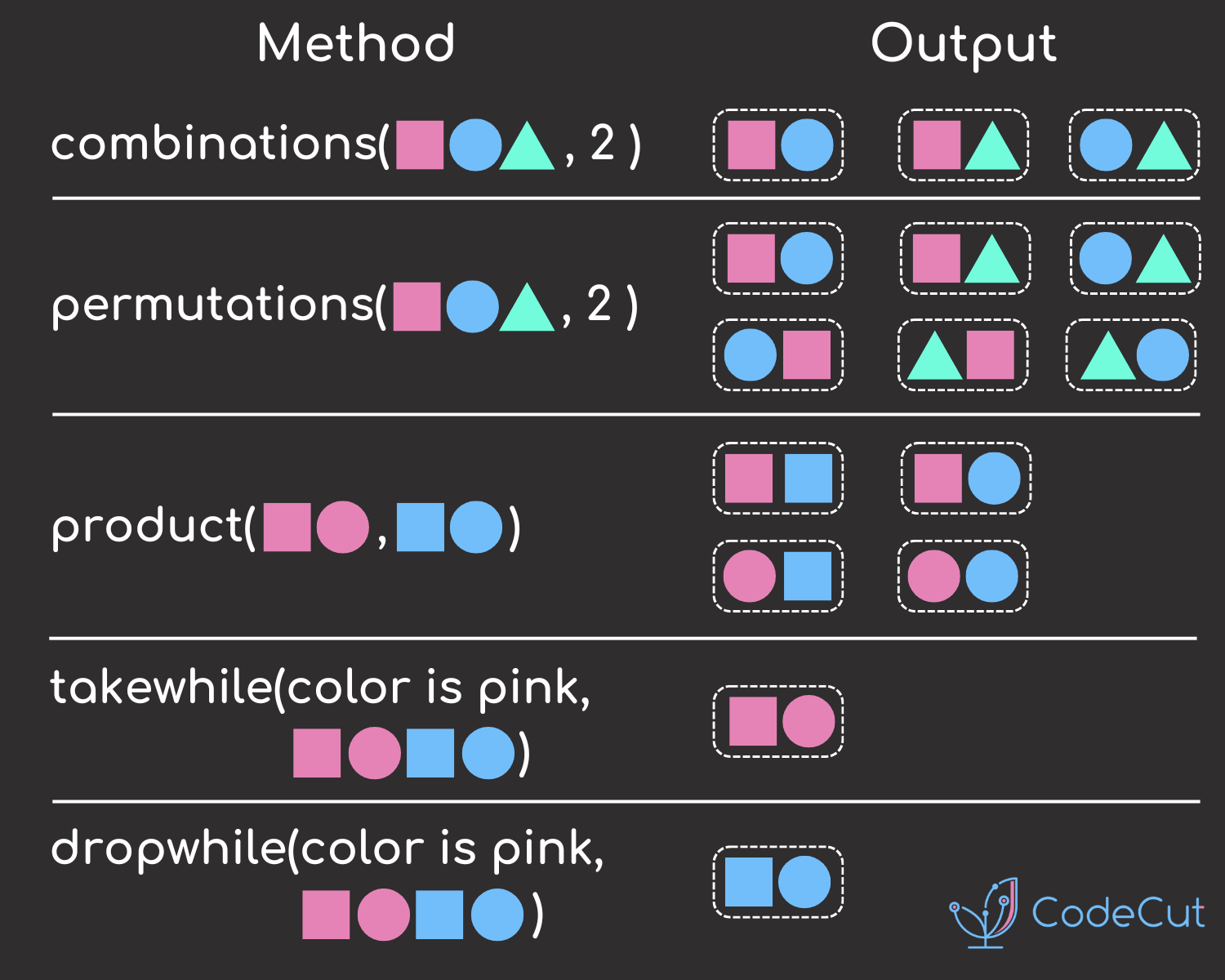

Python’s itertools module is a powerful tool that provides efficient looping and data manipulation techniques. By leveraging itertools, you can simplify your code, improve performance, and write more readable Python programs.
For more helpful Python tools and utilities, check out my collection of posts here.
In this post, we’ll explore several of the most useful functions from itertools and demonstrate how they can streamline common programming tasks.
itertools.combinations: Elegant Pair Generation
When you need to iterate through pairs of values from a list where order doesn’t matter (i.e., (a, b) is the same as (b, a)), itertools.combinations is the perfect tool. Without itertools, you might write nested loops like this:
num_list = [1, 2, 3]
for i in num_list:
for j in num_list:
if i < j:
print((i, j))Output:
(1, 2)
(1, 3)
(2, 3)This approach works, but it’s inefficient and verbose. With itertools.combinations, you can achieve the same result in a much more concise way:
from itertools import combinations
num_list = [1, 2, 3]
comb = combinations(num_list, 2)
for pair in comb:
print(pair)Output:
(1, 2)
(1, 3)
(2, 3)By using itertools.combinations, you eliminate the need for nested loops and conditional checks. The function generates all possible combinations of the elements in the list, allowing you to focus on the logic instead of the mechanics of iteration.
