

Table of Contents
- Introduction
- Understanding the Architecture and Performance
- Getting started with Diffbot LLM
- Key Features and Capabilities
- Self-hosting for privacy
- Building Real-World Applications with Diffbot and LangChain
- Conclusion and Future Outlook
Introduction
Have you ever asked a language model about breaking news or stock prices and gotten outdated or misleading answers?
For example:
Prompt:
“What did the Federal Reserve announce about interest rates this morning?”
Possible Hallucinated Answer from a Traditional Model:
“This morning, the Federal Reserve announced a 0.5% increase in interest rates to combat inflation, citing strong job growth and rising consumer prices.”
This happens because traditional language models operate with static training data that becomes stale within months. They often sound confident, but there is no way to verify their claims. When you’re building applications that need accurate, up-to-date information with verifiable sources, these limitations aren’t just annoying. They’re unacceptable.
Diffbot LLM takes a different approach by connecting language generation to a massive, continuously updated knowledge graph containing over 1 trillion facts. Instead of relying solely on training data, it retrieves real-time information and provides citations for every claim it makes. Powered by GraphRAG, it keeps answers current and verifiable.
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.
Key Takeaways
Here’s what you’ll learn:
- Access real-time information with automatic citations using GraphRAG instead of outdated training data
- Execute JavaScript code for precise calculations rather than guessed mathematical results
- Query a knowledge graph with 1+ trillion facts that updates every 4-5 days for current information
- Build production RAG applications that combine document analysis with live web research
- Deploy locally with Docker for privacy-sensitive projects requiring complete data control
Understanding the Architecture and Performance
To understand how Diffbot LLM delivers those reliable, cited responses, we need to examine the architectural philosophy behind its design and the performance metrics that validate this approach.
The GraphRAG philosophy
Diffbot’s approach represents a fundamental shift in AI architecture: instead of building ever-larger models that memorize more facts, they built smaller models that excel at finding and using external knowledge. This design challenges the “bigger is better” mindset, showing a 70B model with live data can outperform larger models on factual tasks.
This architecture recognizes that facts change constantly while reasoning abilities remain stable. Rather than spending compute on memorizing Wikipedia, Diffbot fine-tuned models to become expert users of APIs, search engines, and code interpreters.
For example, instead of memorizing static facts like “Who is the CEO of Pfizer?”, Diffbot trains its model to make a real-time API call using a query like type:Organization name:"Pfizer" with the Diffbot Knowledge Graph API.
Here’s a simplified version of the API’s response:
{
"data": [
{
"ceo": {
"summary": "Greek-American pharmaceutical executive",
"image": "https://kg.diffbot.com/image/api/get?fetch=yes&url=g%3Cj7guSXzAoBWu.x0KwLZrUn.%5B%3CR0Aa4Hwygr9m6W%3Exl5G%60BkxmPAP1_w%7B%3C%3AVlDZ.Bv%3E",
"types": ["Person"],
"name": "Albert Bourla",
"diffbotUri": "http://diffbot.com/entity/EHPJc2wuRMGGvvptCHJ8jyg",
"targetDiffbotId": "EHPJc2wuRMGGvvptCHJ8jyg",
"type": "Person"
}
}
]
}
This API retrieves the latest CEO data by accessing the data.ceo.name field in the response (e.g., Albert Bourla), and includes a citation link to the original source.
The result is a system that stays current without expensive retraining cycles and provides transparency that pure neural approaches cannot match.
Core components
Diffbot’s system has three main components working together. The Knowledge Graph contains over 10 billion entities and their relationships, continuously ingesting new information from millions of web pages since 2016. This creates a living map of factual knowledge spanning organizations, people, products, and events.
The system’s architecture includes:
- Knowledge Graph – 10+ billion entities with 1+ trillion facts, updated every 4-5 days
- Fine-tuned models – 8B parameter and 70B parameter versions that can run on a single A100 or dual H100 GPUs, respectively
- Real-time web search – Direct access to current web pages
- Code interpreter – Executes JavaScript to compute answers directly, ensuring accuracy and transparency without relying on guesswork.
