[htyoutube controls=”1″ start =”10″ end=”40″ thumbnailresolution=”recommended” thumbnail=””]vQFg1Mp60-s[/htyoutube]
Motivation
dbt (data build tool) is a powerful tool for data transformation within the data warehouse.
However, it does come with some limitations, including the following:
- Lack of Output Preview: With dbt core, it is not possible to preview the output of a model before building it, which can hinder the ability to validate and iterate on the data transformation process.
- Limitations in Feature Engineering: Since SQL is dbt’s primary language, there are certain limitations when it comes to advanced feature engineering tasks. To perform complex feature engineering beyond the capabilities of SQL, additional tools or languages such as Python may be required.
- Partial ETL Solution: While dbt excels in data transformation, it does not provide a comprehensive end-to-end solution for tasks like data loading, data extraction, and orchestration.
To mitigate some of these challenges, dbt Cloud offers features like developing data models, previewing outputs, and scheduling dbt jobs through a user-friendly web-based UI. However, as the number of projects grows, the cost of utilizing dbt Cloud can become substantial.
Mage + dbt Integration
A free alternative to dbt cloud is Mage, an open-source data pipeline tool for data transformation and integration tasks.
Mage seamlessly complements dbt with a range of benefits, including:
- Integrated Web-based IDE: Mage provides a convenient web-based Integrated Development Environment (IDE) where you can develop and explore data models effortlessly within a single interface.
- Language Flexibility: With Mage, you can combine the strengths of different tools and languages alongside dbt for enhanced data processing capabilities.
- Visualizing dbt Model Output: Mage provides a built-in visualization capability, allowing users to effortlessly visualize the output generated by dbt models with just a few clicks.
- Data Extraction and Loading: In addition to data transformation, Mage offers functionalities for data extraction and loading, enabling a more comprehensive end-to-end data pipeline solution.
- Pipeline Scheduling and Retry Mechanism: Mage allows you to schedule your data pipelines and automatically retry failed components, ensuring the smooth and reliable execution of your data integration processes.
Let’s dive deeper into each of these features.
Feel free to explore and experiment with the source code by cloning this GitHub repository:
Setup
Install Mage
You can install Mage using Docker, pip, or conda. This article will use Docker to install Mage and initialize the project.
docker run -it -p 6789:6789 -v $(pwd):/home/src mageai/mageai /app/run_app.sh mage start [project_name]For example, let’s name our project “dbt_mage,” so the command becomes:
docker run -it -p 6789:6789 -v $(pwd):/home/src mageai/mageai /app/run_app.sh mage start dbt_mageFind other ways to install Mage here.
Create a pipeline
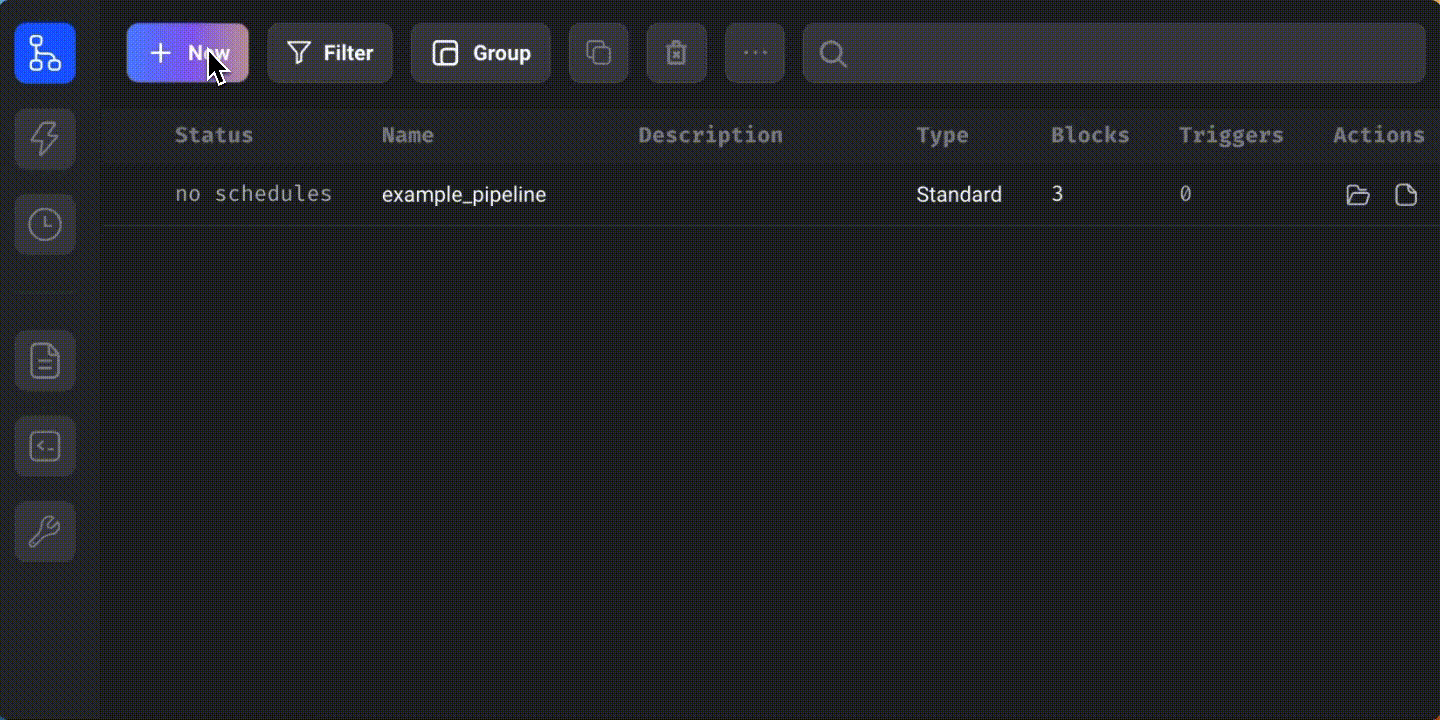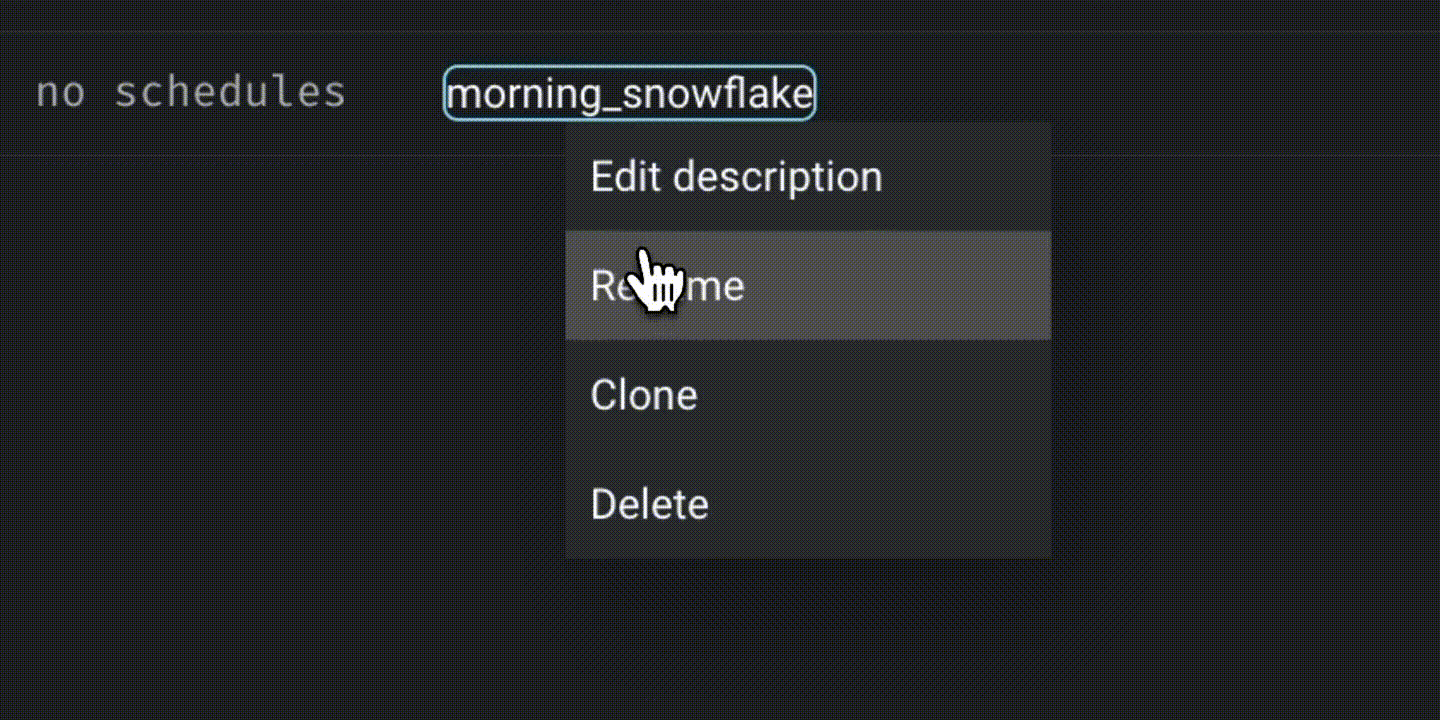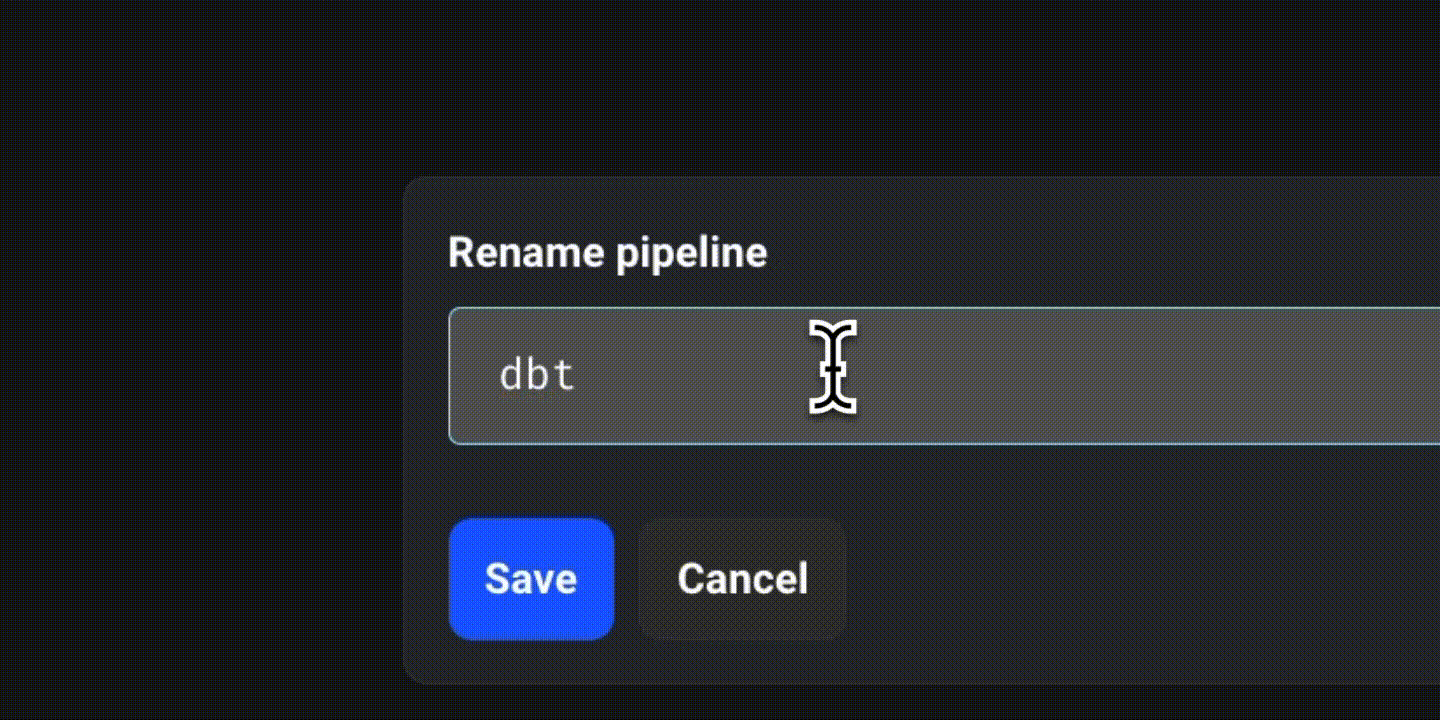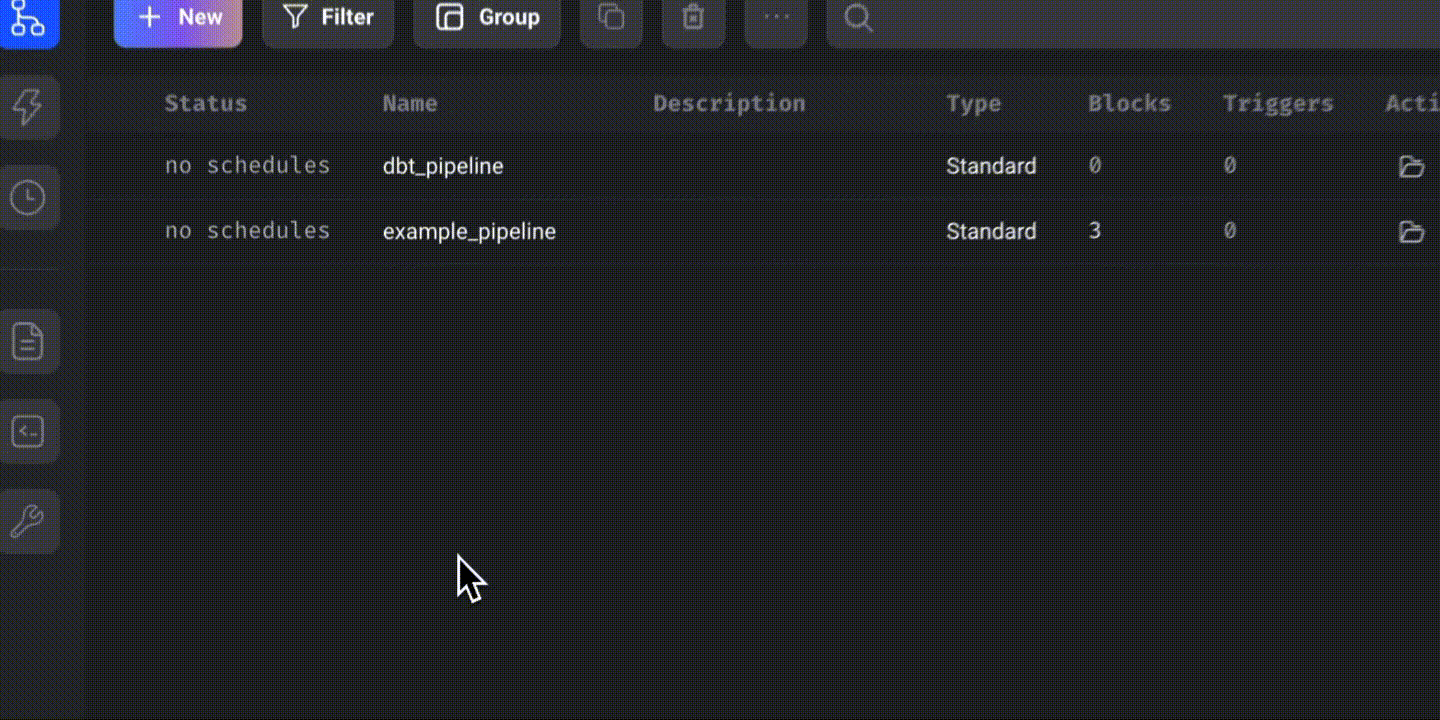
Open http://localhost:6789/ in your browser to view the Mage UI.
Click on “New” and select “Standard (batch)” to create a new batch pipeline. Rename it as “dbt_pipeline.”
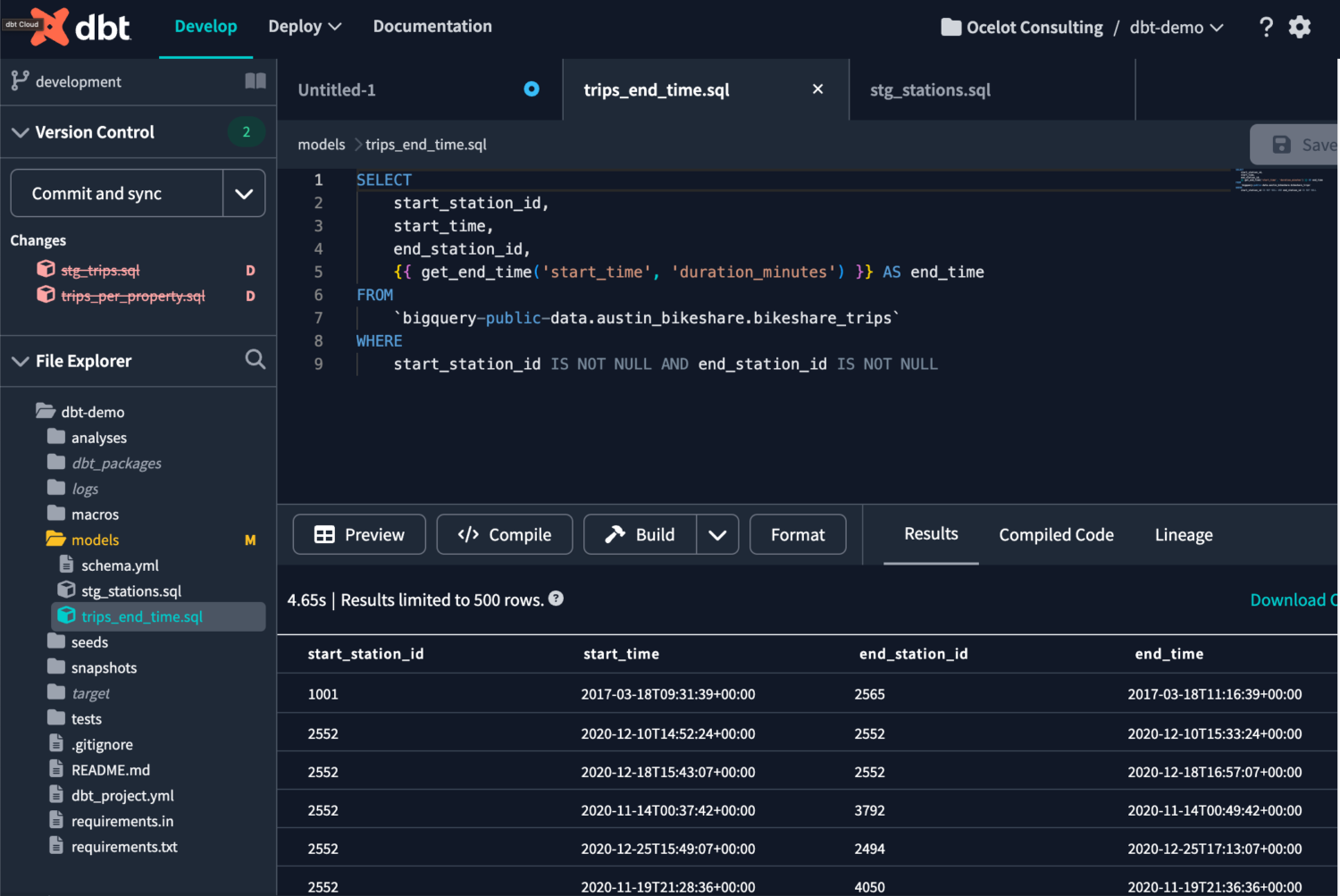
Install dependencies
Since we will use BigQuery as the data warehouse for dbt, we need to install dbt-bigquery by adding it to the “requirements.txt” file and clicking on “Install packages.”