itertools.product: Simplifying Nested Loops
When you’re working with multiple parameters and need to explore all combinations of their values, you might find yourself writing deeply nested loops. For example, suppose you’re experimenting with different machine learning model parameters:
params = {
"learning_rate": [1e-1, 1e-2, 1e-3],
"batch_size": [16, 32, 64],
}
for learning_rate in params["learning_rate"]:
for batch_size in params["batch_size"]:
print((learning_rate, batch_size))Output:
(0.1, 16)
(0.1, 32)
(0.1, 64)
(0.01, 16)
...This code quickly becomes unwieldy as the number of parameters increases. Instead, you can use itertools.product to simplify this process:
from itertools import product
params = {
"learning_rate": [1e-1, 1e-2, 1e-3],
"batch_size": [16, 32, 64],
}
for combination in product(*params.values()):
print(combination)Output:
(0.1, 16)
(0.1, 32)
(0.1, 64)
(0.01, 16)
...itertools.product generates the Cartesian product of the input iterables, which means it returns all possible combinations of the parameter values. This allows you to collapse nested loops into a single concise loop, making your code cleaner and easier to maintain.
itertools.starmap: Applying Multi-Argument Functions
The built-in map function is great for applying a function to each element in a list. However, when the function takes multiple arguments, map isn’t sufficient. For example, say you want to apply a multiplication function to pairs of numbers:
def multiply(x: float, y: float):
return x * y
nums = [(1, 2), (4, 2), (2, 5)]
result = list(map(multiply, nums)) # This will raise a TypeErrormap doesn’t unpack the tuples, so it tries to pass each tuple as a single argument to multiply, which causes an error. Instead, you can use itertools.starmap, which unpacks the tuples automatically:
from itertools import starmap
def multiply(x: float, y: float):
return x * y
nums = [(1, 2), (4, 2), (2, 5)]
result = list(starmap(multiply, nums))
print(result) # [2, 8, 10]Output:
[2, 8, 10]itertools.starmap is particularly useful when you have lists of tuples or other iterable objects that you want to pass as multiple arguments to a function.
itertools.compress: Boolean Filtering
Sometimes, you need to filter a list based on a corresponding list of boolean values. While Python’s list comprehensions can handle this, itertools.compress provides a clean and efficient way to achieve this. Consider the following example:
fruits = ["apple", "orange", "banana", "grape", "lemon"]
chosen = [1, 0, 0, 1, 1]
print(fruits[chosen]) # This will raise a TypeErrorYou cannot directly use boolean lists as indices in Python. However, itertools.compress allows you to filter the fruits list based on the chosen list of booleans:
from itertools import compress
fruits = ["apple", "orange", "banana", "grape", "lemon"]
chosen = [1, 0, 0, 1, 1]
result = list(compress(fruits, chosen))
print(result) # ['apple', 'grape', 'lemon']Output:
['apple', 'grape', 'lemon']This is a clean and efficient way of filtering elements based on a selector list, making your filtering code more readable.
itertools.groupby: Grouping Elements by a Key
When you need to group elements in an iterable by a certain key, itertools.groupby can help. Imagine you have a list of fruits and their prices, and you want to group them by fruit name:
from itertools import groupby
prices = [("apple", 3), ("orange", 2), ("apple", 4), ("orange", 1), ("grape", 3)]
prices.sort(key=lambda x: x[0]) # groupby requires the list to be sorted by the key
for key, group in groupby(prices, key=lambda x: x[0]):
print(key, ":", list(group))Output:
apple : [('apple', 3), ('apple', 4)]
grape : [('grape', 3)]
orange : [('orange', 2), ('orange', 1)]itertools.groupby groups consecutive elements that share the same key. In this case, it groups the list of fruit prices by fruit name. Note that the input list must be sorted by the key for groupby to work correctly.
itertools.zip_longest: Zipping Uneven Iterables
The built-in zip function aggregates elements from two or more iterables, but it stops when the shortest iterable is exhausted. If you want to zip iterables of different lengths and handle the missing values, itertools.zip_longest is the solution:
from itertools import zip_longest
fruits = ["apple", "orange", "grape"]
prices = [1, 2]
result = list(zip_longest(fruits, prices, fillvalue="-"))
print(result)Output:
[('apple', 1), ('orange', 2), ('grape', '-')]itertools.zip_longest fills the missing values with a specified fillvalue, ensuring that all iterables are zipped to the length of the longest one.
itertools.dropwhile: Conditional Dropping
When you want to drop elements from an iterable until a condition is false, itertools.dropwhile is the tool for the job. For instance, if you want to drop numbers from a list until you encounter a number greater than or equal to 5:
from itertools import dropwhile
nums = [1, 2, 5, 2, 4]
result = list(dropwhile(lambda n: n < 5, nums))
print(result) # [5, 2, 4]Output:
[5, 2, 4]itertools.dropwhile starts yielding elements from the iterable as soon as the condition fails. This is useful for filtering streams of data where you want to skip initial elements based on a condition.
itertools.islice: Efficient Large Data Processing
When dealing with large data streams or files, loading the entire dataset into memory can be inefficient or even impossible. Instead, you can use itertools.islice to process the data in chunks without loading everything into memory. Consider this naive approach:
# Loading all log entries into memory
large_log = [log_entry for log_entry in open("large_log_file.log")]
for entry in large_log[:100]:
process_log_entry(entry)This code is memory-intensive because it loads the entire file at once. With itertools.islice, you can process only a portion of the data at a time:
import itertools
large_log = (log_entry for log_entry in open("large_log_file.log"))
for entry in itertools.islice(large_log, 100):
process_log_entry(entry)itertools.islice allows you to process the first 100 entries without loading the entire file, making it ideal for memory-efficient data processing.