- Multimodal capabilities – Understands and analyzes images through built-in visual reasoning tools
Rather than memorizing facts, Diffbot fine-tuned the model to become an expert tool user, providing accurate results with full transparency.
Performance validation
Diffbot LLM’s benchmark performance validates its architectural advantages:
- FreshQA – 81% accuracy on real-time questions (highest among tested systems)
- MMLU-Pro – 70.36% on academic knowledge (best open-source under 100B parameters)
- SimpleQA – Outperformed all models including Perplexity Sonar Pro and Gemini-2.0-flash
- Citation accuracy – Every claim linked to verifiable sources
The improvement comes from tool use rather than larger weights, showing external knowledge retrieval can match larger traditional models.
Getting started with Diffbot LLM
With the architectural foundation in place, let’s walk through how to start using Diffbot LLM in practice.
Diffy – the web UI
The fastest way to experience Diffbot LLM is through Diffy.chat, the web interface that showcases the system’s capabilities without requiring any setup. You can immediately test real-time information retrieval, citations, and multimodal requests to understand what makes Diffbot LLM different.
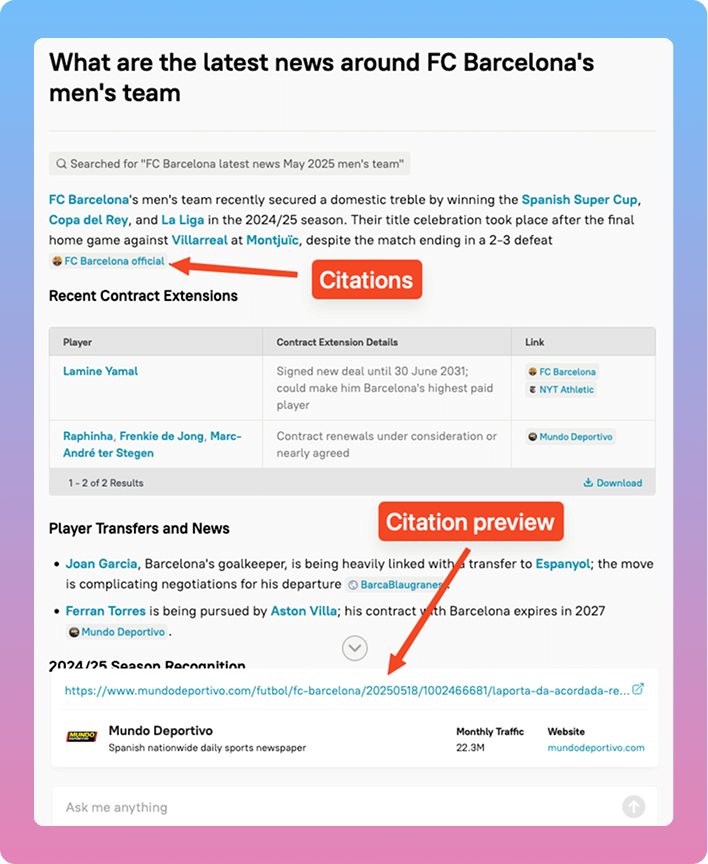
Key features available through the web UI:
- Real-time web URL extraction – Summarize any webpage with proper attribution
- Knowledge graph querying – Access structured facts from Diffbot’s trillion-fact database
- Image analysis – Upload images for visual understanding and interpretation
- JavaScript code interpreter – Get precise calculations and data processing
- Citation tracking – See exactly where every fact comes from with clickable sources
The citation panel shows sources for each claim, giving you immediate insight into the transparency that sets Diffbot apart from traditional LLMs.
