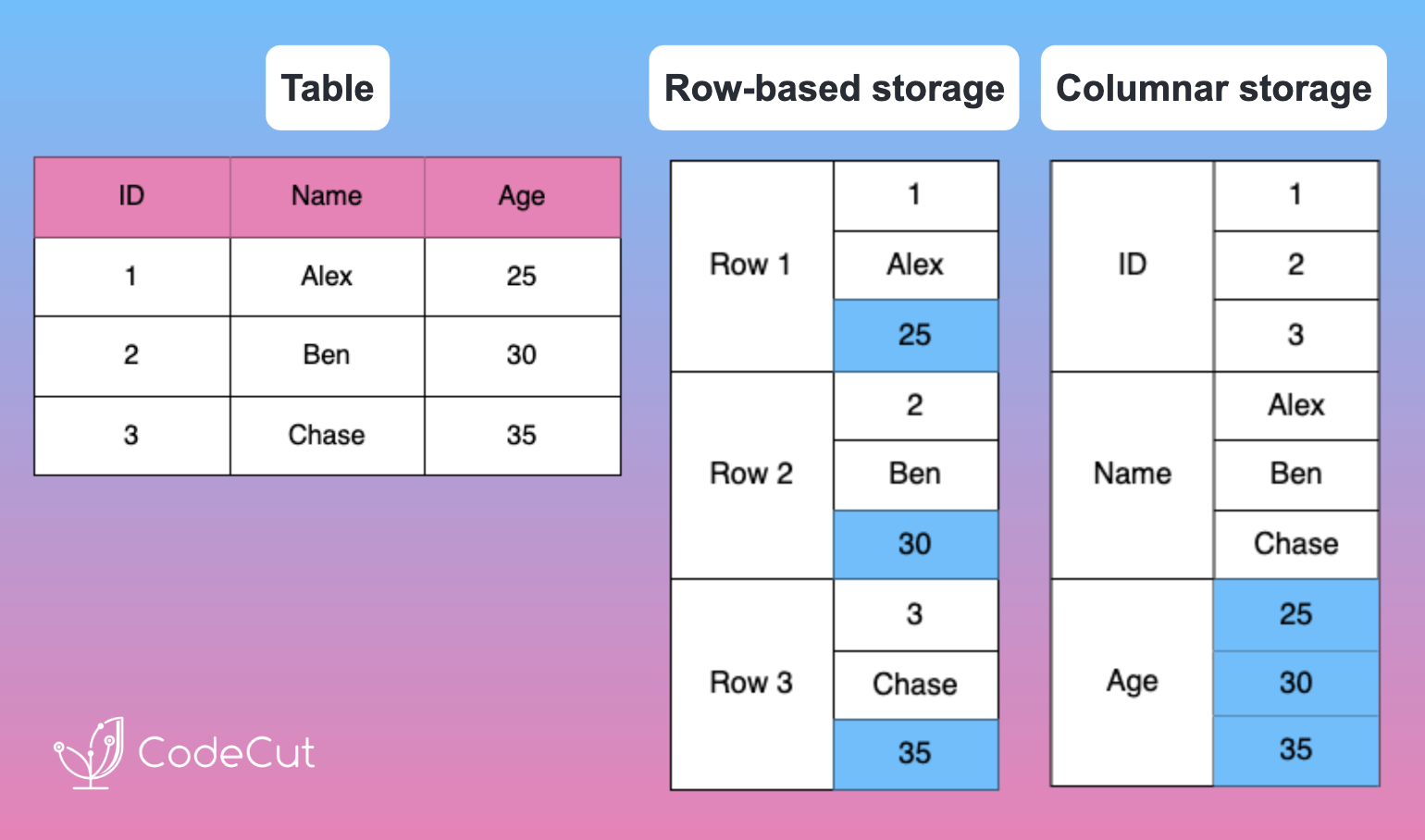

The Problem with Row-Based Storage: SQLite Example
When analyzing data with operations like GROUP BY, SUM, or AVG on specific columns, traditional row-based storage can lead to inefficient memory usage and slower query speeds. This is because entire rows must be loaded into memory, even when only a few columns are needed.
Let’s take a look at an example using SQLite, a popular row-based database management system.
import sqlite3
import pandas as pd
# Create a sample DataFrame
customer = pd.DataFrame({
"id": [1, 2, 3],
"name": ["Alex", "Ben", "Chase"],
"age": [25, 30, 35]
})
# Load data to SQLite and query
conn = sqlite3.connect(':memory:')
customer.to_sql('customer', conn, index=False)
# Must read all columns internally even though we only need 'age'
query = "SELECT age FROM customer"
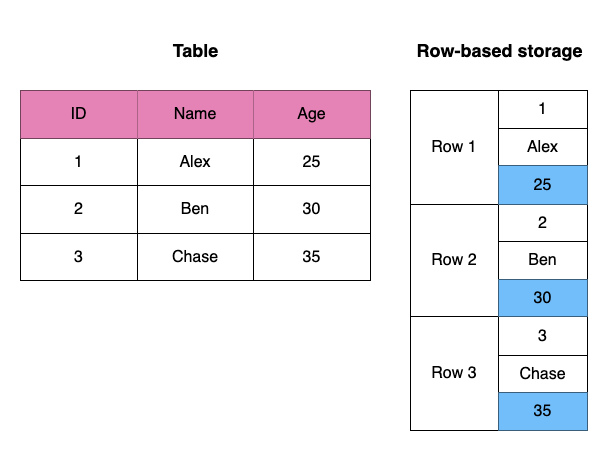
result = pd.read_sql(query, conn)In this example, even though we only need the age column, SQLite must read all columns (id, name, age) internally, leading to inefficient memory usage.
The Solution: Columnar Storage with DuckDB
DuckDB, on the other hand, uses columnar storage, allowing you to efficiently read and process only the columns needed for your analysis. This improves both query speed and memory usage.
import duckdb
import pandas as pd
# Create a sample DataFrame
customer = pd.DataFrame({
"id": [1, 2, 3],
"name": ["Alex", "Ben", "Chase"],
"age": [25, 30, 35]
})
# Query the DataFrame directly with DuckDB
query = "SELECT age FROM customer"
result = duckdb.sql(query).df()
print(result)
Output:
age
0 25
1 30
2 35
In this example, DuckDB only needs to access the age column in memory, making it a more efficient and scalable solution for data analysis.

Conclusion
DuckDB’s columnar storage provides a more efficient and scalable solution for data analysis, allowing you to query pandas DataFrames directly and only read the columns needed for your analysis. This leads to faster query speeds and more efficient memory usage, making it an ideal choice for large-scale data analysis tasks.


