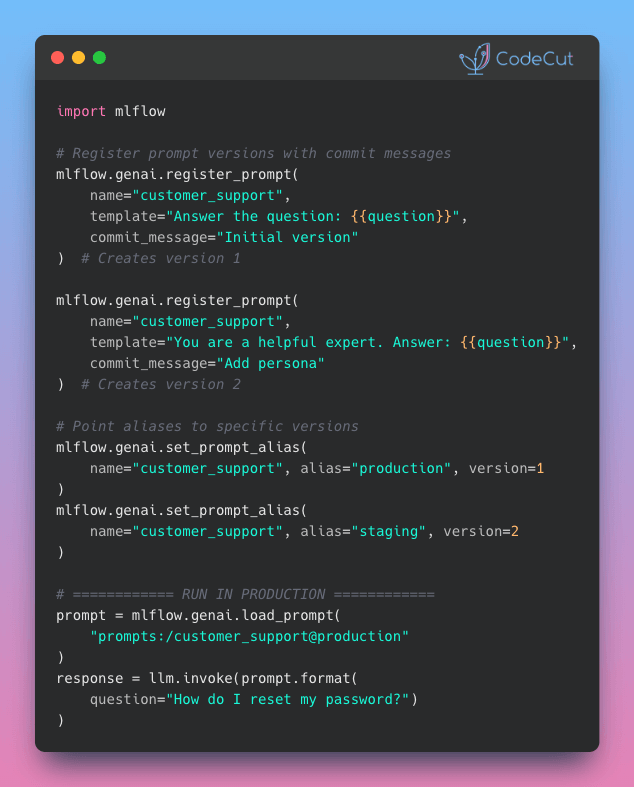
Newsletter #279: Swap AI Prompts Instantly with MLflow Prompt Registry
January 19, 2026
Unregistry: Skip the Registry, Deploy Docker Images Directly
July 31, 2025
Python-Magic: Reliable File Type Detection Beyond Extensions
July 23, 2025
Make PySpark Queries Cleaner with Column Aliasing
April 20, 2025
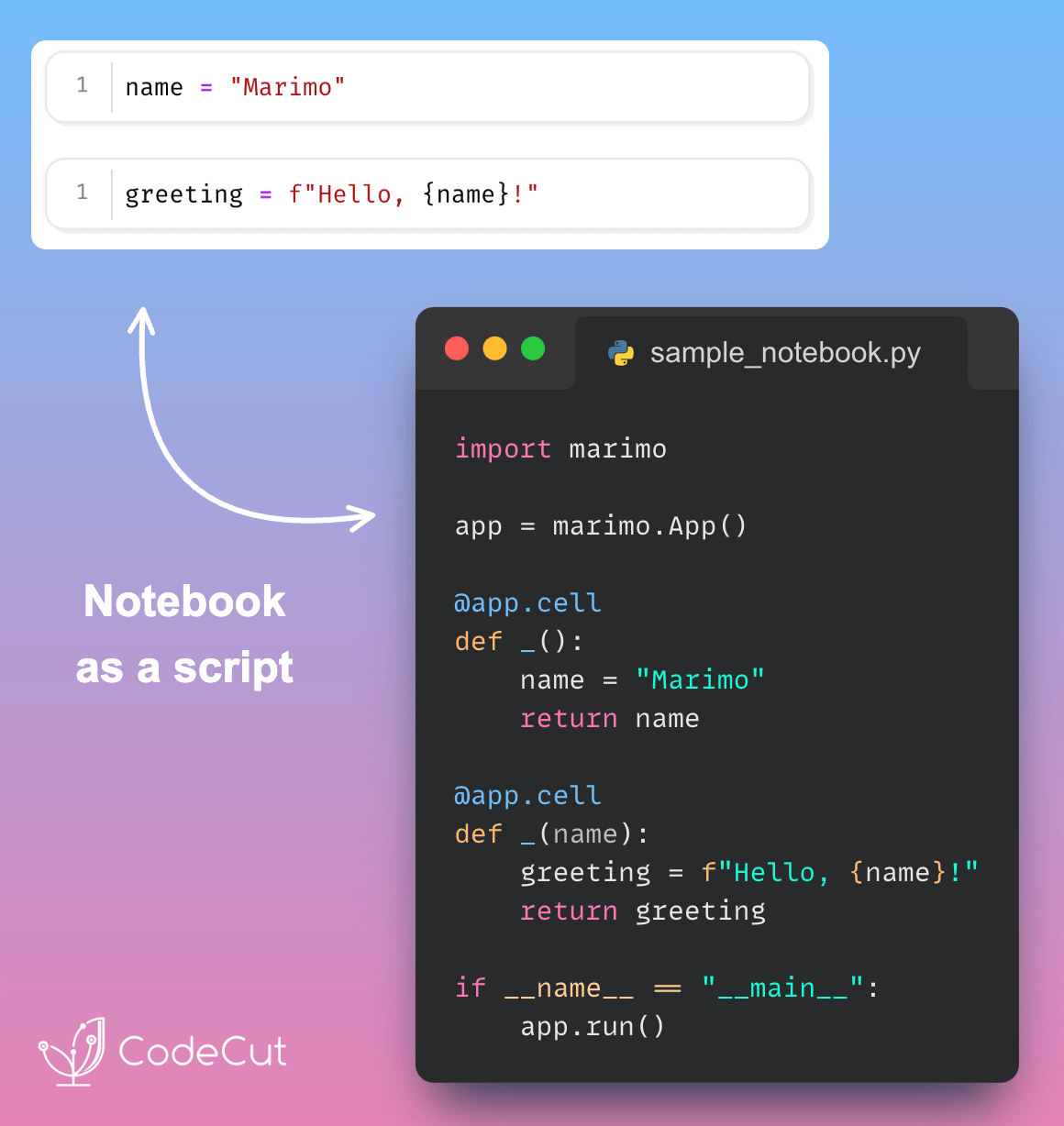
Run Notebooks Like Python Scripts with Marimo
April 17, 2025
Simplify SQL Parsing and Transpilation with SQLGlot
April 15, 2025
Comparing Join Performance: Pandas vs. Polars
April 14, 2025
Automate CSV Parsing with DuckDB’s read_csv
April 9, 2025
Simplify Nested Structures with Python Data Classes
April 8, 2025
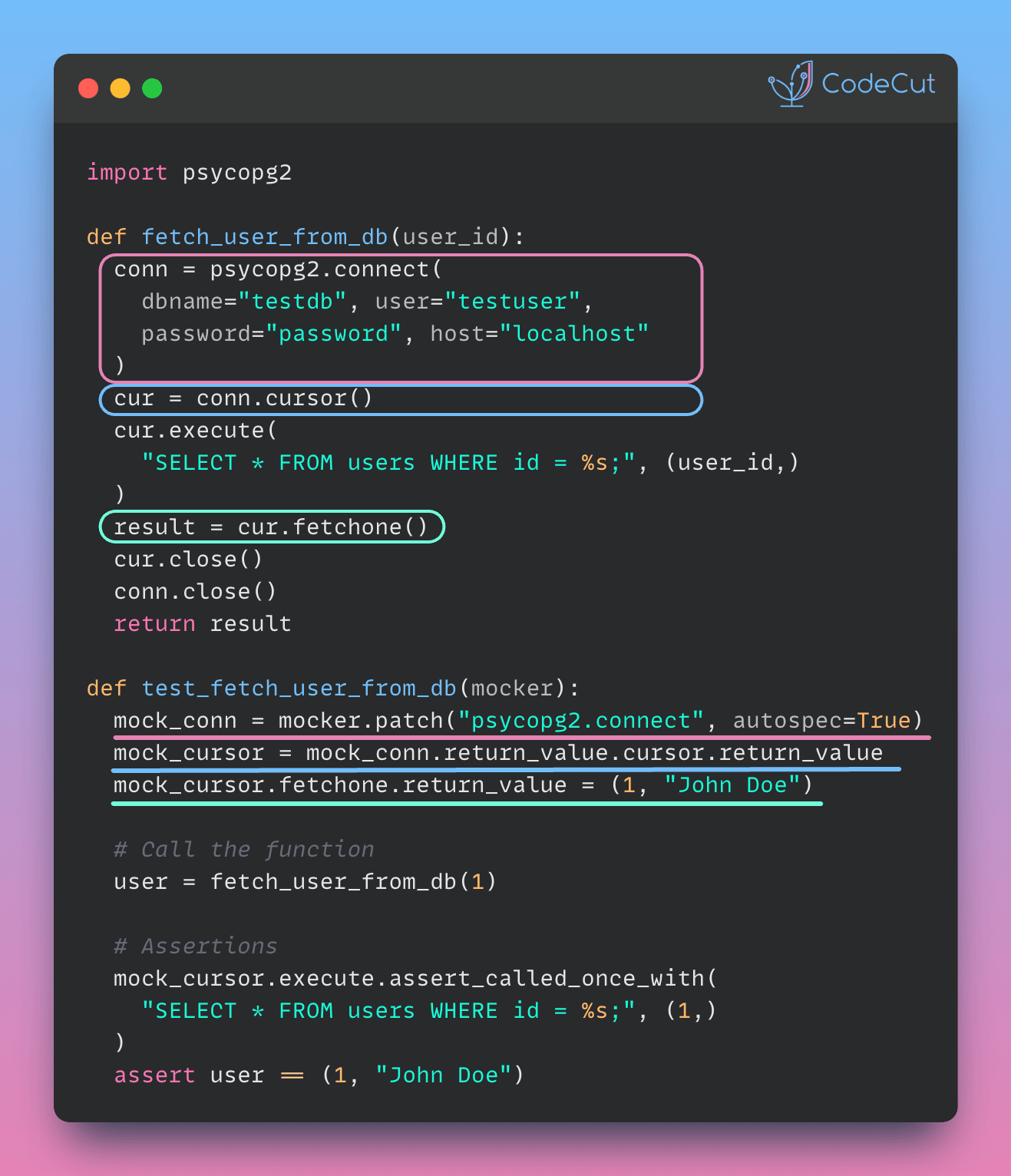
Simulate External Services in Testing with Mock Objects
April 7, 2025
Update Multiple Columns in Spark 3.3 and Later
April 6, 2025
Extract Dates from Text with Datefinder
April 3, 2025
Combine SQL and Python Efficiently with Ibis
April 2, 2025
Formulaic: Write Clear Feature Engineering Code
April 1, 2025
Simplify Tabular Dataset Preparation with TabularPandas
March 30, 2025
« Previous
Page
1
Page
2
Page
3
Page
4
Page
5
Next »
Scroll to Top
Work with Khuyen Tran
Enter Your Total Budget
Please explain the goals of you campaign
Why Do you want to collaborate with Khuyen Tran
Add date preferences
Enter your contact details
Submit
Work with Khuyen Tran
Enter Your Total Budget
Please explain the goals of you campaign
Why Do you want to collaborate with Khuyen Tran
Add date preferences
Enter your contact details
Submit