Installation and setup
Getting started with the Diffbot LLM API requires just a few steps. Sign up for a free developer account at app.diffbot.com/get-started to obtain your API token. The free tier provides sufficient credits for testing, with higher limits available for production use.
pip install openai python dotenv
touch .env # Create a .env file
echo "DIFFBOT_API_TOKEN=your-token-here" >> .env # Add your token to a .env file
The API follows OpenAI’s interface exactly, so you can integrate Diffbot LLM by simply changing the base URL and API key. This compatibility means no code restructuring – your current OpenAI integration will work immediately with Diffbot’s GraphRAG capabilities.
Your first query with citations
Here’s a simple example demonstrating how Diffbot LLM returns responses with full citations:
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
DIFFBOT_API_TOKEN = os.getenv("DIFFBOT_API_TOKEN")
diffbot_client = OpenAI(
base_url="https://llm.diffbot.com/rag/v1",
api_key=DIFFBOT_API_TOKEN,
)
completion = diffbot_client.chat.completions.create(
model="diffbot-small-xl",
messages=[{"role": "user", "content": "What is GraphRAG?"}],
)
In this code, we:
- Initialize the OpenAI client with Diffbot’s base URL for the RAG endpoint.
- Send a chat-style request to the diffbot-small-xl model with the user message “What is GraphRAG?”
Here is the first few lines of the response:
print(completion.choices[0].message.content[:1000])
**GraphRAG** stands for **Graph-based Retrieval Augmented Generation**, a method that integrates **knowledge graphs** with traditional **Retrieval Augmented Generation (RAG)** approaches to enhance the effectiveness and contextuality of AI responses.
### Understanding GraphRAG {#understanding-graphrag}
GraphRAG improves upon traditional RAG models by organizing data into a structured knowledge graph, which allows for more precise and context-aware results. Traditional RAG methods rely on semantic searches of unstructured text snippets, whereas GraphRAG leverages a hierarchical and community-based structure within the knowledge graph to facilitate complex queries and relationships ([Analytics Vidhya](https://www.analyticsvidhya.com/blog/2024/11/graphrag/#h-what-is-graphrag)).
#### How Does GraphRAG Work?
The **GraphRAG indexing package** is a data pipeline and transformation suite designed to extract structured data from unorganized text using **Large Language Models (LLMs)**. The standard pipeline includes
The response structure follows OpenAI’s familiar format but cites a credible source: Analytics Vidhya. This makes it easy to swap in Diffbot for any existing OpenAI-based setup when your application requires real-time information and verifiable citations from a knowledge graph.
Key Features and Capabilities
To understand Diffbot’s capabilities, let’s compare the outputs from Diffbot and GPT-4o. To do that, we’ll first define a few helper functions: one to query Diffbot, one to query OpenAI, and another to print the model’s response:
def query_model(query_text, model, base_url=None, api_key=None):
client_args = {}
if base_url:
client_args["base_url"] = base_url
if api_key:
client_args["api_key"] = api_key
client = OpenAI(**client_args)
return client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": query_text}],
)
def query_diffbot(query_text, model="diffbot-small-xl"):
return query_model(
query_text,
model=model,
base_url="https://llm.diffbot.com/rag/v1",
api_key=DIFFBOT_API_TOKEN,
)
def query_openai(query_text, model="o4-mini"):
return query_model(query_text, model=model)
def print_response(response):
print(response.choices[0].message.content)
In the following sections, we’ll use these helper functions to ask questions and compare how each model responds.
1. Real-time knowledge retrieval
Let’s ask the model about the weather in Tokyo.
OpenAI:
openai_completion_1 = query_openai("What is the weather in Tokyo?")
print_response(openai_completion_1)
1. Visit a weather website or app
• Weather.com / The Weather Channel
• AccuWeather
• Japan Meteorological Agency (JMA): https://www.jma.go.jp
2. Ask a voice‐assistant (Siri, Google Assistant, Alexa, etc.)
...
The OpenAI model doesn’t provide the weather directly. Instead, it suggests where you can find it, reflecting its lack of real-time access.