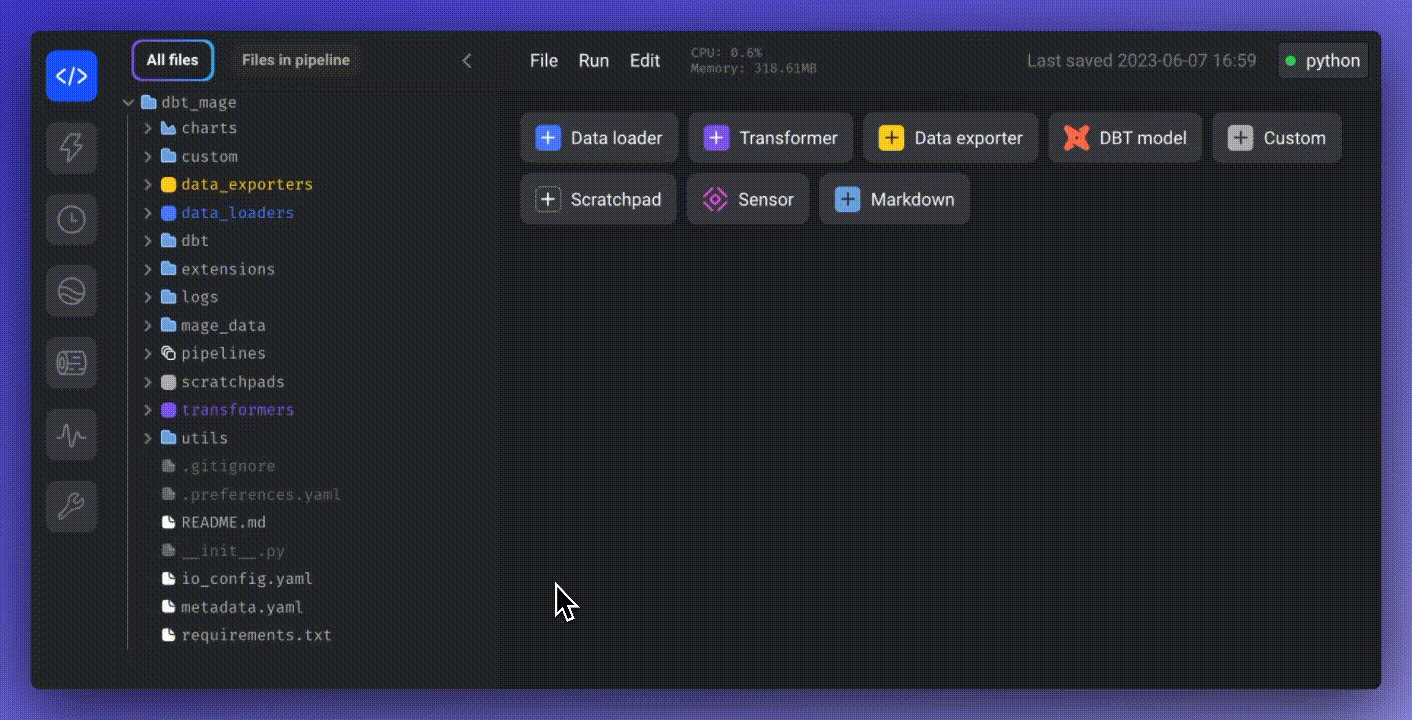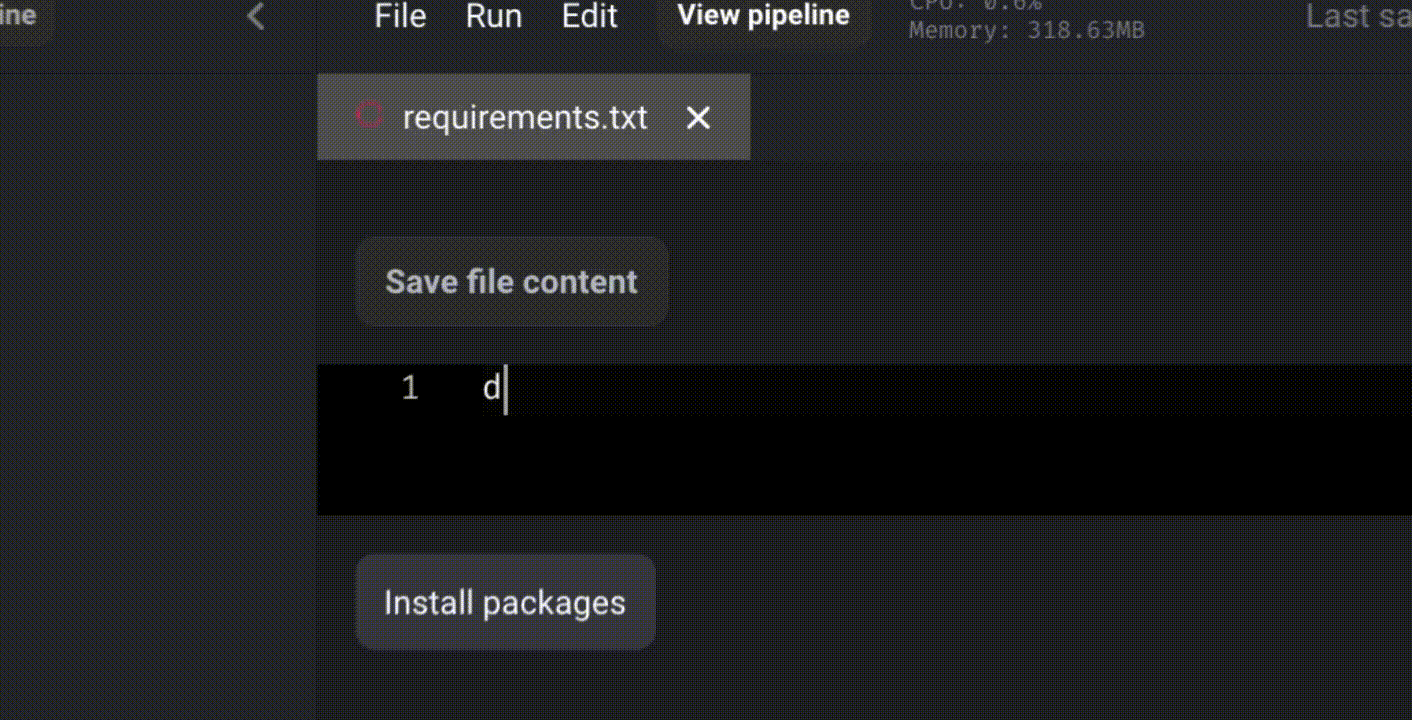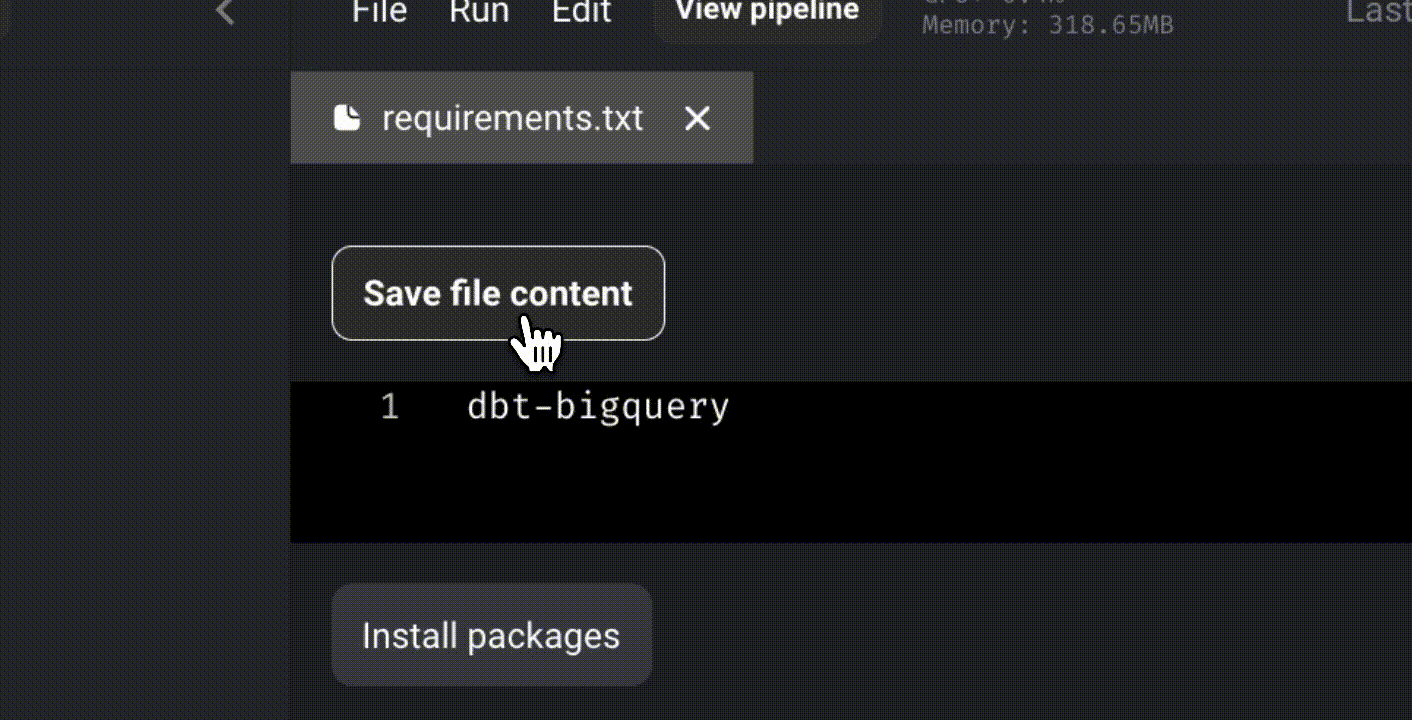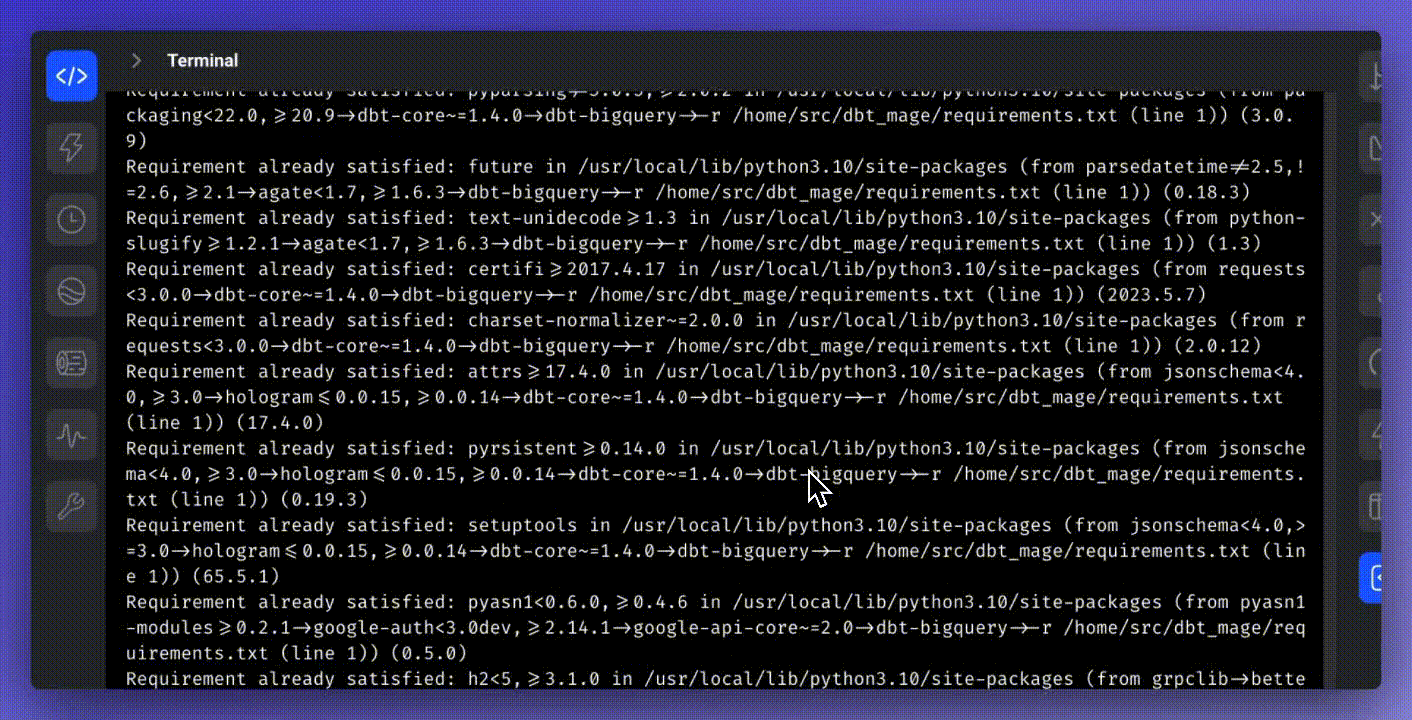
Create a dbt project
To create a dbt project, navigate to the right panel and click on the terminal button.
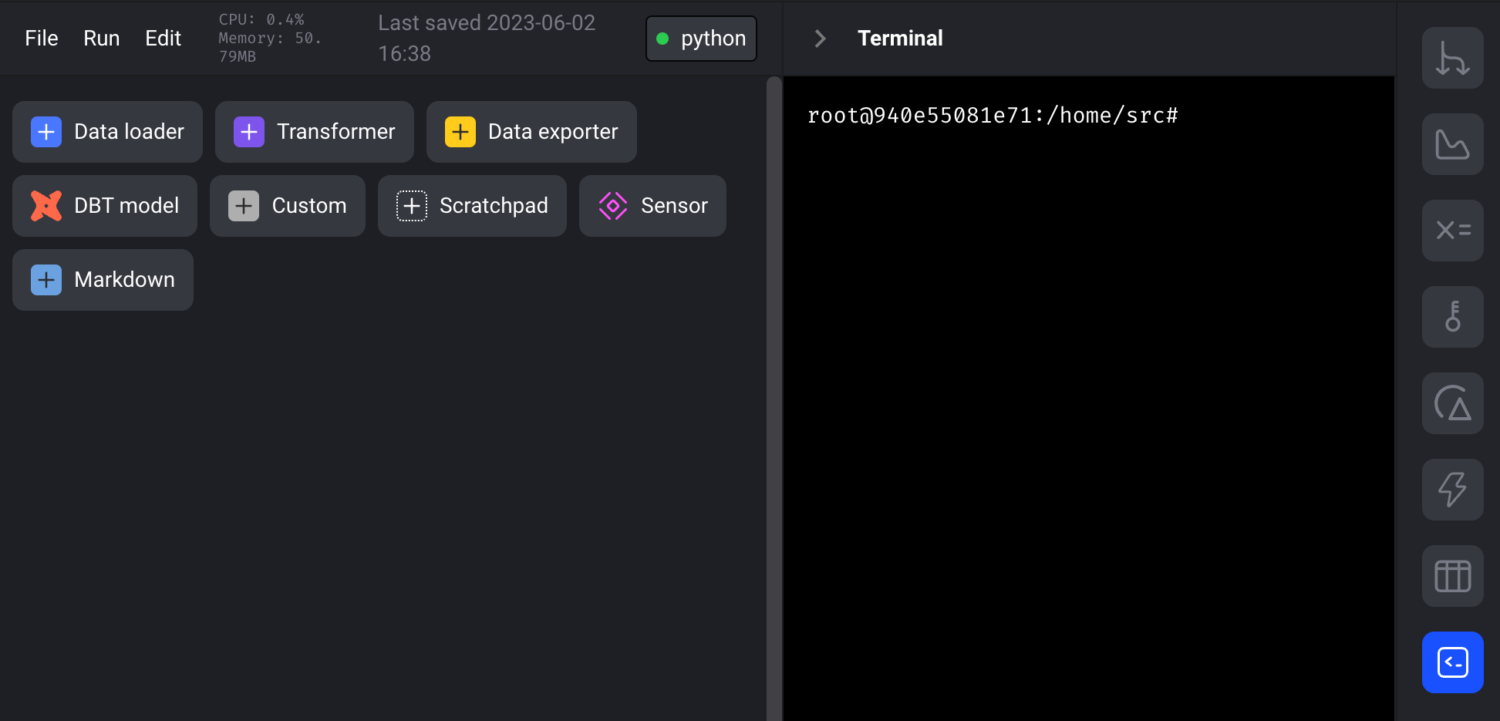
Move to the “dbt” folder and execute the command dbt init:
cd dbt_mage/dbt
dbt init demo -sThis command adds the “demo” folder to the dbt directory.

Right-click on the “demo” folder and create a new file named “profiles.yml.” Specify your BigQuery credentials in this file.
