
When working with large datasets, efficient processing and storage are crucial for achieving fast query execution times. Two powerful tools that can help with this are DuckDB and PyArrow. In this post, we’ll explore how combining these two tools can lead to significant performance gains.
DuckDB: A High-Performance Database System
DuckDB is a high-performance database system designed for efficient query execution. It leverages various optimizations to achieve fast query execution times, making it an ideal choice for working with large datasets.
PyArrow: Efficient In-Memory Data Processing and Storage
PyArrow is a library for efficient in-memory data processing and storage. It provides a powerful API for working with large datasets, allowing for fast and efficient data processing.
Combining DuckDB and PyArrow
By combining DuckDB and PyArrow, we can efficiently process datasets larger than memory on a single machine. This is achieved by using PyArrow to handle in-memory data processing and storage, while DuckDB executes queries on the data.
Benchmarking DuckDB on PyArrow Dataset vs. Pandas
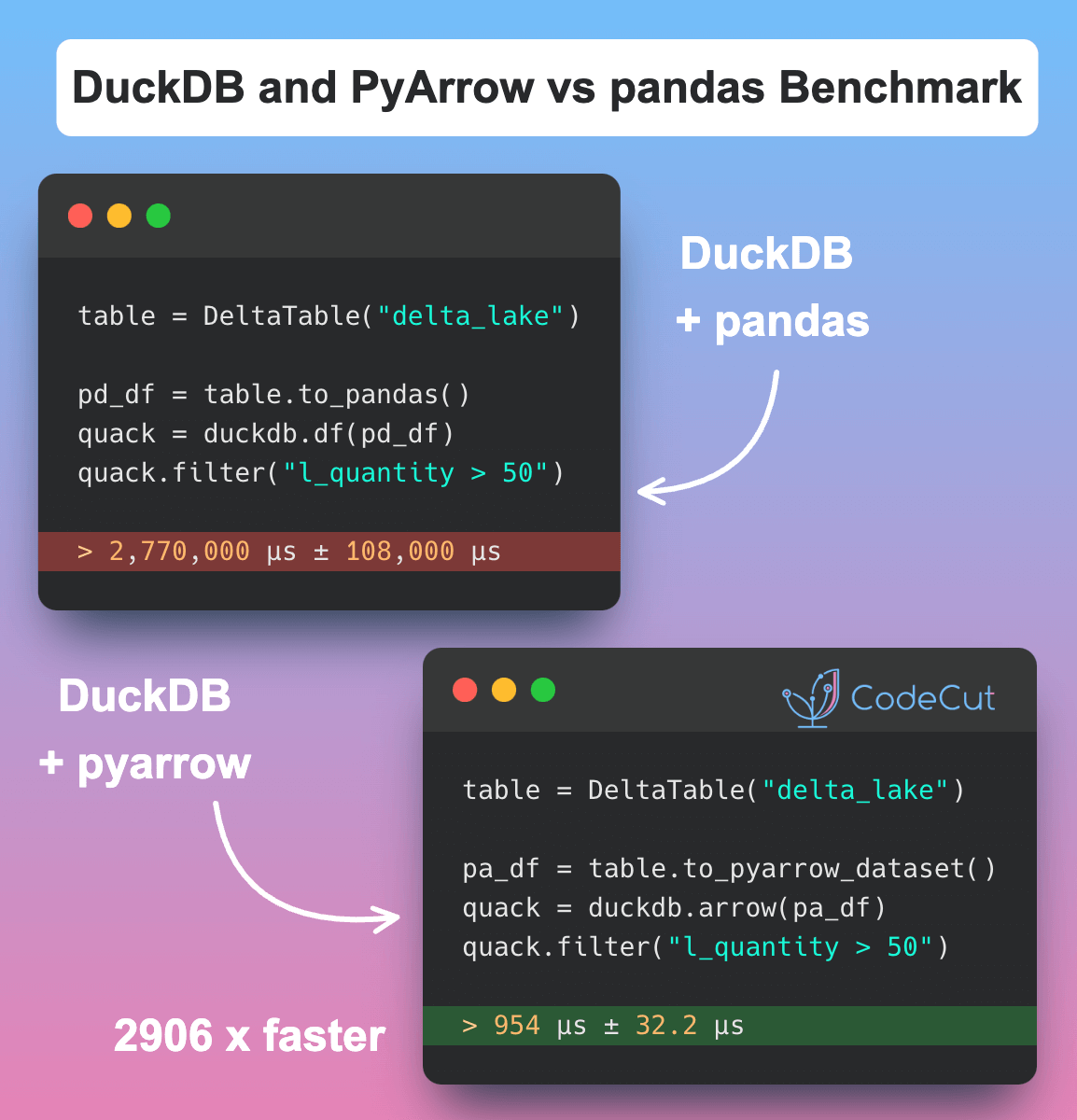
To demonstrate the performance gains of using DuckDB on a PyArrow dataset, we’ll benchmark it against using DuckDB on a pandas DataFrame. We’ll use a Delta Lake table with over 6 million rows as our dataset.
Here’s the code:
import pandas as pd
import duckdb
from deltalake.writer import write_deltalake
df = pd.read_parquet("lineitemsf1.snappy.parquet")
write_deltalake("delta_lake", df)
table = DeltaTable("delta_lake")%%timeit
quack = duckdb.df(table.to_pandas())
quack.filter("l_quantity > 50")2.77 s ± 108 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)%%timeit
quack = duckdb.arrow(table.to_pyarrow_dataset())
quack.filter("l_quantity > 50")954 µs ± 32.2 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)The results are staggering:
- Running DuckDB on a pandas DataFrame takes approximately 2.77 seconds per loop.
- Running DuckDB on a PyArrow dataset takes approximately 954 microseconds per loop.
This means that using DuckDB on a PyArrow dataset is approximately 2906 times faster than using DuckDB on a pandas DataFrame!
Conclusion
Combining DuckDB and PyArrow provides a powerful solution for efficiently processing large datasets. By leveraging the strengths of both tools, we can achieve significant performance gains and process datasets larger than memory on a single machine.



1 thought on “DuckDB + PyArrow: 2900x Faster Than pandas for Large Dataset Processing”
Interested to learn python.