Diffbot:
diffbot_completion_1 = query_diffbot("What is the weather in Tokyo?")
print_response(diffbot_completion_1)
### 🌤️ Tokyo, Japan
*May 28-31, 2025*
Wed ☁️ | 62-75°F ███████████████ | 💨 5 mph | 💧 14%
Thu 🌧️ | 62-75°F ███████████████ | 💨 5 mph | 💧 25%
Fri 🌧️ | 61-58°F ████████████░░ | 💨 10 mph | 💧 94%
Sat ⛈️ | 72-61°F ███████████████ | 💨 8 mph | 💧 93%
*Last updated: 9:13 PM JST ([AccuWeather](https://www.accuweather.com/en/jp/tokyo/226396/weather-forecast/226396)) ([Weather.com](https://weather.com/weather/tenday/l/Minato+ku+Tokyo+Prefecture+Japan?canonicalCityId=89a9a327ec5fd290c4d12f51a20485cb))*
The Diffbot model returns a real-time weather forecast with detailed daily updates and citations. This indicates the model is capable of actively retrieving and integrating up-to-date, verifiable information into its responses.
2. Code execution
Now, let’s ask a challenging math question that a traditional model would surely fail without access to a sandbox coding environment:
completion = query_diffbot(
"Find the square root of 12394890235",
)
print(completion.choices[0].message.content)
Output:
The square root of **12394890235** is approximately **111332.34137033139**.
<details>
<summary>Source</summary>
```javascript
// Input value
var x = 12394890235;
// Logging the input value
console.log("Input value (x):", x);
// Calculating the square root
var squareRoot = Math.sqrt(x);
// Logging the result
console.log("Square root of x:", squareRoot);
// Final answer
console.log("Answer:", squareRoot);
```
Output:
```text
Input value (x): 12394890235
Square root of x: 111332.34137033139
Answer: 111332.34137033139
```text
</details>
Both exponent calculations are precise and the final answer is correct as well with the sources being related to exponent calculations.
3. Image analysis
Now, let’s ask Diffbot multimodal questions that involve images. We will ask it to describe a nondescript URL of CodeCut’s banner:

OpenAI:
_image_url = "https://codecut.ai/wp-content/uploads/2025/05/codecut-home-image.png"
openai_completion_5 = query_openai(f"Describe this image to me: {_image_url}")
print(openai_completion_5.choices[0].message.content)
Again, GPT-4o is producing a fabricated response while Diffbot is accurate:
Diffbot:
_image_url = "https://codecut.ai/wp-content/uploads/2025/05/codecut-home-image.png"
diffbot_completion_5 = query_diffbot(f"Describe this image to me: {_image_url}")
print(diffbot_completion_5.choices[0].message.content)
This image features a modern laptop computer prominently in the center. The laptop is open to a coding interface, indicating its use for programming or software development purposes. The background of the image is clean and uncluttered, emphasizing the focus on the laptop and its digital content. The image has a resolution of 1200x1000 pixels.
This example verifies the multi-modal capabilities of Diffbot.
Self-hosting for privacy
If your use-case involves high-stakes sensitive information like financial or medical databases, you can get all the benefits of the Serverless API locally by running a couple of Docker commands:
For the 8B model, much smaller in disk size:
docker run --runtime nvidia --gpus all -p 8001:8001 --ipc=host -e VLLM_OPTIONS="--model diffbot/Llama-3.1-Diffbot-Small-2412 --served-model-name diffbot-small --enable-prefix-caching" docker.io/diffbot/diffbot-llm-inference:latest
For the larger 70B model with full capabilities:
docker run --runtime nvidia --gpus all -p 8001:8001 --ipc=host -e VLLM_OPTIONS="--model diffbot/Llama-3.3-Diffbot-Small-XL-2412 --served-model-name diffbot-small-xl --enable-prefix-caching --quantization fp8 --tensor-parallel-size 2" docker.io/diffbot/diffbot-llm-inference:latest
Once the application starts up successfully and you see a message like the following:
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
You can run all the examples above by replacing the base URL with the endpoint http://localhost:8001/rag/v1.