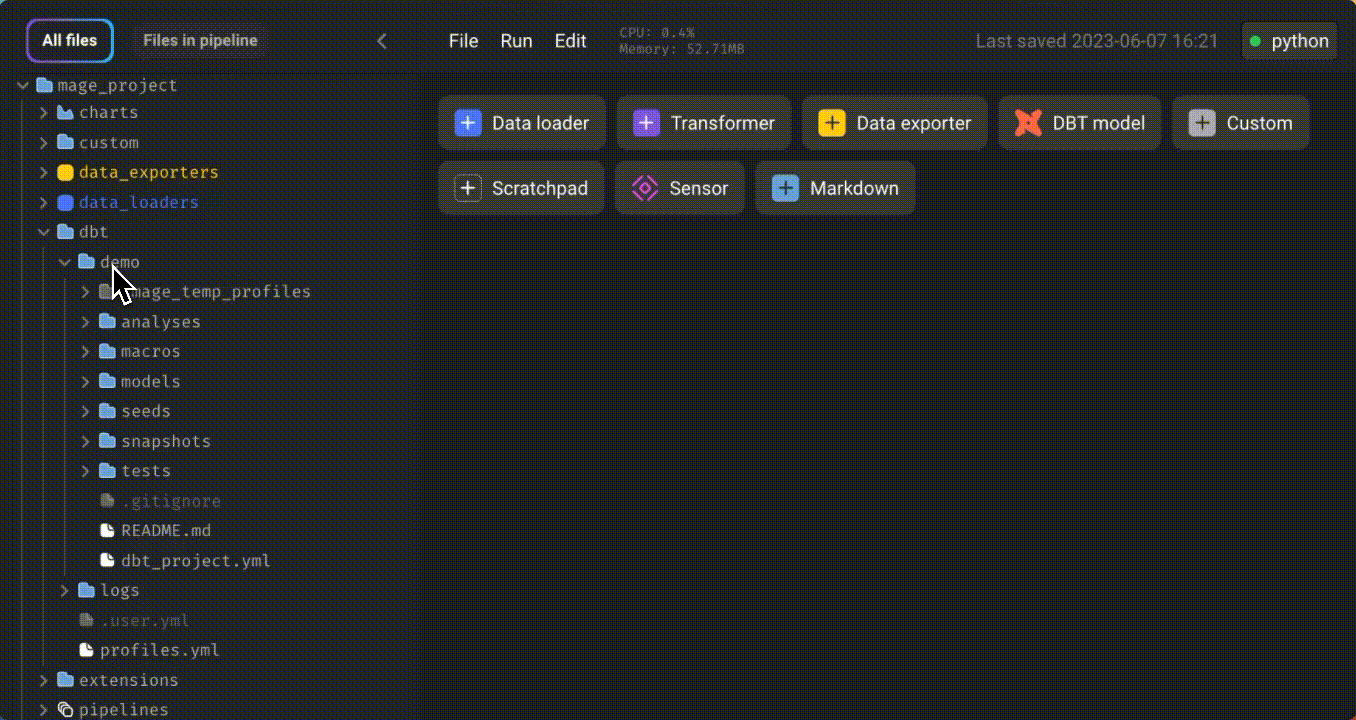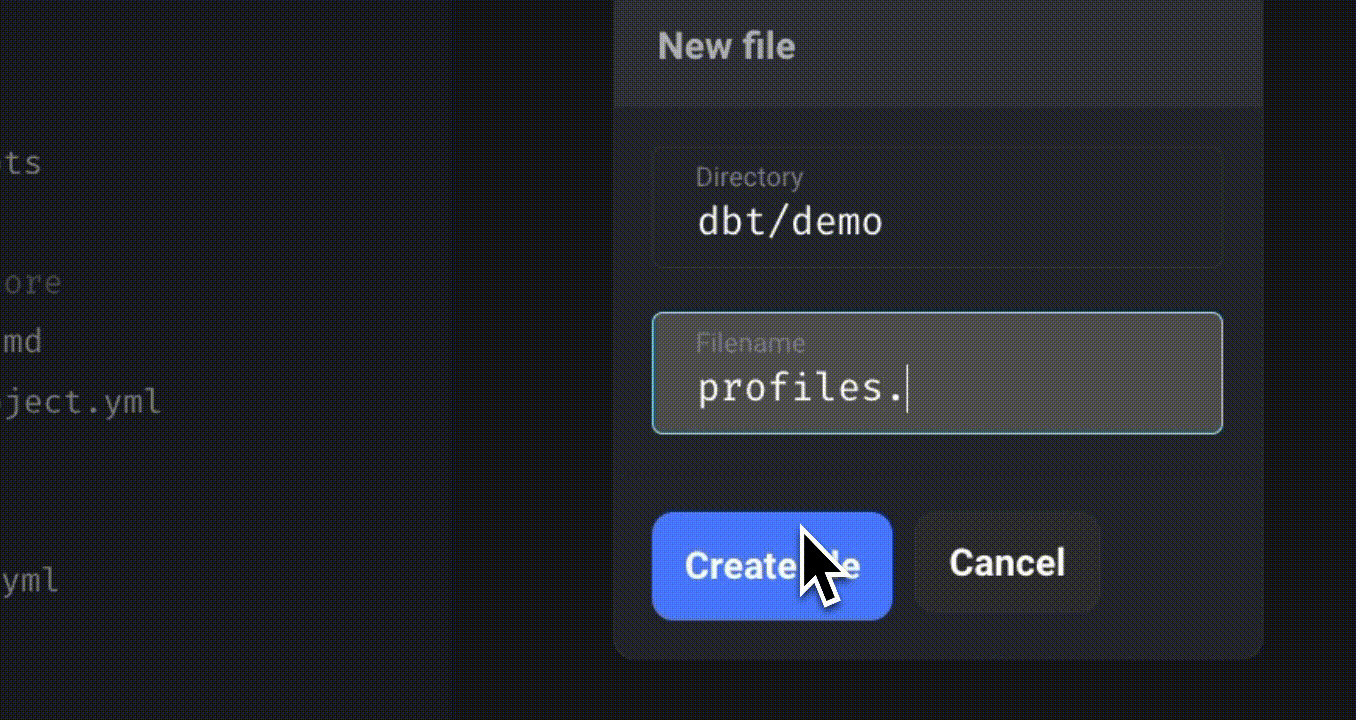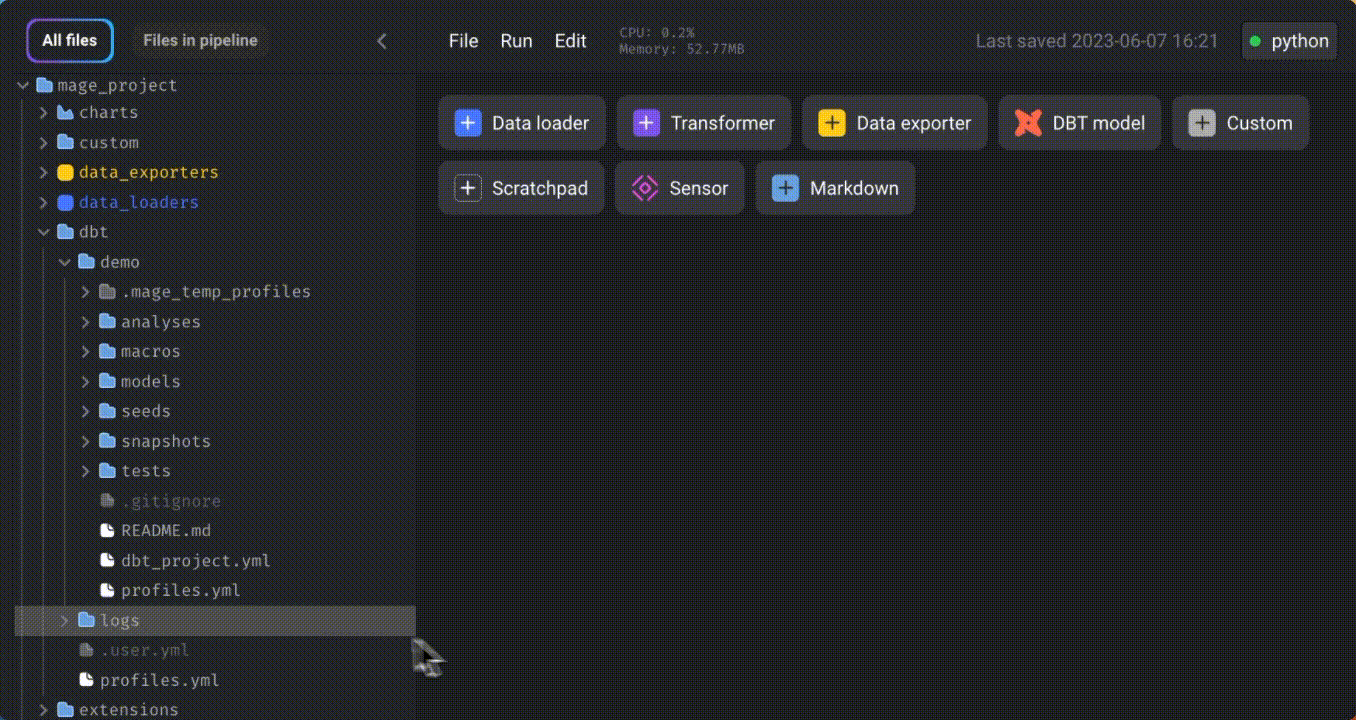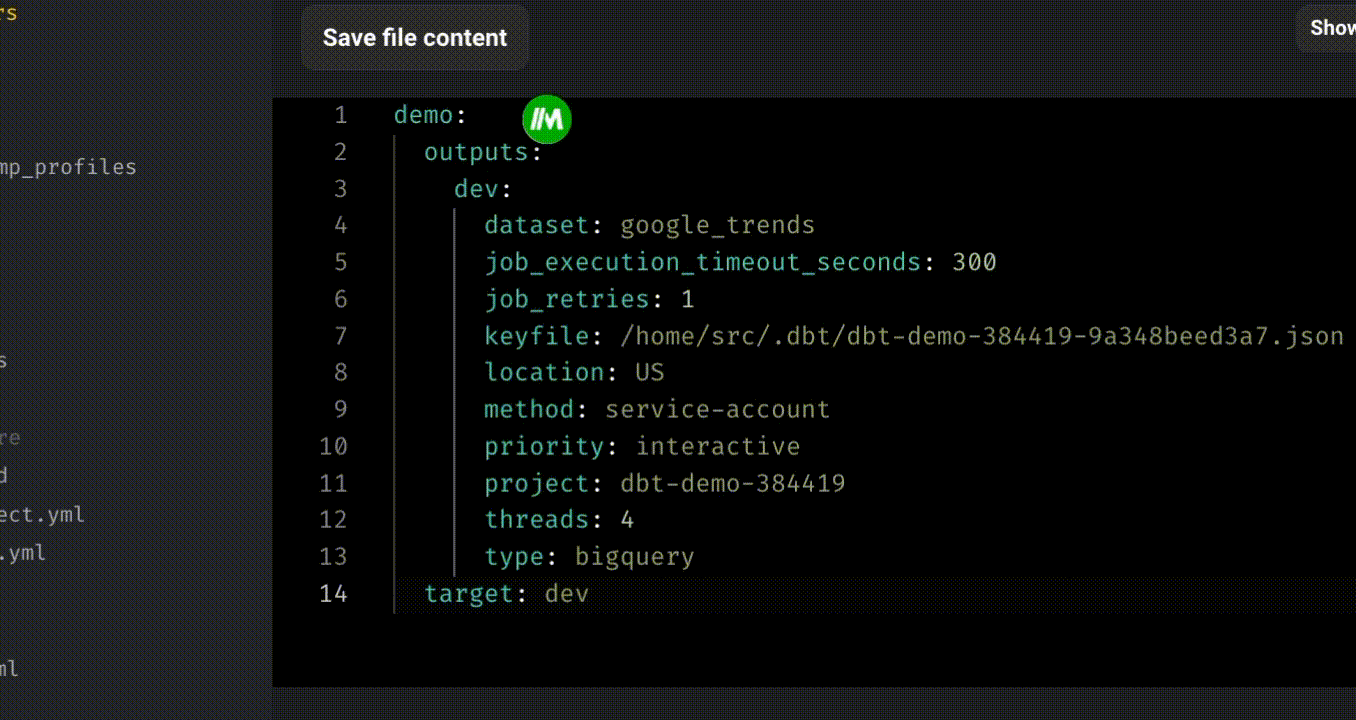
Refer to this documentation for instructions on specifying credentials for other data platform providers.
Now that the setup is complete, we are ready to explore the exciting features of Mage!
Integrated Web-based IDE
Mage offers a user-friendly web-based UI that simplifies the creation of dbt models. Its unique feature of using blocks allows for interactive code development, similar to working in a Jupyter notebook. Each block functions as an independent executable code file.
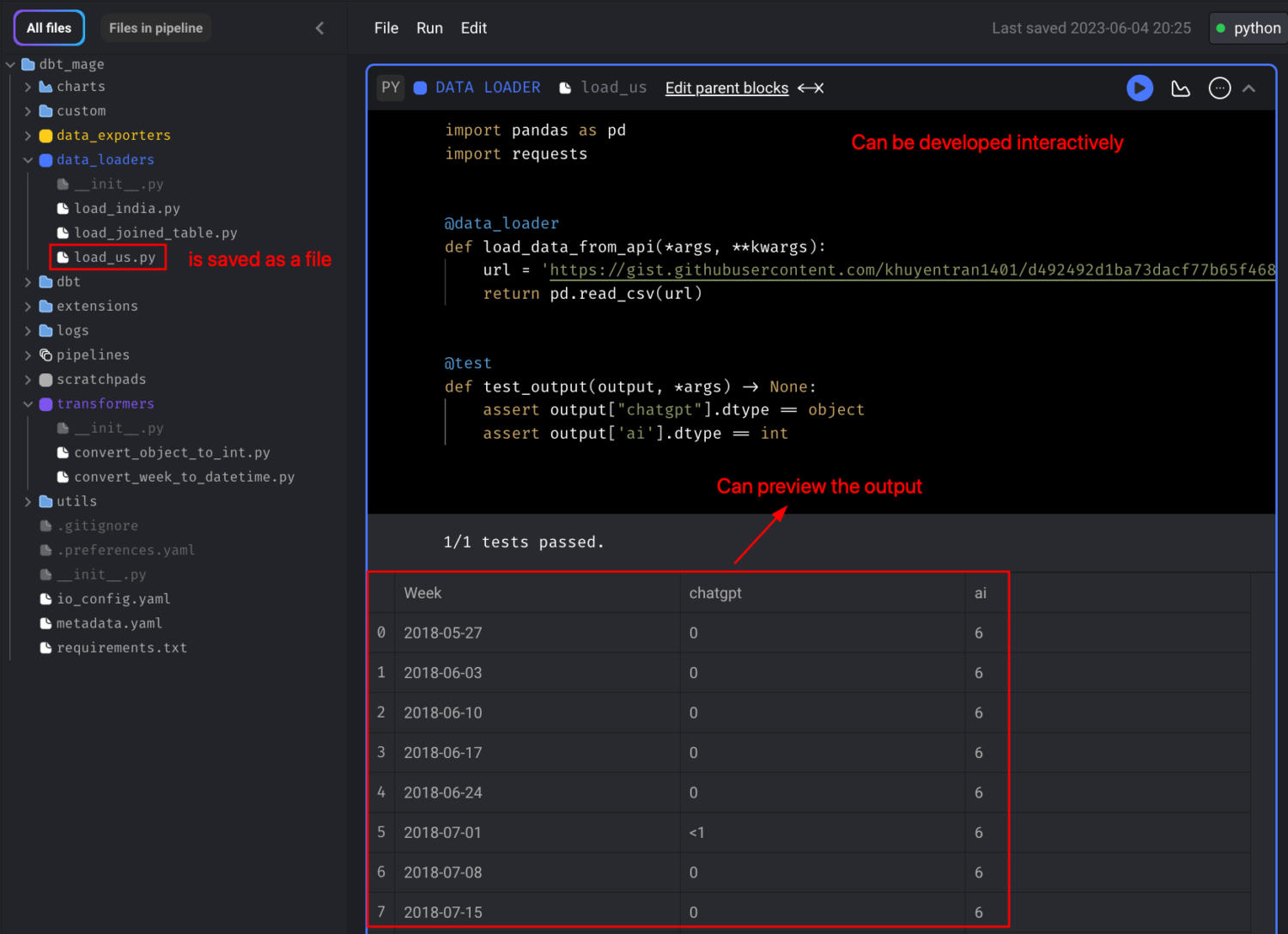
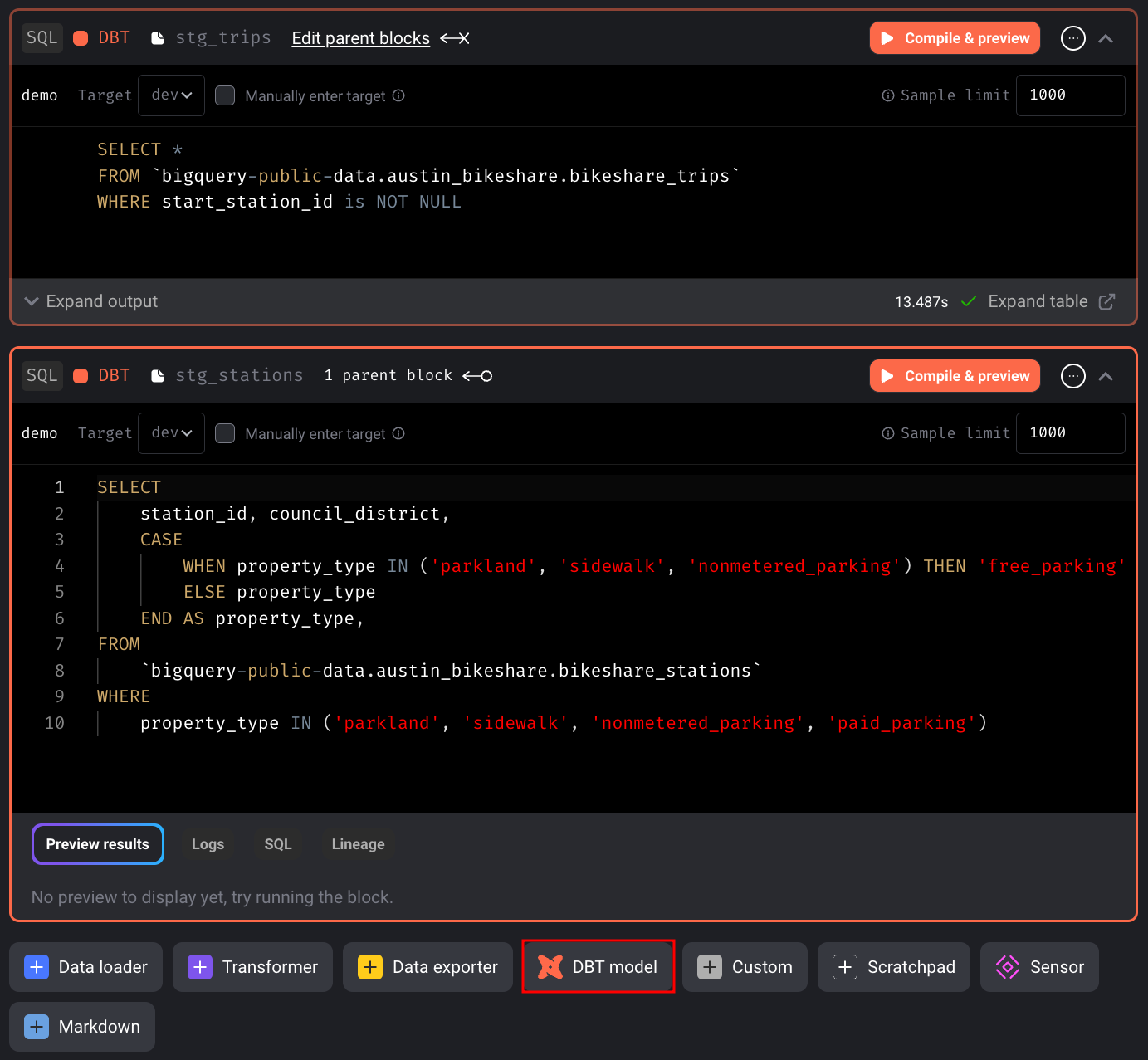
To create a new dbt model, click on “DBT model” and provide the name and location.