However, do note that these models require high-end GPUs like A100 and H100s to run at full precision. If you don’t have the right hardware, consider using RunPod.io which cost:
- $5.98/hr for dual H100 GPU setup (total 160 GB VRAM)
- $1.89/hr for a single A100 GPU setup (80 GB VRAM)
If you want to see another example of how to run LLM’s privately consider reading our article Run Private AI Workflows with LangChain and Ollama for a different approach.
Building Real-World Applications with Diffbot and LangChain
While the basic API integration shows Diffbot LLM’s capabilities, combining it with LangChain unlocks the full potential for building production-ready applications that require sophisticated workflows and real-time knowledge.
LangChain + Diffbot basics
Before building complex applications, you’ll need to install the required LangChain packages and understand how to integrate them with Diffbot’s API. Start by installing the necessary dependencies:
pip install langchain langchain-openai
LangChain provides a familiar interface for working with language models through its ChatOpenAI class. Since Diffbot LLM follows OpenAI’s API format, integration requires only changing the base URL and API key:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="diffbot-small-xl",
temperature=0,
max_tokens=None,
timeout=None,
base_url="https://llm.diffbot.com/rag/v1",
api_key=DIFFBOT_API_TOKEN,
)
This setup gives you access to all of LangChain’s features while benefiting from Diffbot’s real-time knowledge retrieval and citation capabilities. You can use the standard message format for simple interactions:
messages = [
("system", "You are a data scientist who writes efficient Python code."),
("human", "Given a DataFrame with columns 'product' and 'sales', calculates the total sales for each product."),
]
ai_msg = llm.invoke(messages)
print(ai_msg.content)
For more structured applications, LangChain’s ChatPromptTemplate allows you to create reusable prompt templates with variables:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a data scientist who writes efficient {language} code",
),
("human", "{input}"),
]
)
chain = prompt | llm
_result = chain.invoke(
{
"language": "SQL",
"input": "Given a table with columns 'product' and 'sales', calculates the total sales for each product.",
}
)
print(_result.content)
The pipe operator ( |) creates a chain that flows data from the prompt through the language model, making it easy to build complex workflows with multiple steps.
If you want to see another example of combining an LLM with Langchain you can read about it in our previous article Build Smarter Data Science Workflows with DeepSeek and LangChain.
Building a RAG application with Diffbot and LangChain
Now let’s build a production-level research assistant that combines document analysis with Diffbot’s real-time knowledge. This application will analyze uploaded documents, extract topics, and provide current information about those topics with proper citations.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
import json
from typing import List, Dict
class ResearchAssistant:
def __init__(self, diffbot_api_key: str):
self.llm = ChatOpenAI(
model="diffbot-small-xl",
temperature=0.3,
base_url="https://llm.diffbot.com/rag/v1",
api_key=diffbot_api_key
)
self.setup_chains()
def setup_chains(self):
# Chain for extracting topics from documents
self.topic_extraction_prompt = ChatPromptTemplate.from_template("""
Analyze the following document and extract 3-5 main topics or entities that would benefit
from current information. Return as a JSON list of topics.
Document: {document}
Topics (JSON format):
""")
# Chain for researching each topic
self.research_prompt = ChatPromptTemplate.from_template("""
Provide comprehensive, current information about: {topic}
Context from document: {context}
Include:
1. Current status and recent developments
2. Key statistics or data points
3. Recent news or updates
4. Relevant industry trends
Ensure all facts are cited with sources.
""")
# Chain for generating final report
self.report_prompt = ChatPromptTemplate.from_template("""
Create a comprehensive research report based on the document analysis and current research.
Original Document Summary: {document_summary}
Research Findings: {research_findings}
Generate a well-structured report that:
1. Summarizes the original document's main points
2. Provides current context for each major topic
3. Identifies any outdated information in the document
4. Suggests areas for further investigation
Include proper citations throughout.
""")
The ResearchAssistant class defines three specialized chains for different stages of the analysis. Each chain has a specific role: topic extraction identifies what to research, research gathering collects current information, and report generation synthesizes everything into a cohesive analysis.
def extract_topics(self, document: str) -> List[str]:
"""Extract main topics from the document for research."""
chain = self.topic_extraction_prompt | self.llm | StrOutputParser()
try:
result = chain.invoke({"document": document})
# Parse JSON response to get topic list
topics = json.loads(result.strip())
return topics if isinstance(topics, list) else []
except (json.JSONDecodeError, Exception) as e:
print(f"Error extracting topics: {e}")
return []
def research_topic(self, topic: str, context: str) -> str:
"""Research current information about a specific topic."""
chain = self.research_prompt | self.llm | StrOutputParser()
return chain.invoke({
"topic": topic,
"context": context
})
def generate_report(self, document: str, research_findings: List[Dict]) -> str:
"""Generate comprehensive report with current information."""
# Create document summary
summary_prompt = ChatPromptTemplate.from_template(
"Provide a concise summary of this document: {document}"
)
summary_chain = summary_prompt | self.llm | StrOutputParser()
document_summary = summary_chain.invoke({"document": document})
# Format research findings
findings_text = "\n\n".join([
f"**{finding['topic']}:**\n{finding['research']}"
for finding in research_findings
])
# Generate final report
report_chain = self.report_prompt | self.llm | StrOutputParser()
return report_chain.invoke({
"document_summary": document_summary,
"research_findings": findings_text
})
These methods handle the core workflow: extract_topics identifies research targets, research_topic gathers current information using Diffbot’s knowledge graph, and generate_report synthesizes everything into a comprehensive analysis.
def analyze_document(self, document: str) -> Dict:
"""Complete document analysis with current research."""
print("Extracting topics from document...")
topics = self.extract_topics(document)
if not topics:
return {"error": "Could not extract topics from document"}
print(f"Researching {len(topics)} topics...")
research_findings = []
for topic in topics:
print(f" - Researching: {topic}")
research = self.research_topic(topic, document)
research_findings.append({
"topic": topic,
"research": research
})
print("Generating comprehensive report...")
final_report = self.generate_report(document, research_findings)
return {
"topics": topics,
"research_findings": research_findings,
"final_report": final_report,
"status": "completed"
}
# Usage example
assistant = ResearchAssistant(DIFFBOT_API_TOKEN)
sample_document = """
Artificial Intelligence has made significant progress in natural language processing.
Companies like OpenAI and Google have released powerful language models.
The field of machine learning continues to evolve with new architectures and techniques.
Investment in AI startups reached $25 billion in 2023.
"""
result = assistant.analyze_document(sample_document)
print(result["final_report"])
This workflow demonstrates how LangChain’s orchestration capabilities combine with Diffbot’s real-time knowledge to create applications that deliver current, cited information.
You can extend this pattern for competitive intelligence, academic research, market analysis, or any application that benefits from combining document analysis with real-time knowledge.
Conclusion and Future Outlook
Diffbot LLM breaks from the “bigger is better” mindset by focusing on smarter, more efficient design. Instead of building massive models to store static facts, it empowers smaller models to:
- Find and use external knowledge
- Reduce compute costs
- Stay up to date without retraining
- Provide verifiable outputs
As more organizations require AI systems they can trust and audit, the GraphRAG approach developed by Diffbot LLM may well become the standard for production AI applications where accuracy matters more than creativity.
📚 Want to go deeper? Learning new techniques is the easy part. Knowing how to structure, test, and deploy them is what separates side projects from real work. My book shows you how to build data science projects that actually make it to production. Get the book →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.