Write your query and click “Compile & preview” to preview the query results.
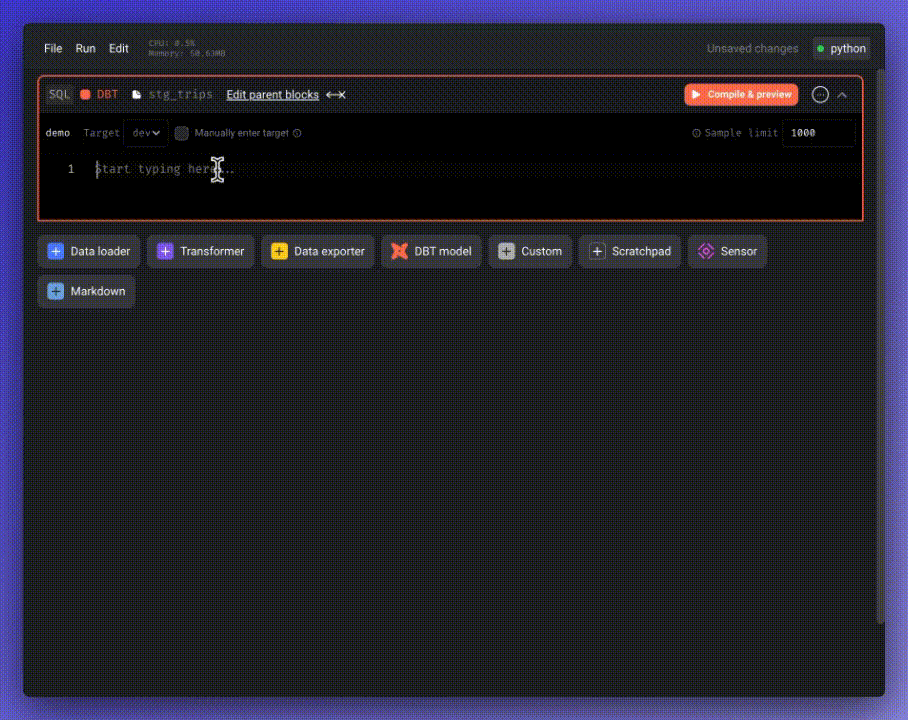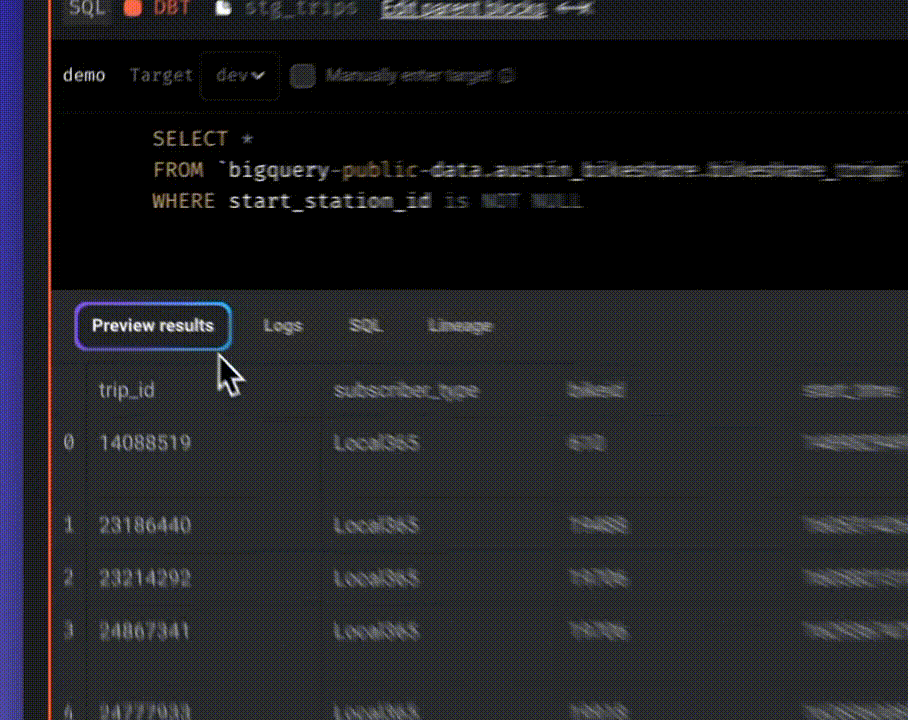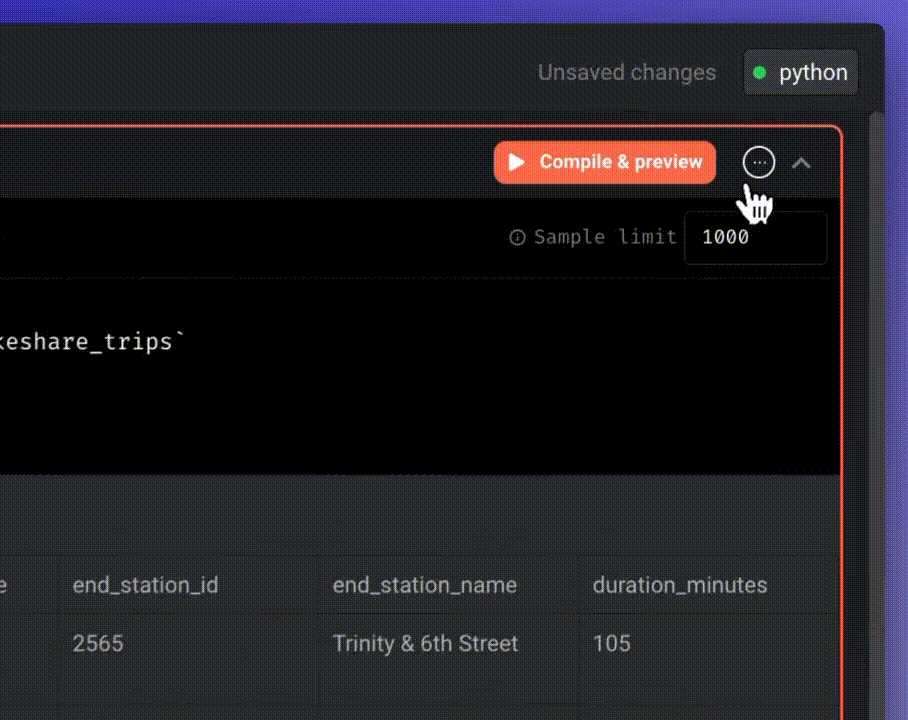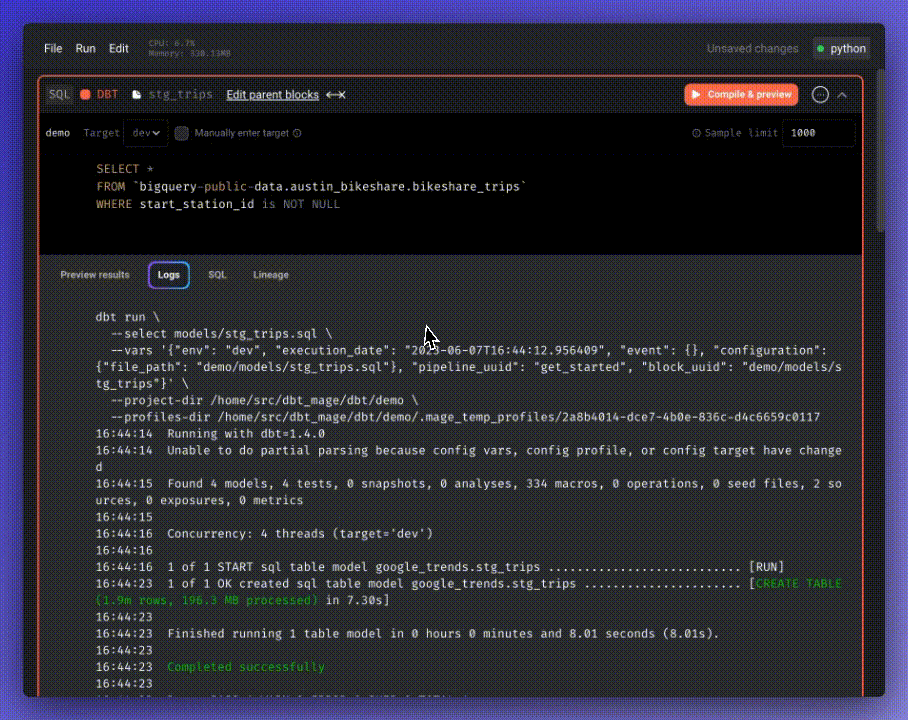
After previewing the result, execute the model by clicking the three-dot icon and selecting “Run model.”
You can create additional models within the same editor by clicking “DBT model” again.
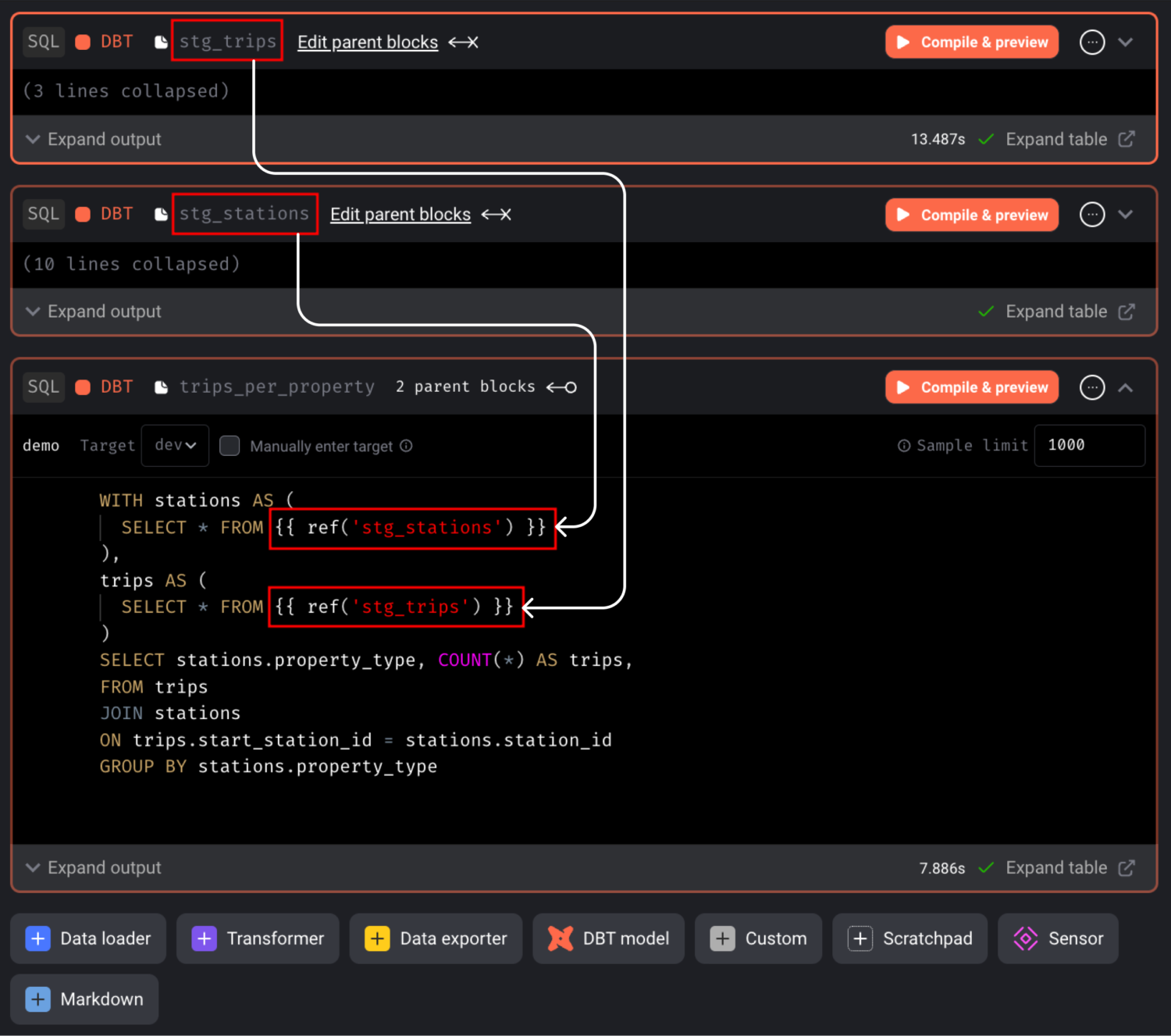
Use {{ ref('model_name') }} to reference one model within another, just like in dbt.
Language Flexibility and ETL Functionalities
Mage empowers you to combine dbt models with other languages, including Python, R, or SQL, for data loading, transformation, and exporting purposes.
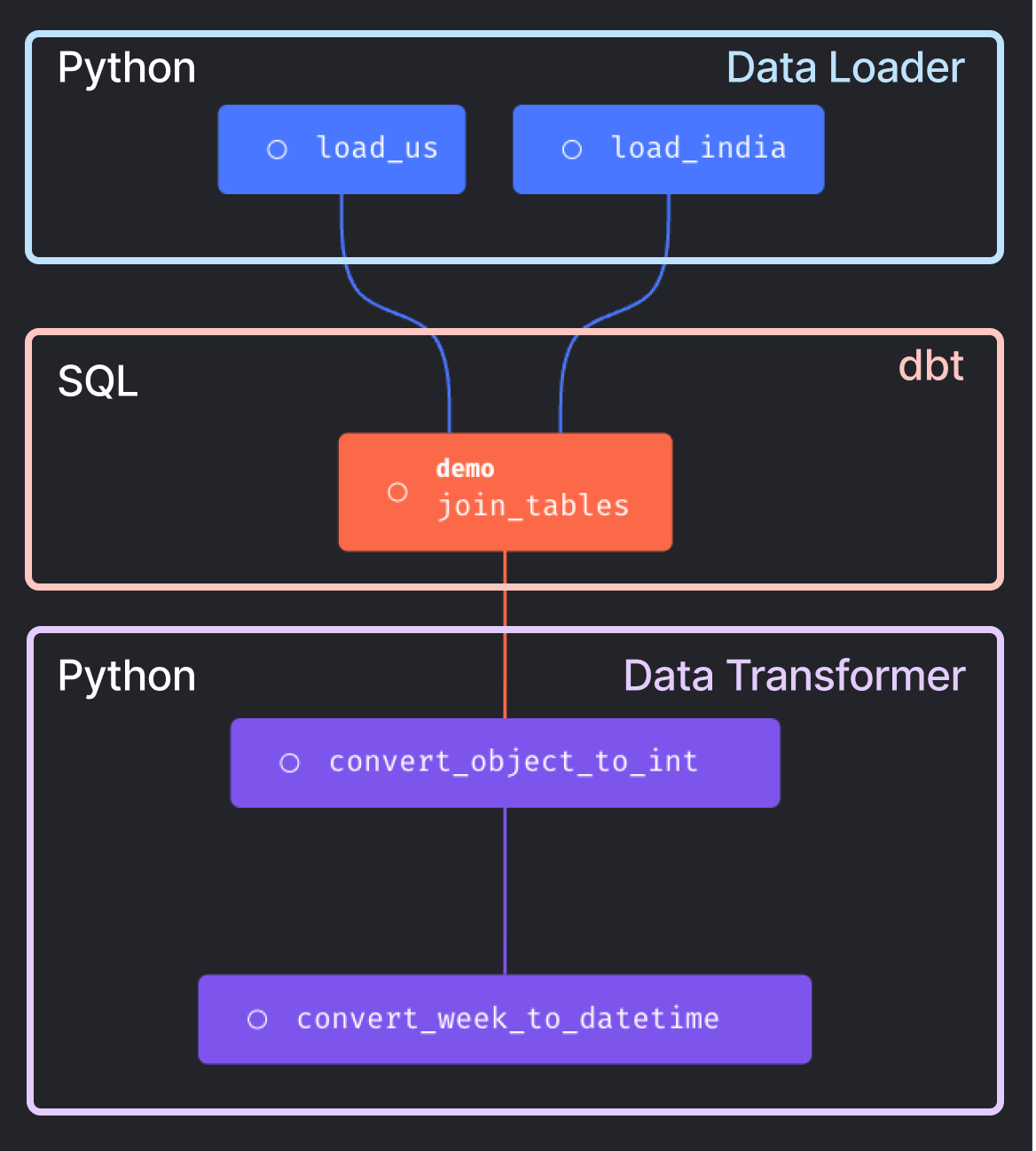
As an example, let’s create two Python data loaders—one for US data and one for India data.
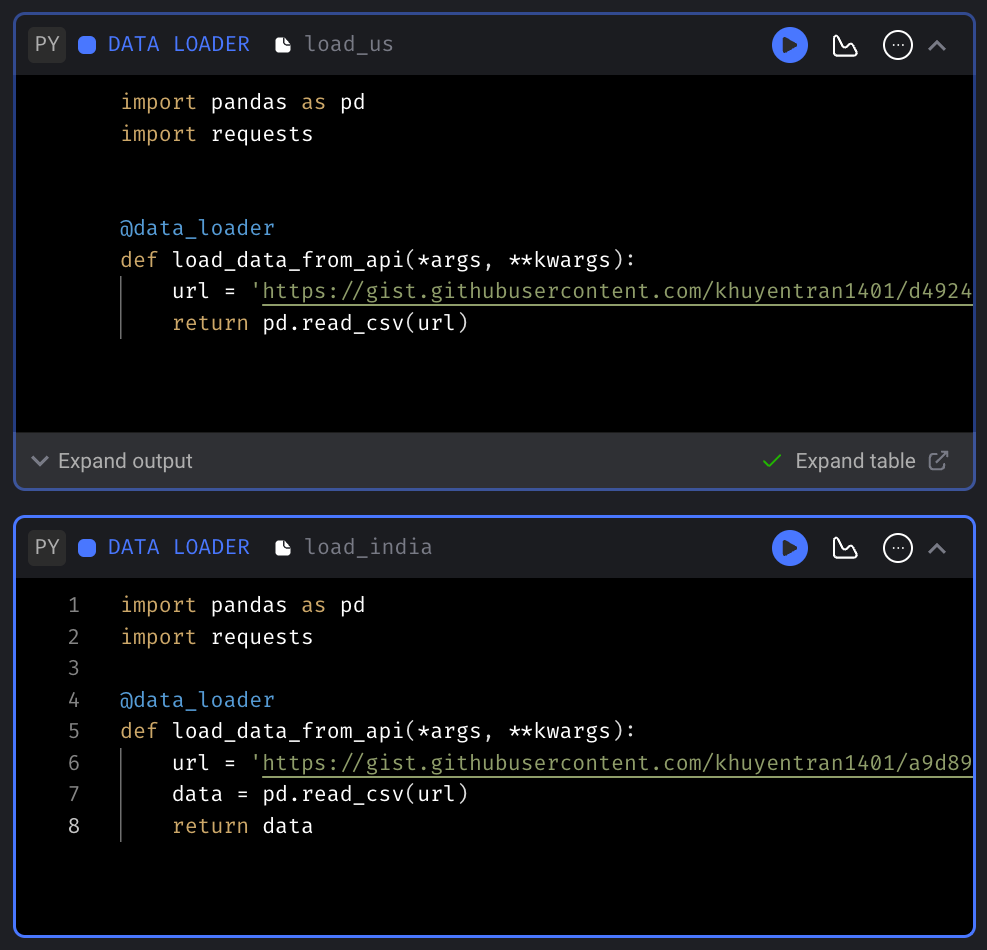
We’ll then incorporate a dbt block to join the outputs of these data loaders. Set the parent blocks of the join_tables block by clicking “Edit parent block” and choosing the data loaders blocks.
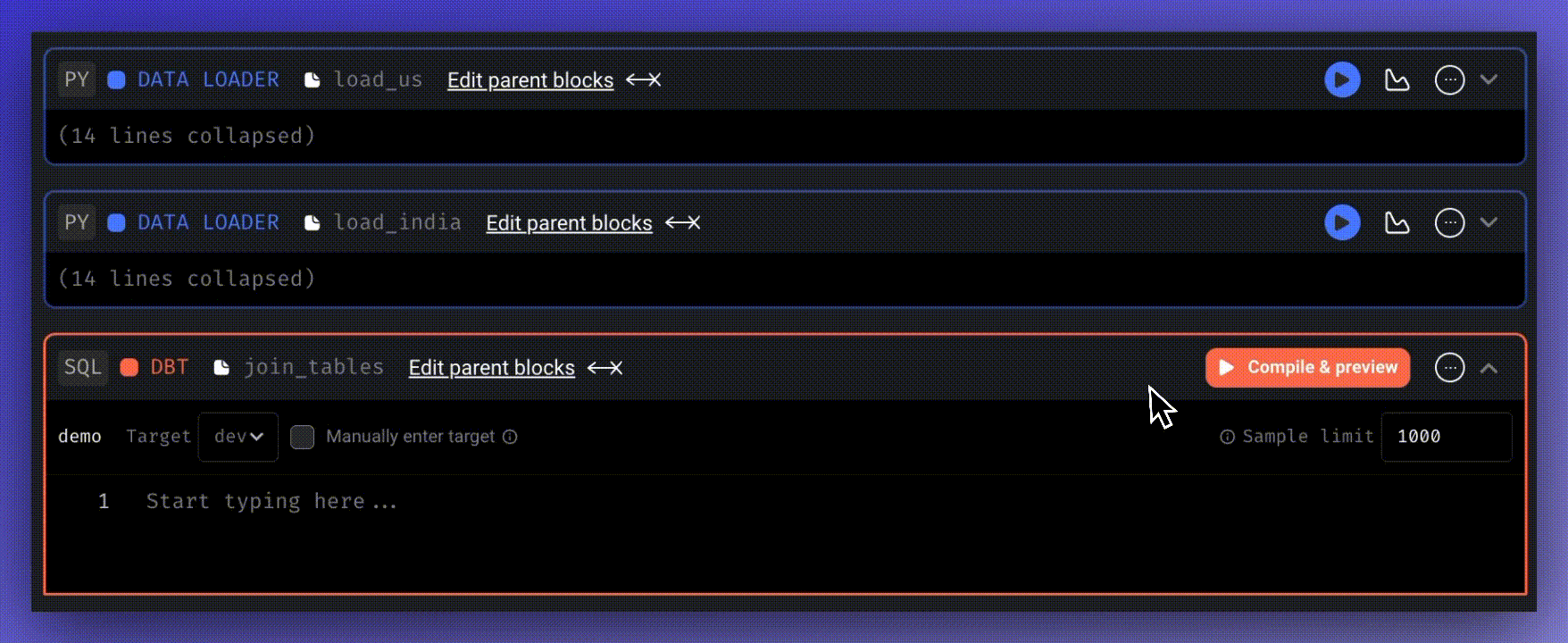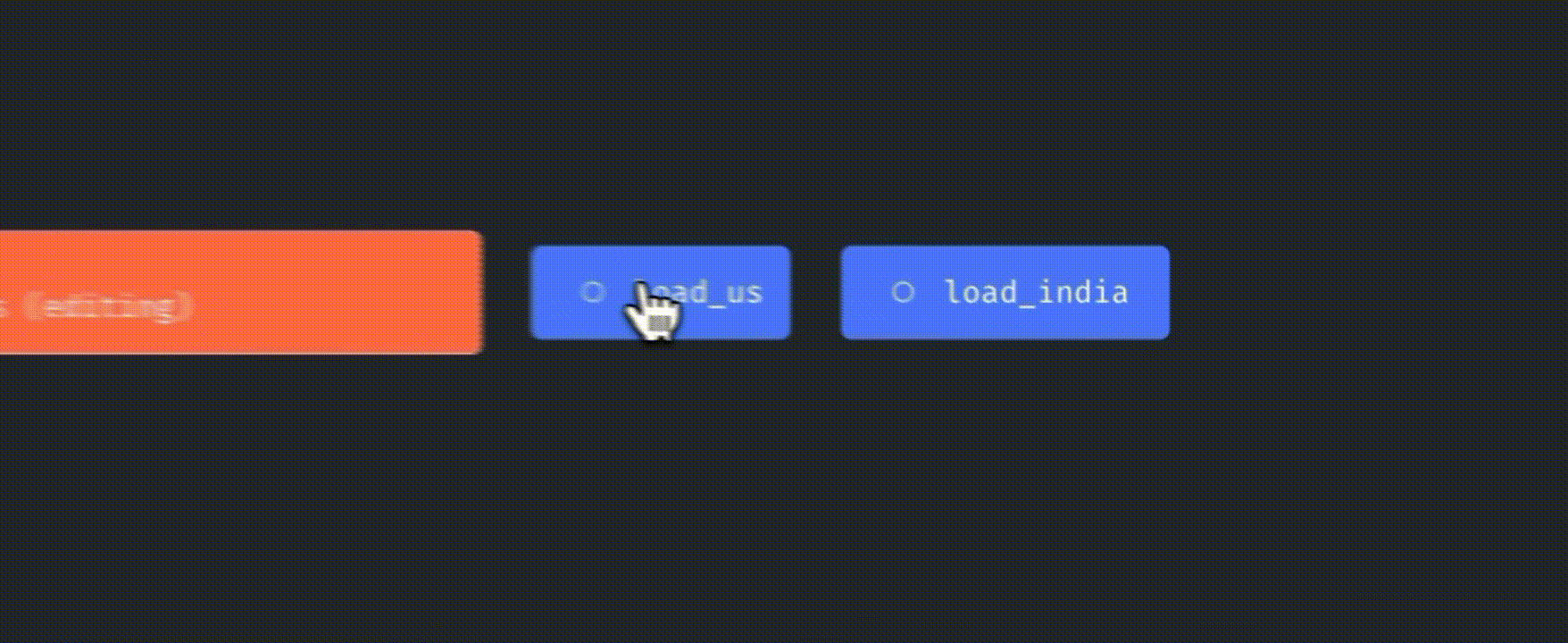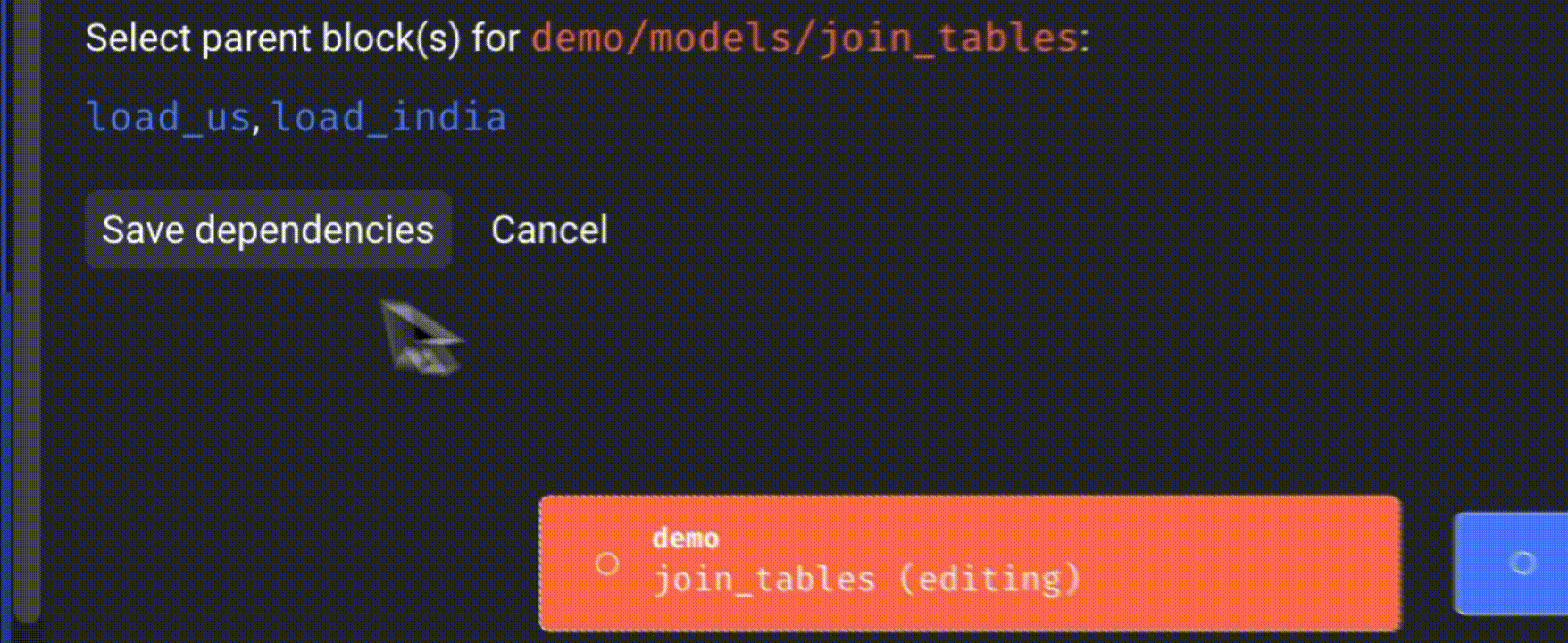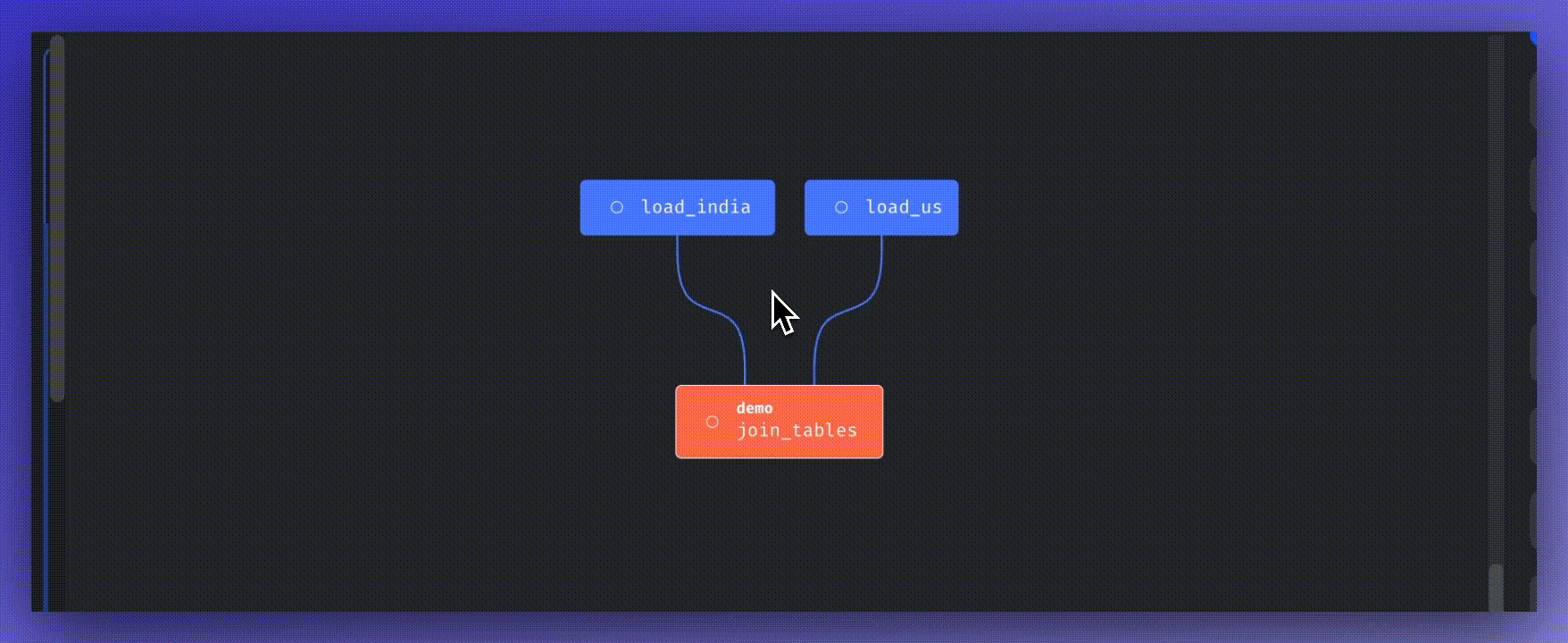
When a dbt model depends on a non-dbt upstream block, Mage automatically adds a source for that block to the “dbt/demo/models/mage_sources.yml” file.
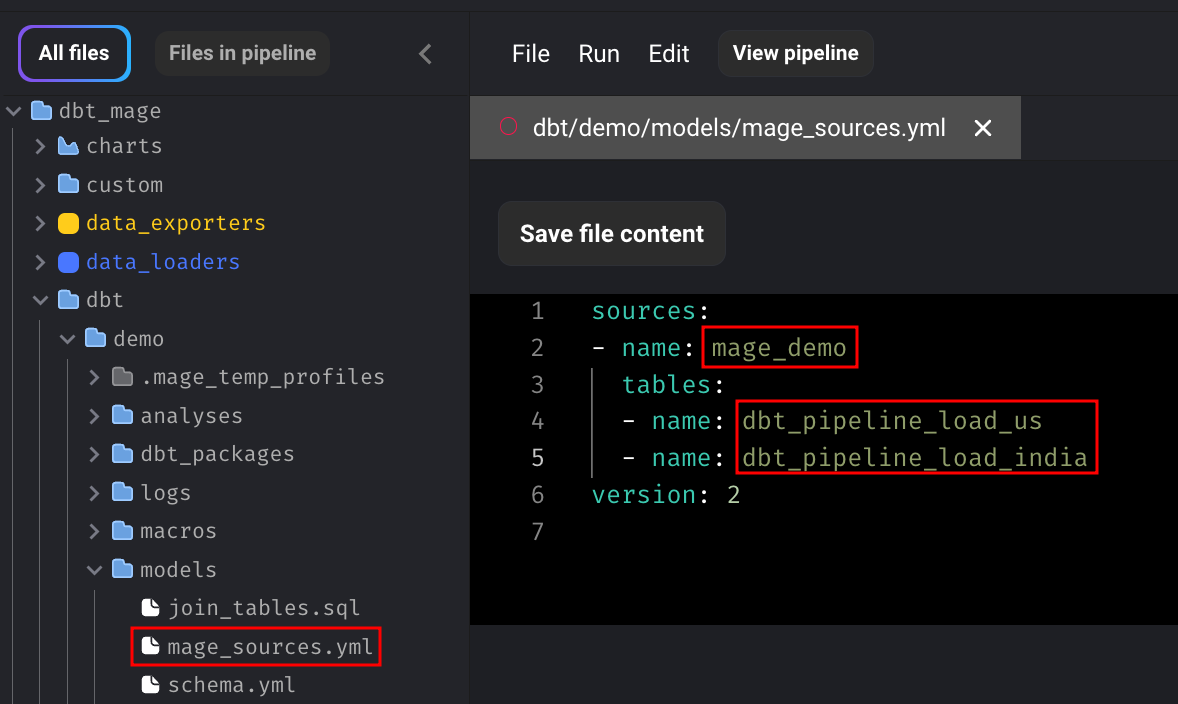
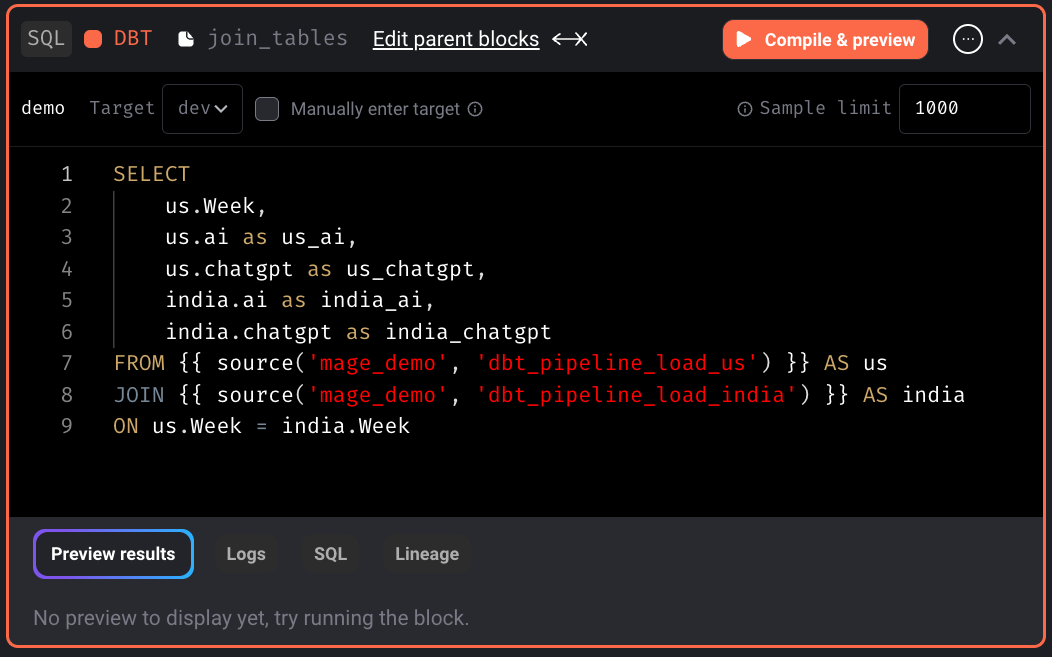
You can now utilize the outputs of the Python blocks within the dbt block.
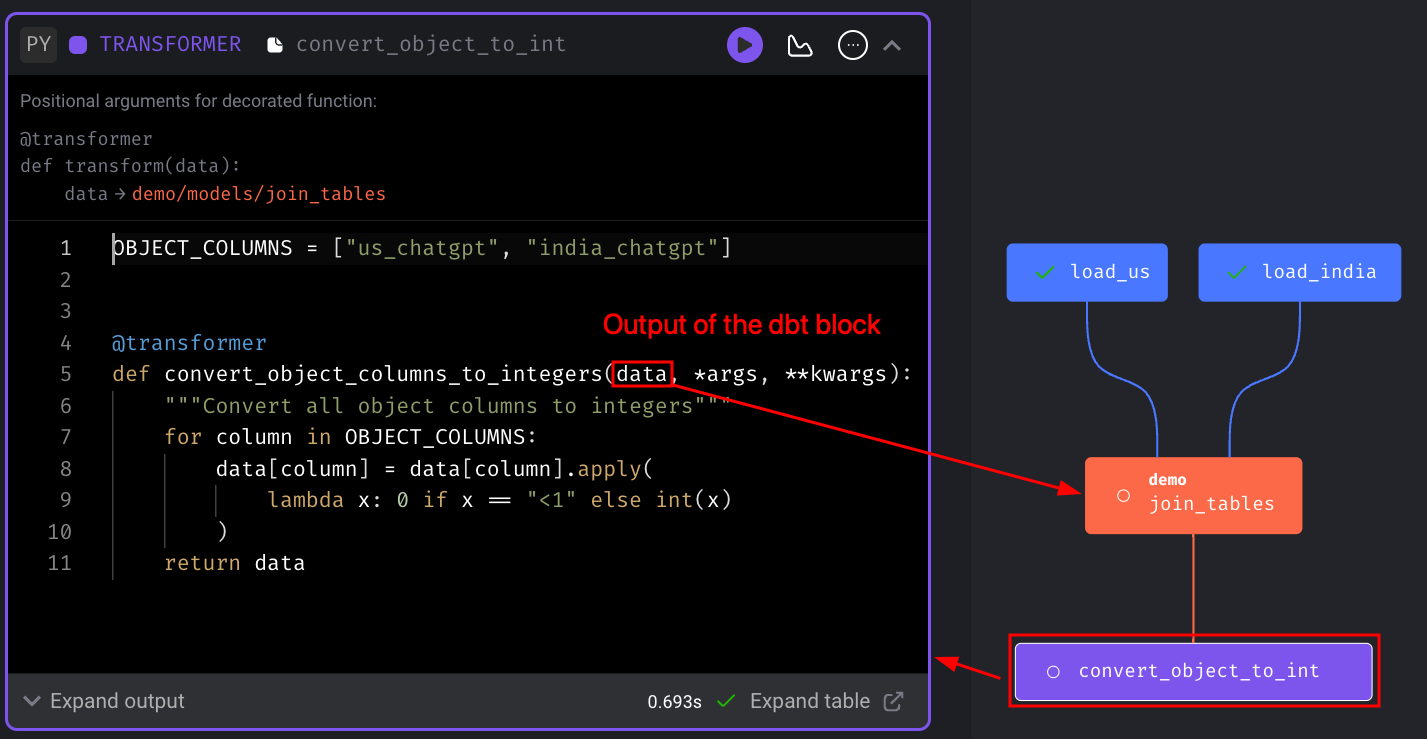
We can then set a transformer block, named convert_object_to_int, as the downstream block of join_tables to process its output.
Visualizing dbt Model Output
While traditional tools like Tableau can be used for visualization, Mage offers a consolidated solution for processing and analyzing the output of a dbt block in one place.
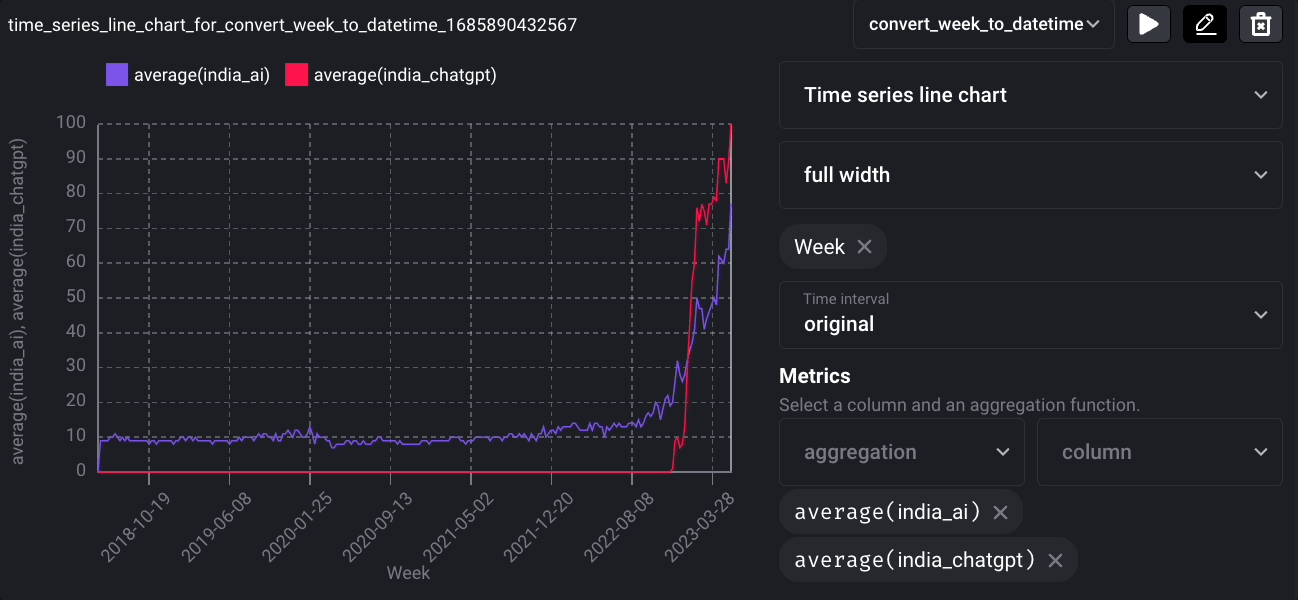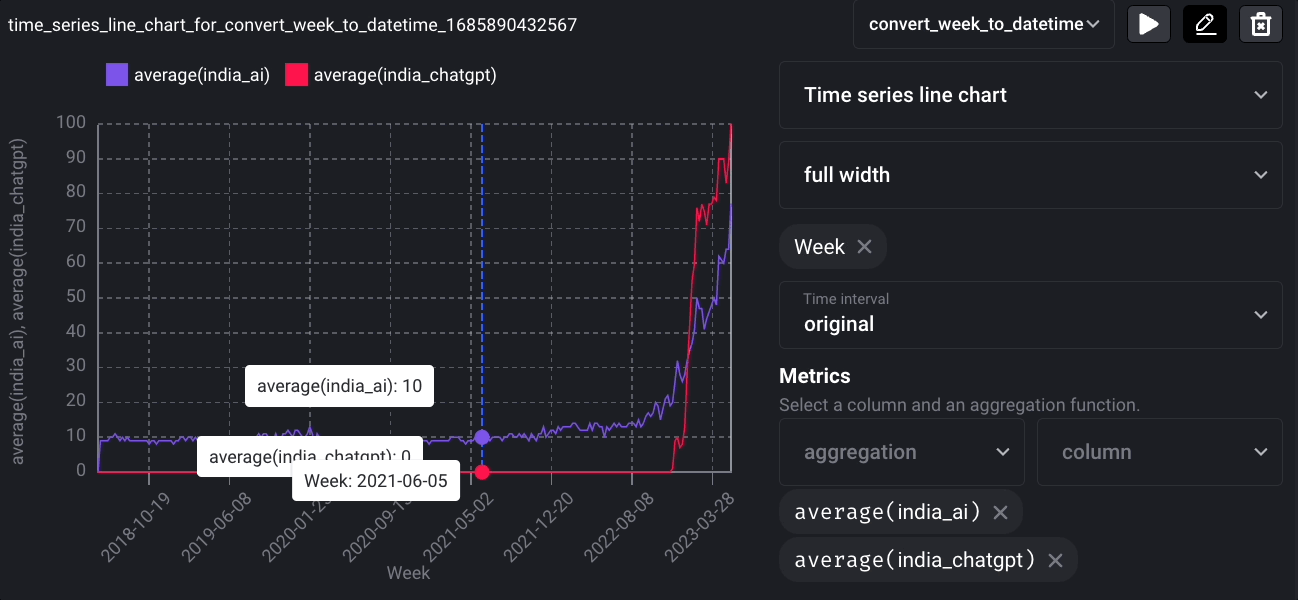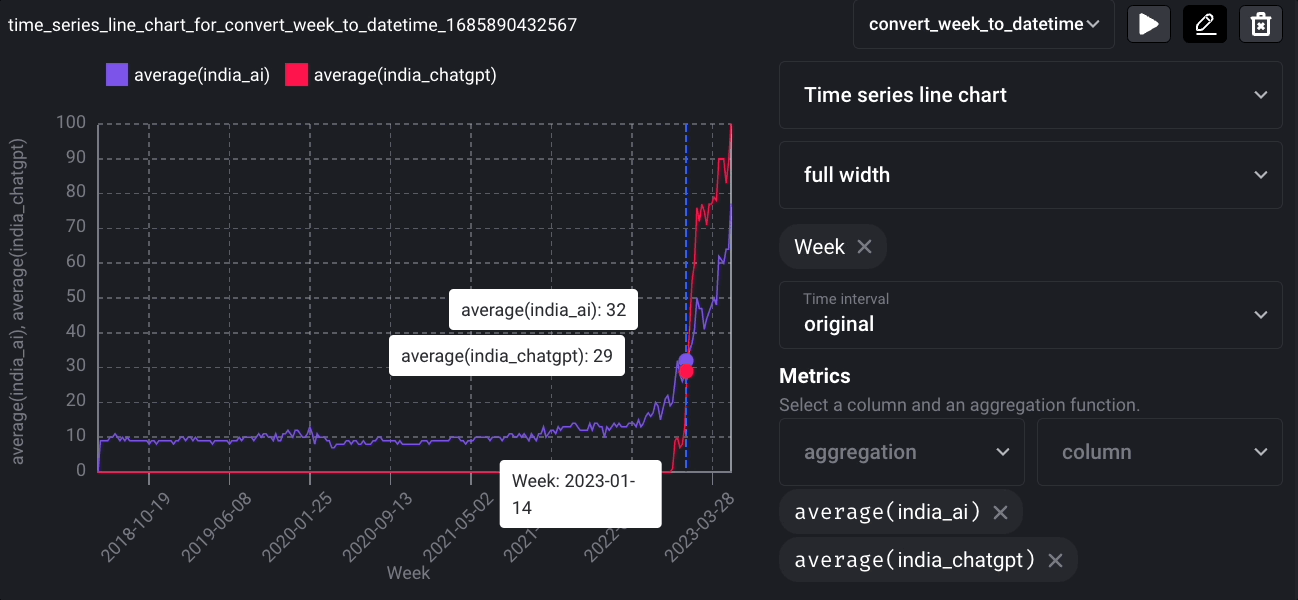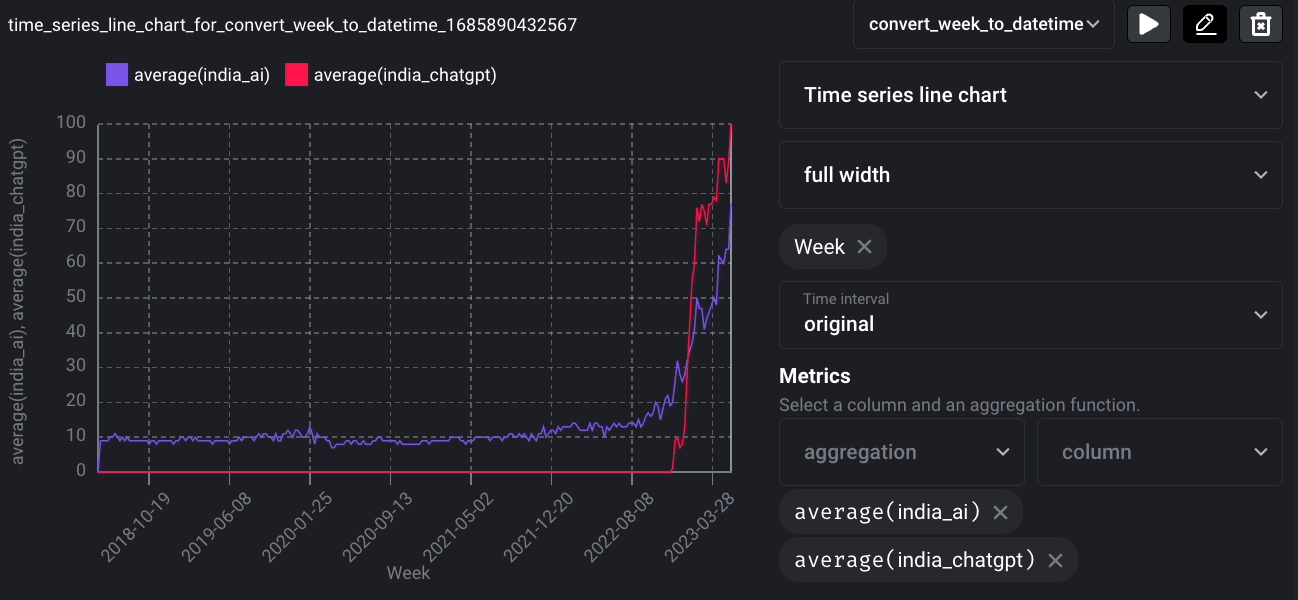
To demonstrate this, let’s create another block called convert_week_to_datetime, which converts the Week column to a datetime type.

Click the “Add chart” icon, select “Time series line chart,” and create a time series visualization.

And you will see the following line chart:
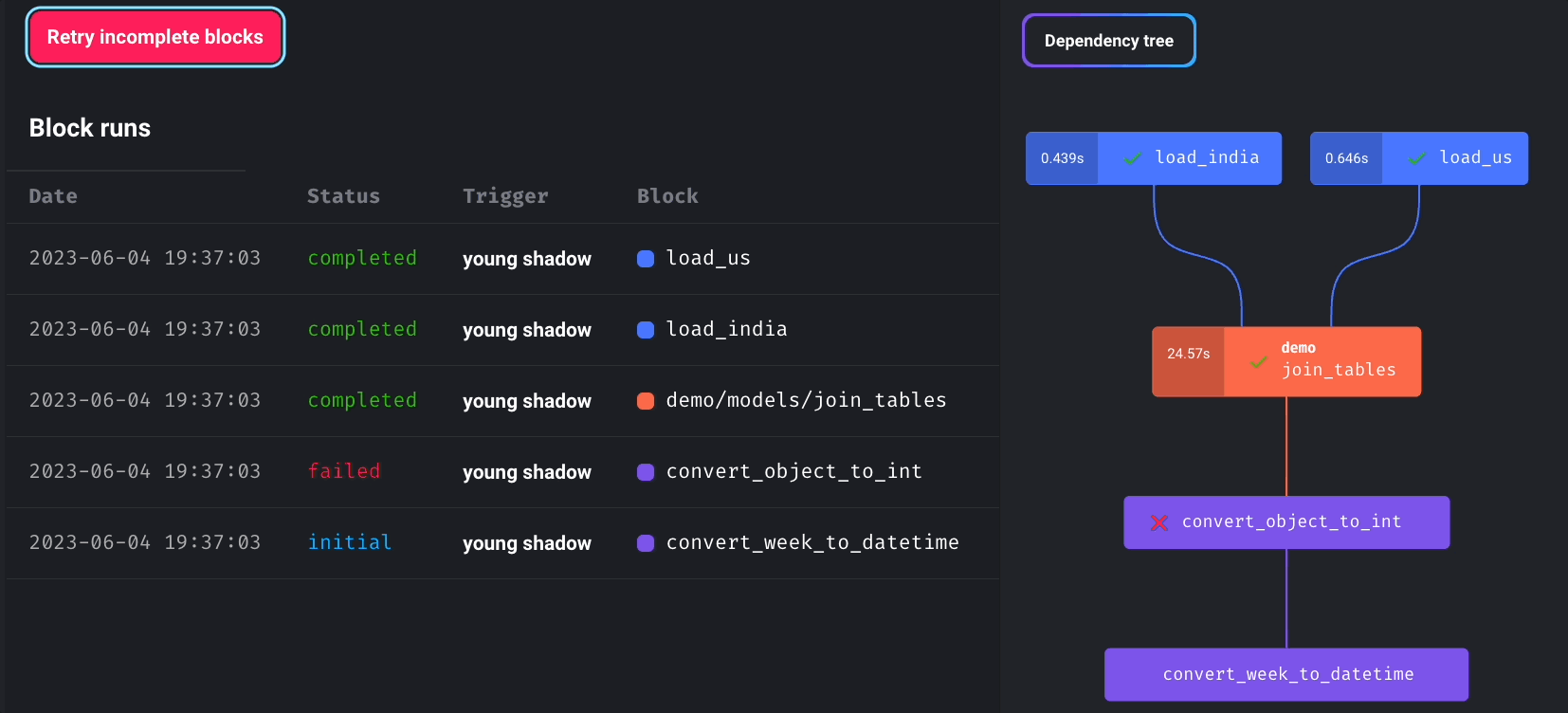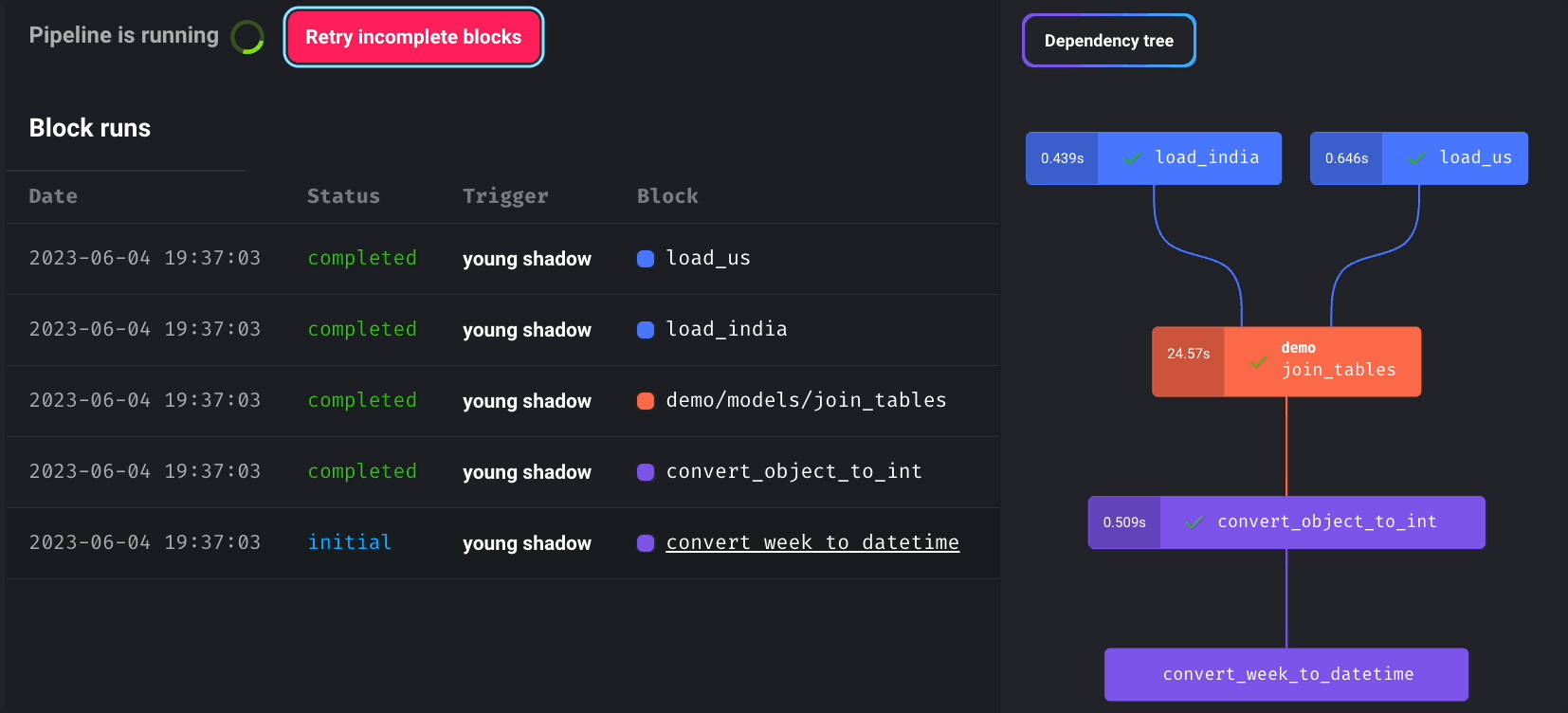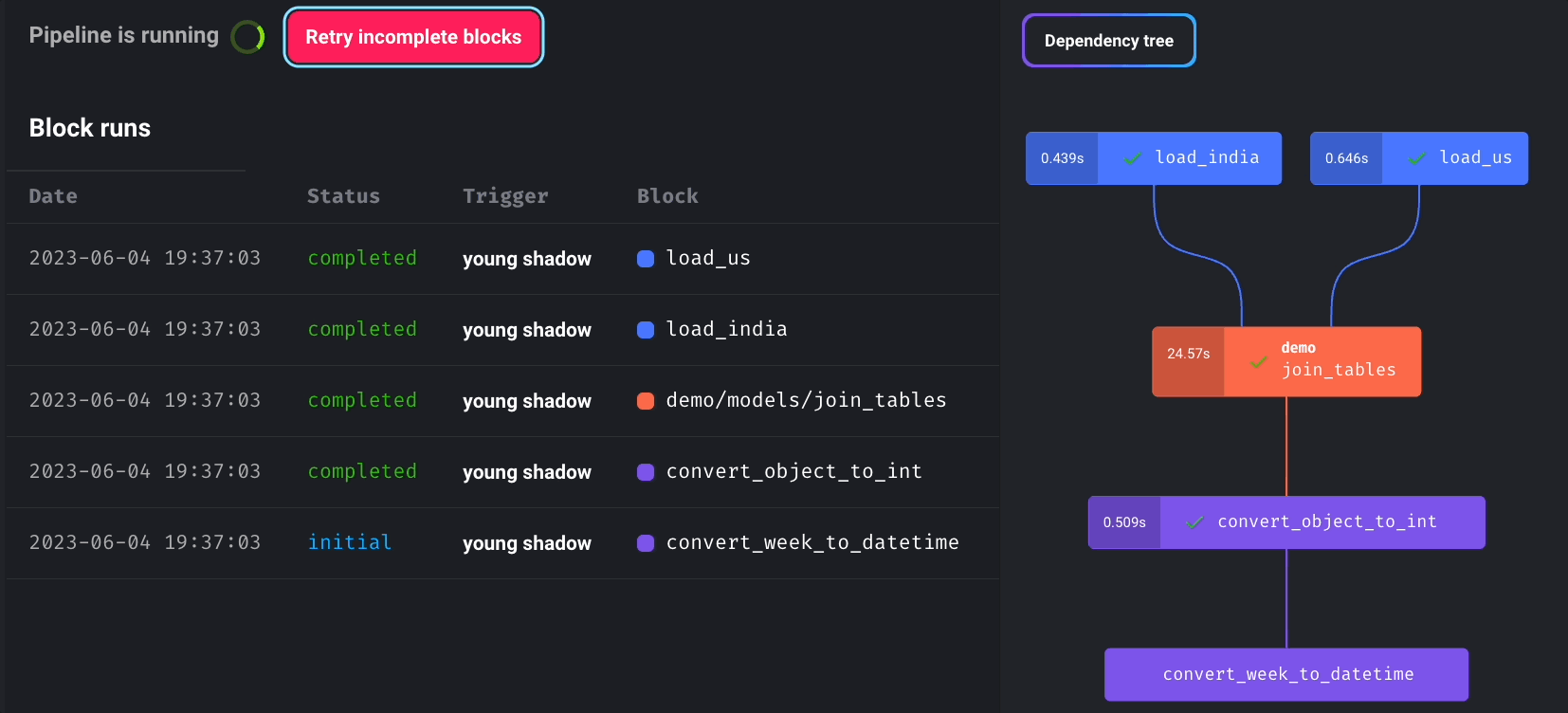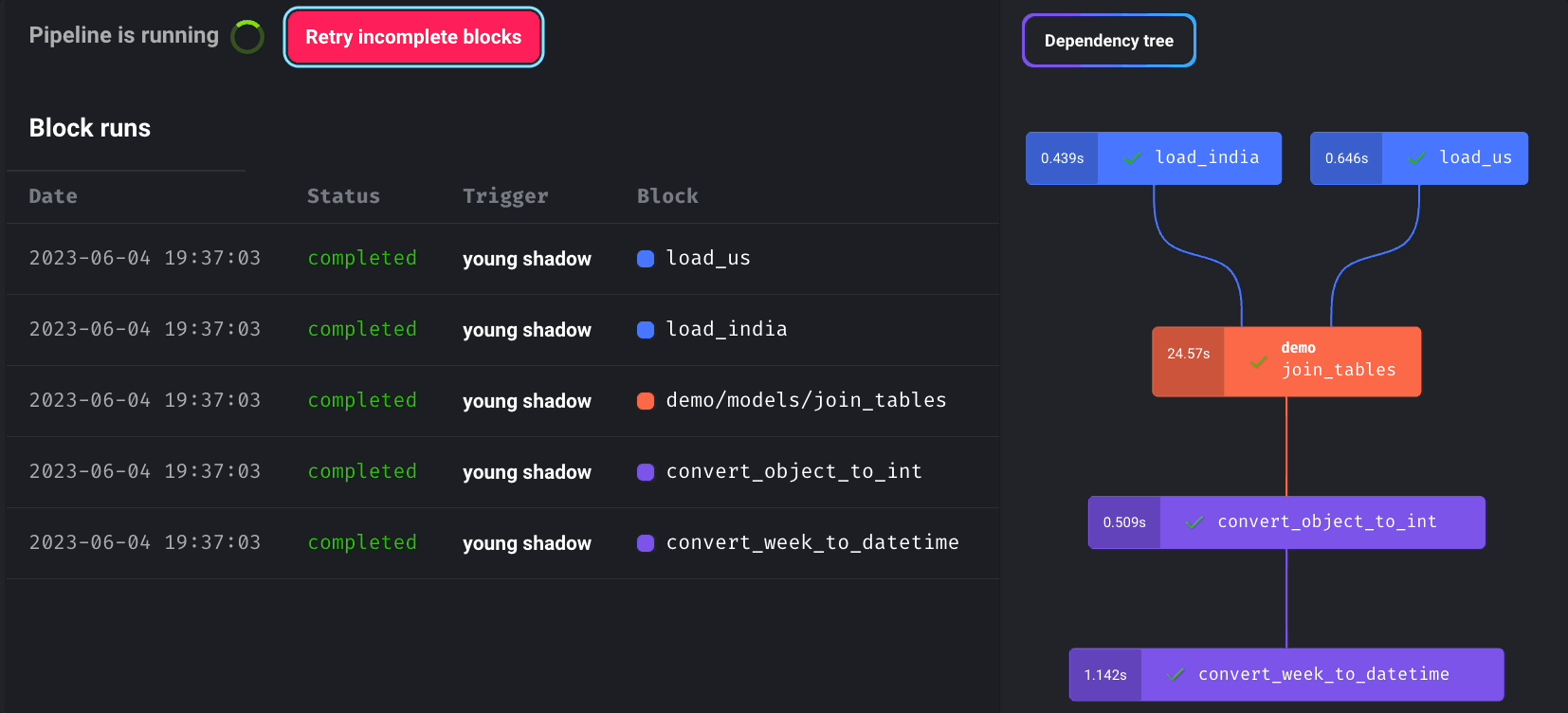
Pipeline Scheduling and Retry Mechanism
Mage enables you to schedule pipeline runs and incorporates a retry mechanism for failed blocks without rerunning the entire pipeline.
To execute a pipeline immediately, click the “Triggers” icon on the left panel, and select “Run pipeline now.”
You can monitor the real-time status of all block runs by choosing the newly created pipeline trigger and clicking “See block runs.”
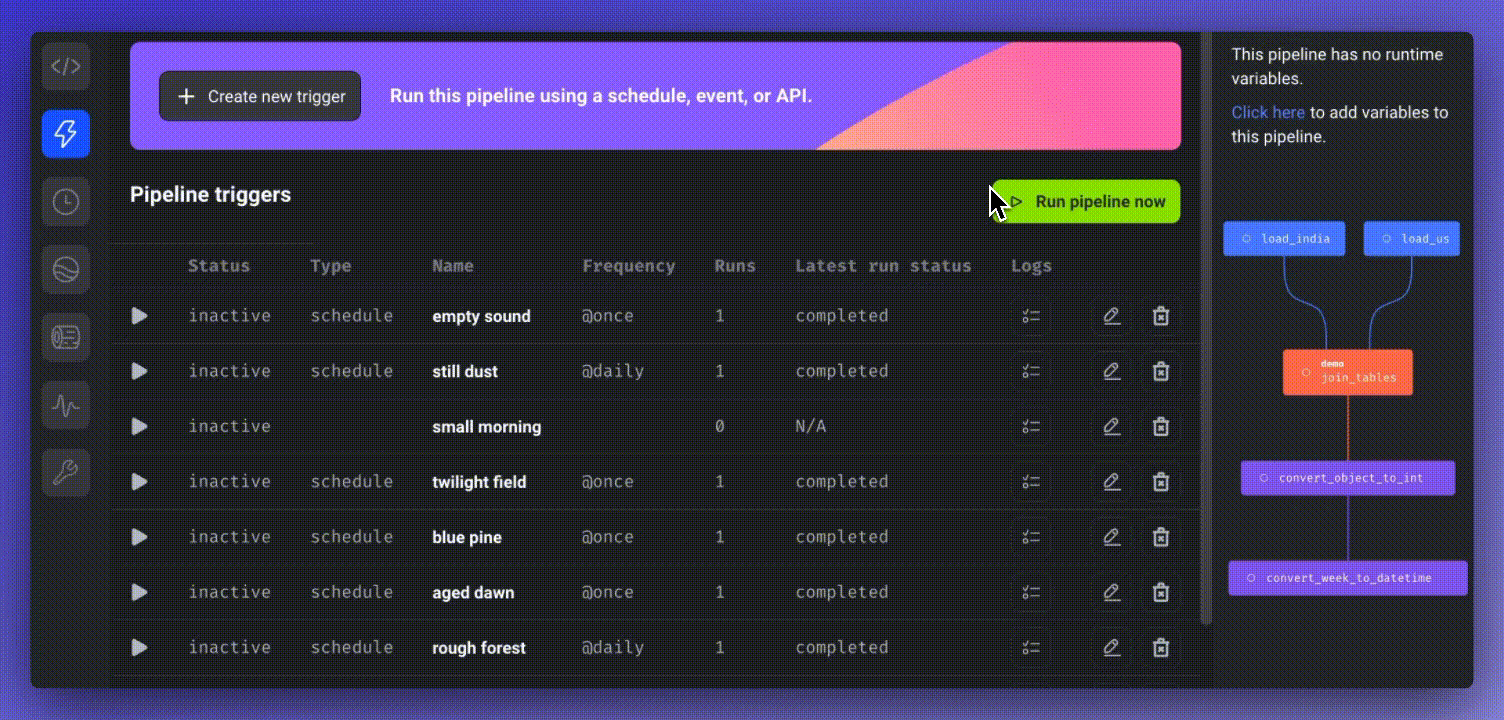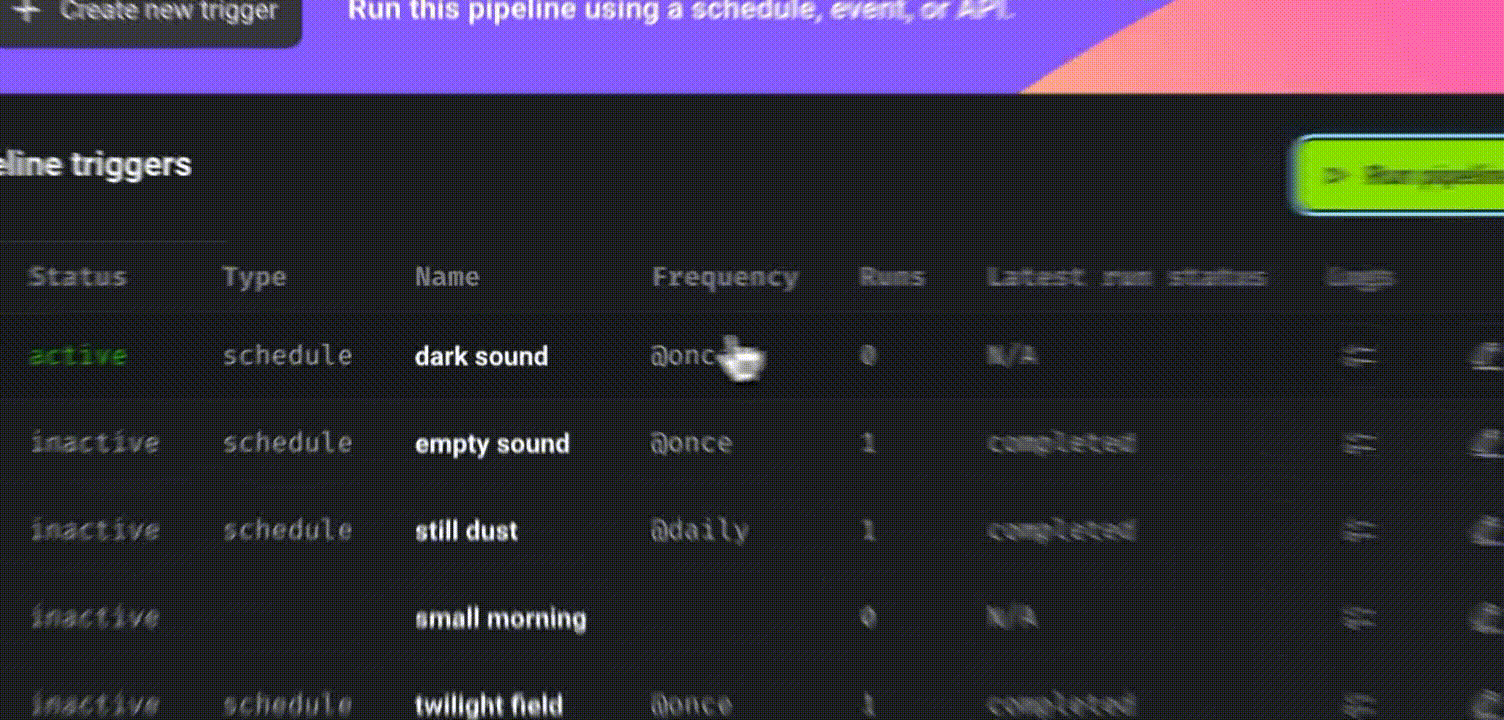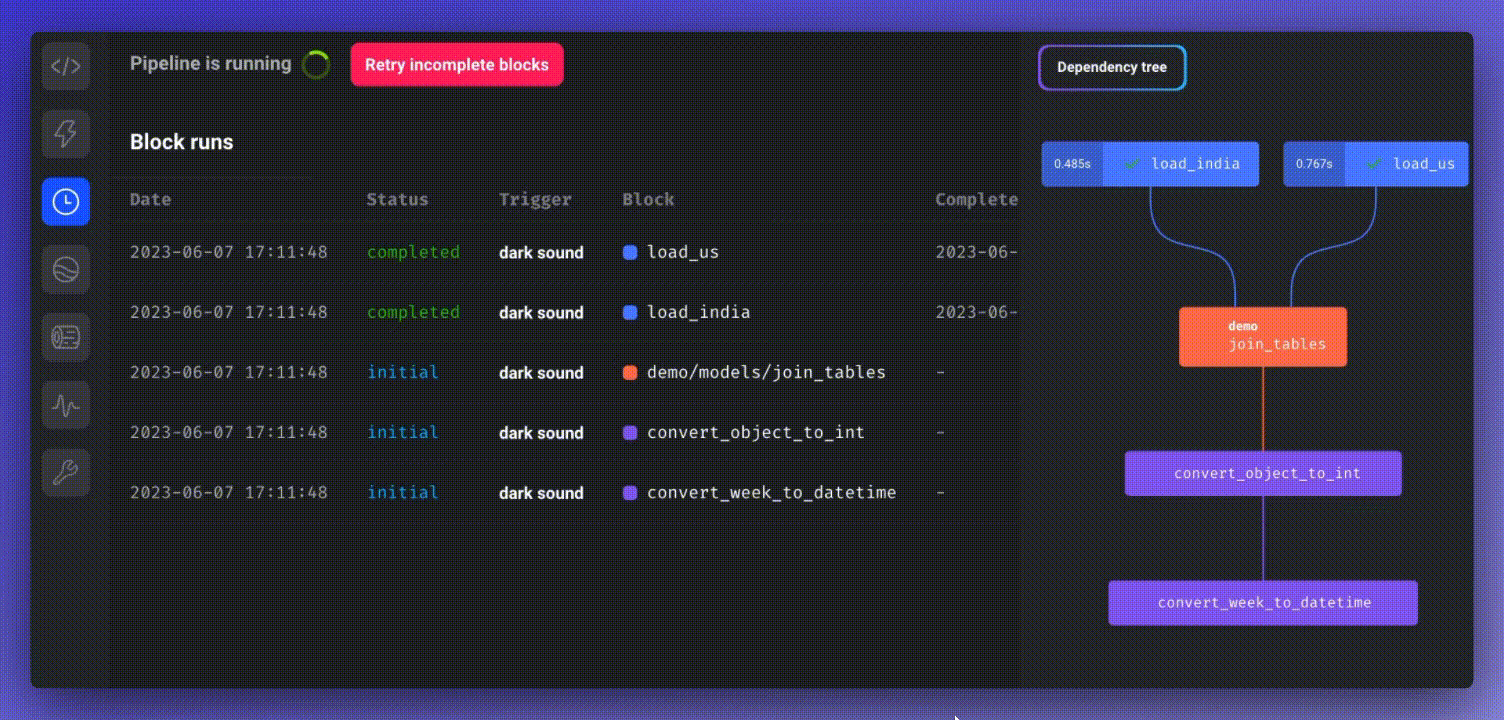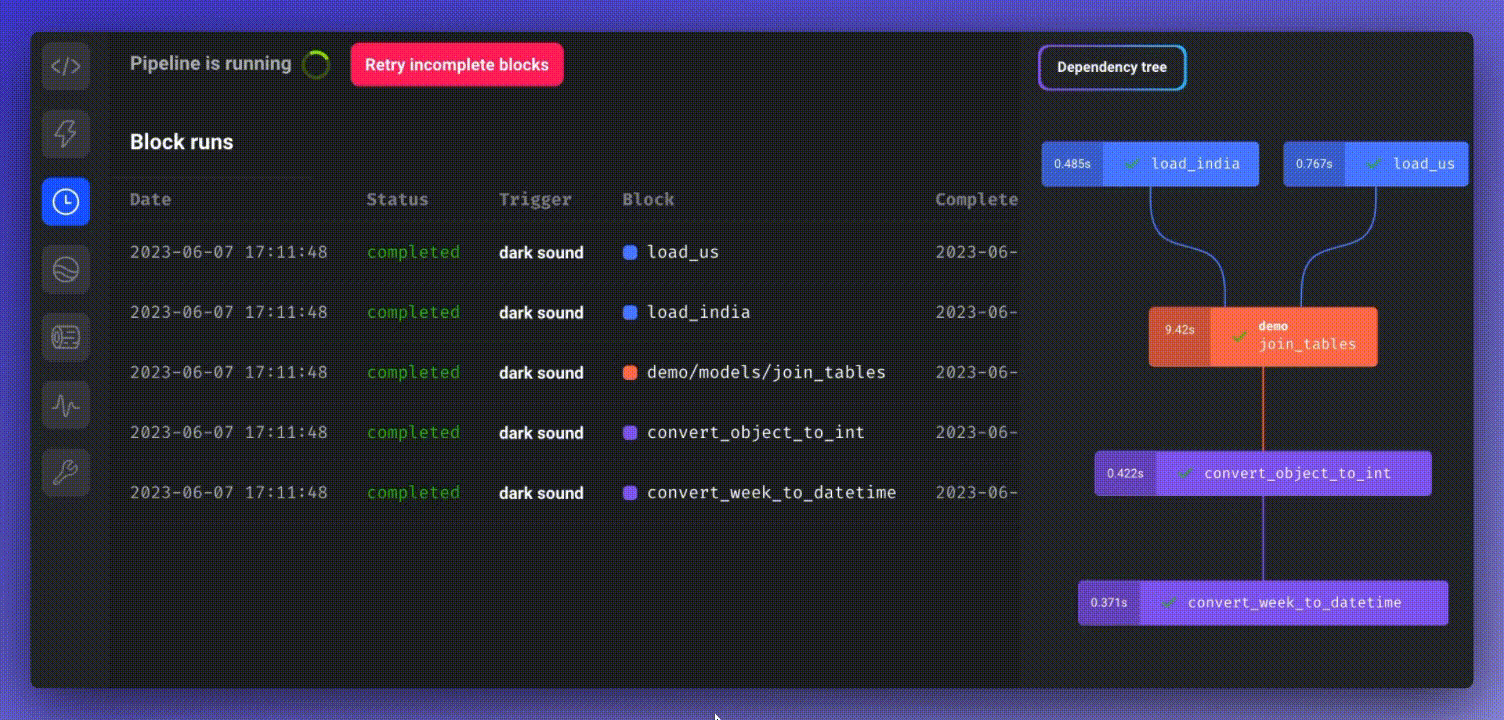
To schedule a pipeline, click “Create a new trigger,” select “Schedule,” and define the desired frequency.
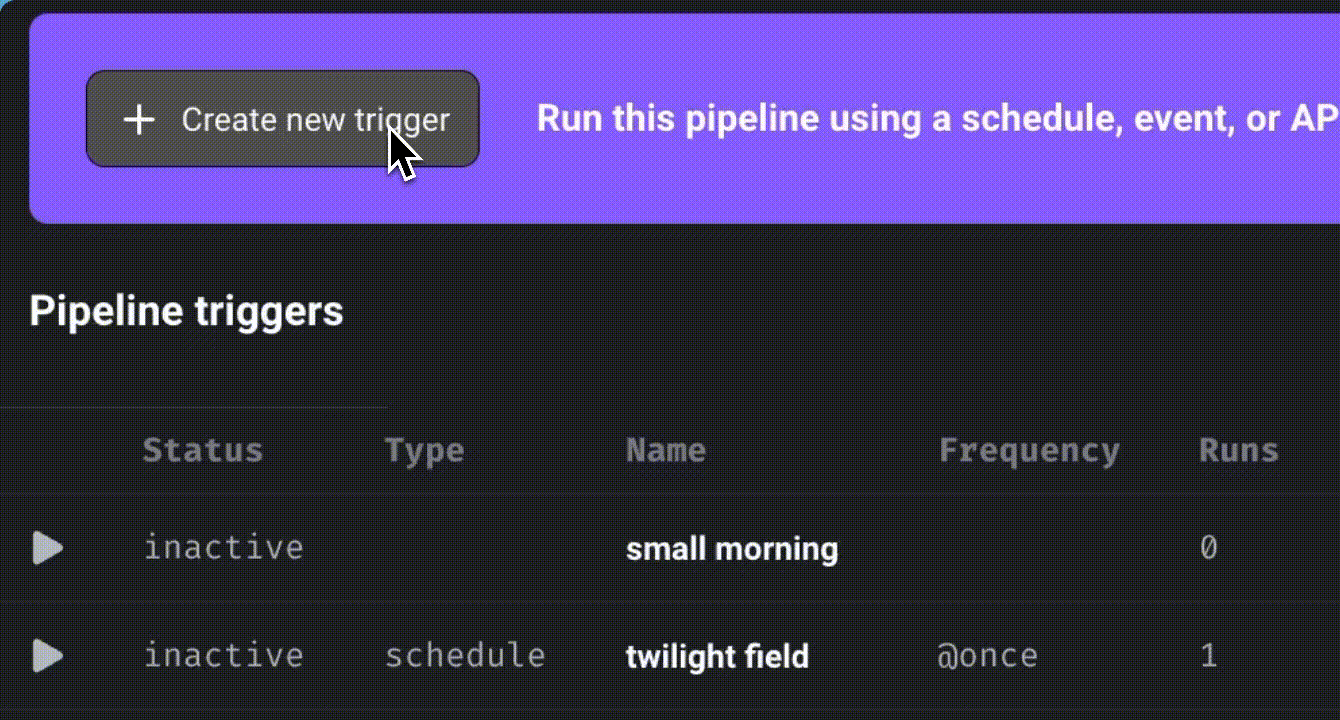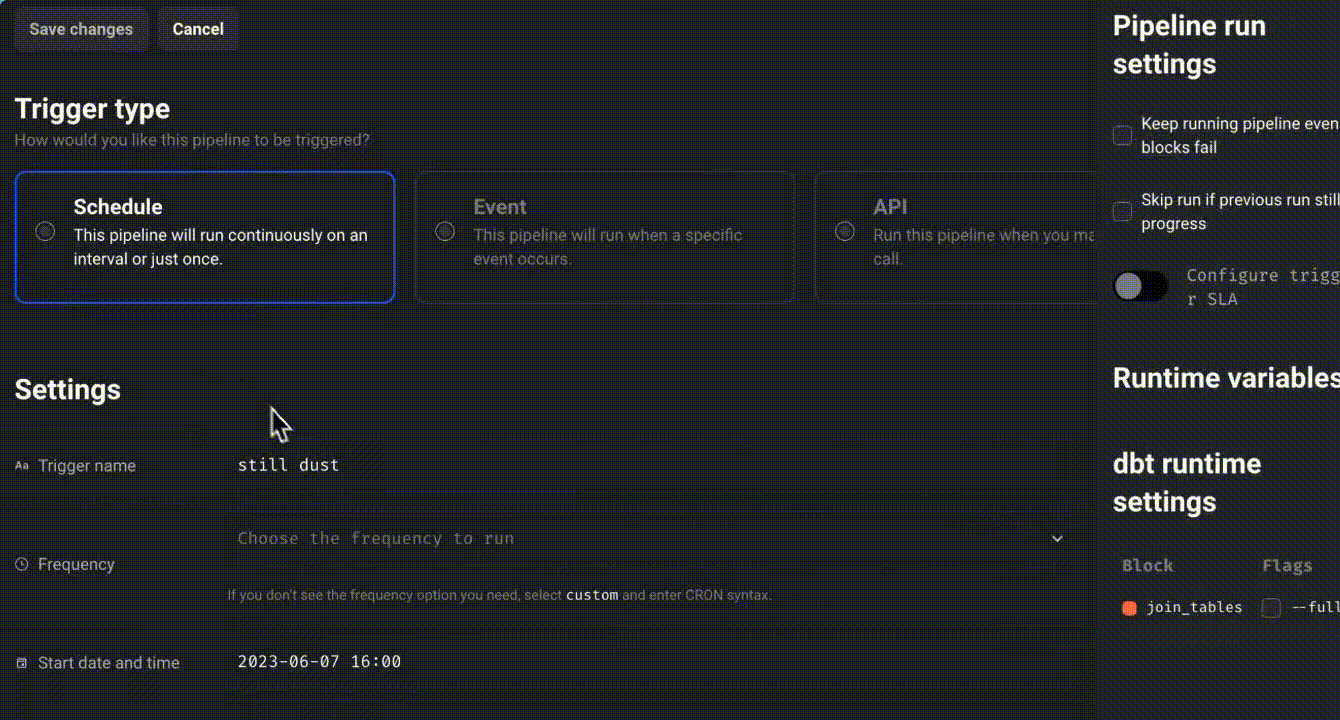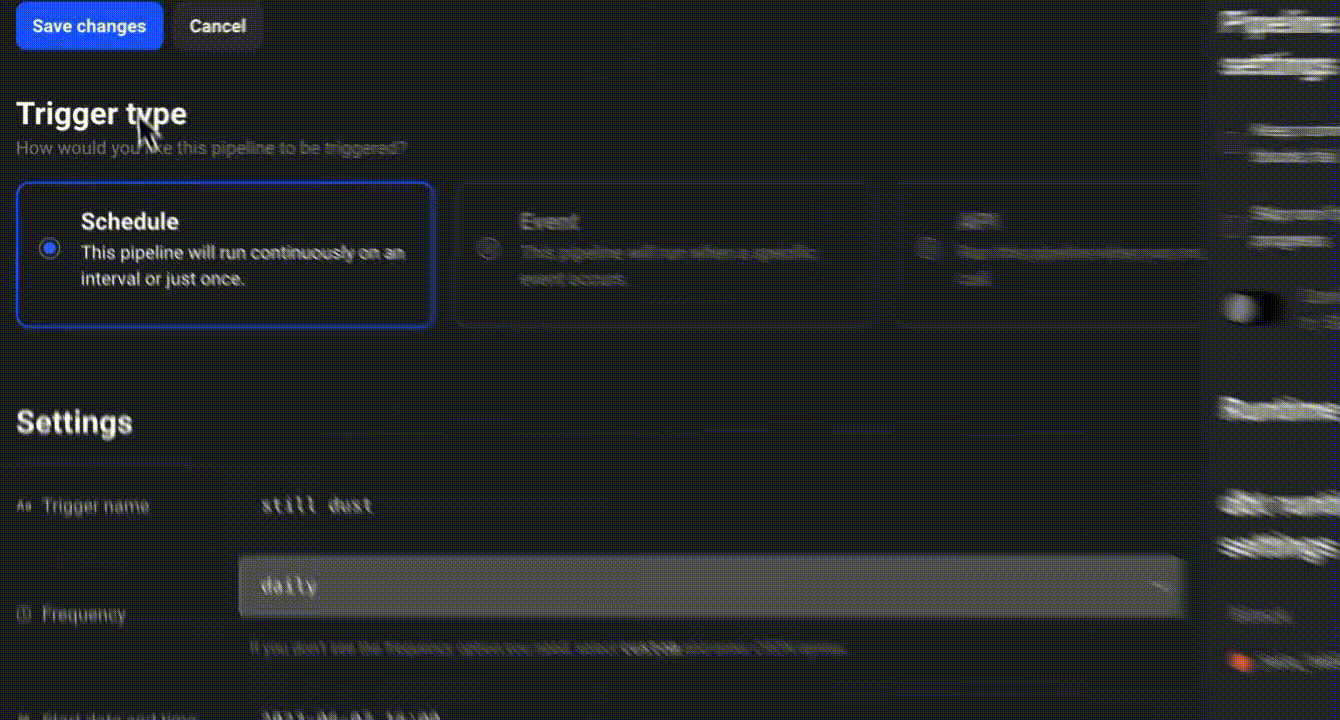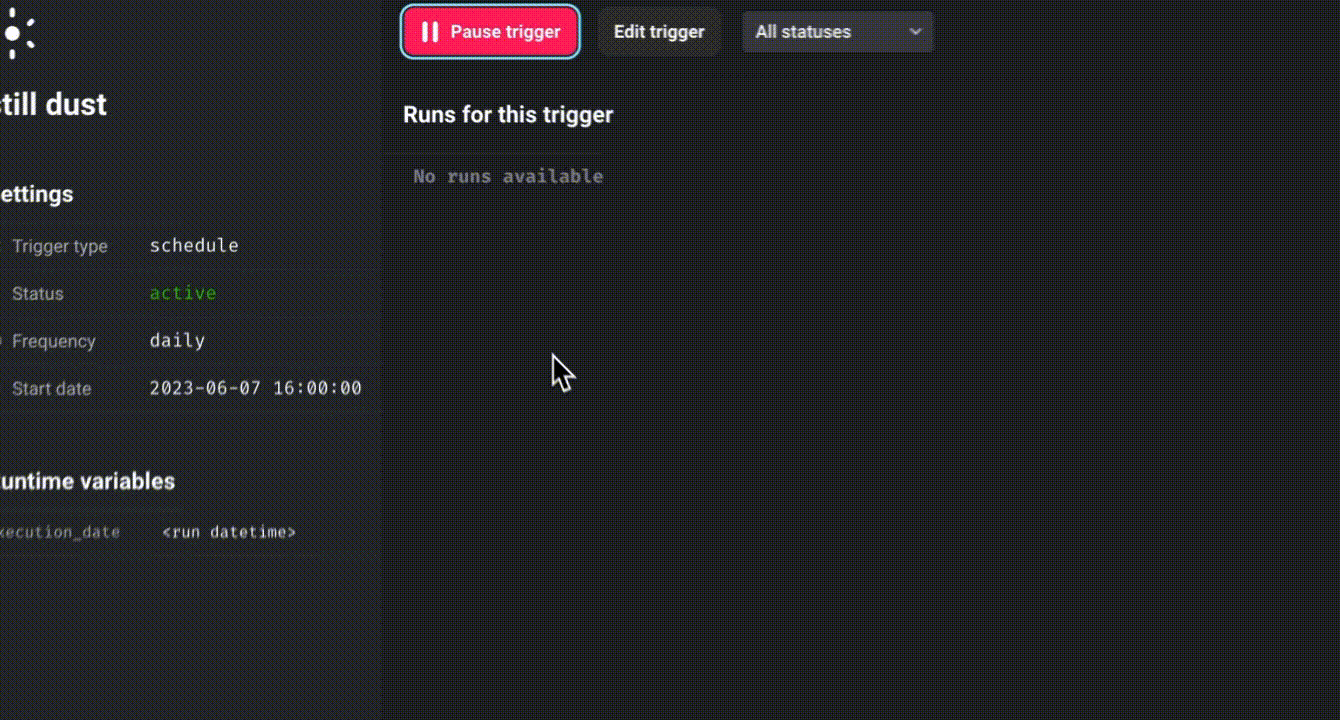
Click “Retry incomplete blocks” to retry failed blocks without restarting the entire pipeline.
Drawbacks
While Mage is a great complement to dbt, it’s important to consider a few drawbacks when using Mage:
- Increased project complexity: Integrating both Mage and dbt can introduce additional complexity to the structure of your project.
- Longer error messages: Due to Mage’s inclusion of extra code around the block code, error messages tend to be lengthier compared to standard error messages.
- Learning curve: While Mage provides an intuitive user experience, getting acquainted with this new tool will require some time and effort.
Conclusion
The integration of dbt and Mage provides a comprehensive set of benefits, including iterative data model development, multi-language support, visual output visualization, enhanced data extraction and loading capabilities, and automated scheduling and retries for data pipelines.
Mage is the ideal tool to complement your dbt project if you seek improved efficiency and are open to a slight increase in project complexity.