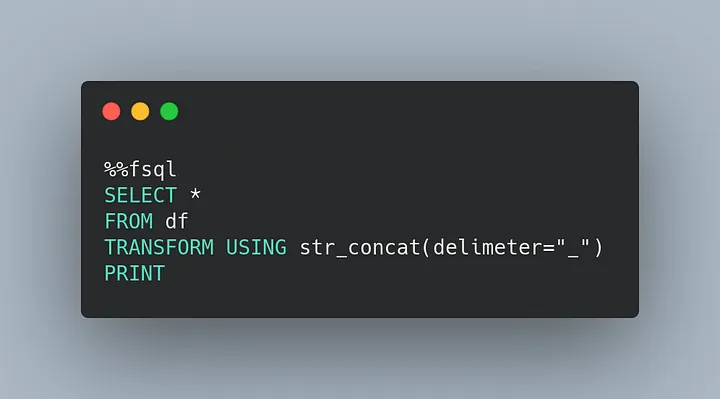
Motivation
As a data scientist, you might be familiar with both Pandas and SQL. However, there might be some queries, and transformations that you feel comfortable doing in SQL instead of Python.
Wouldn’t it be nice if you can query a pandas DataFrame using SQL.

…while also speeding up your code when working with large data?
That is when Fugue + DuckDB comes in handy.
In the previous article, I showed how to query a pandas DataFrame with SQL using the pandas engine.
In this article, I will show you how to speed up your query using the DuckDB engine.
Feel free to play and fork the source code of this article here.
Why Fugue and DuckDB?
Fugue is a Python library that allows users to combine Python code and SQL commands. This gives users the flexibility to switch between Python and SQL within a Jupyter Notebook or a Python script.
By default, Fugue maps your SQL code to pandas. However, pandas is not optimal to use when data size is beyond a few GBs because it:
- only allows you to use one core at a time
- creates a lot of intermediate copies of data, which increases memory usage
Fugue also allows you to scale your SQL code using Spark or Dask. However, smaller organizations might not have clusters to which they can port their workload.
Introduction to DuckDB
DuckDB is an in-process SQL OLAP database management system. The speed is very good on even gigabytes of data on local machines.
Thus, the combination of FugueSQL and DuckDB allows you to use SQL with Python and seamlessly speed up your code.
To install FugueSQL with DuckDB engine, type:
pip install -U fugue[duckdb,sql] Set Up
First, we import some setup functions for Fugue. This will let us use the %%fsql cell magic inside Jupyter notebooks. We also import the DuckDB engine.
from fugue_notebook import setup
import fugue_duckdb
setup()Load Data
This article will use the Binance Crypto Kittens dataset. This can be downloaded from Kaggle available through the Creative Commons License.
The folder crypto-binance contains over 1000 distinct files with a total memory of over 5GB. I combined these files and save the new file as raw.parquet.
After downloading the processed file, a file name raw.parquet will be saved in your local machine. Start with getting the location of the new file:
import os
save_path = os.getcwd() + '/raw.parquet'Now let’s compare the loading speed of pandas and DuckDB.
pandas
Start with loading the data using pandas:
Note that it took us 10.5s to load the data. This is pretty slow. Let’s see if we can speed up the process by using FugueSQL and DuckDB instead.
Fugue + DuckDB
To write SQL using DuckDB as the engine in a Jupyter Notebook cell, simply add %%fsql duck at the beginning of a cell:
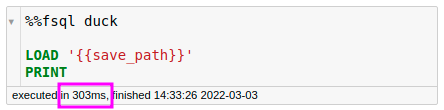
In the code above,
PRINTallows us to print the output- The double brackets
{{}}allow us to use the Python variable in SQL.
The code above loads the data in 303ms! Using DuckDB as the engine is over 34 times faster than using pandas as the engine.
Processing
Let’s compare the speed of processing data between pandas and DuckDB + Fugue.
pandas
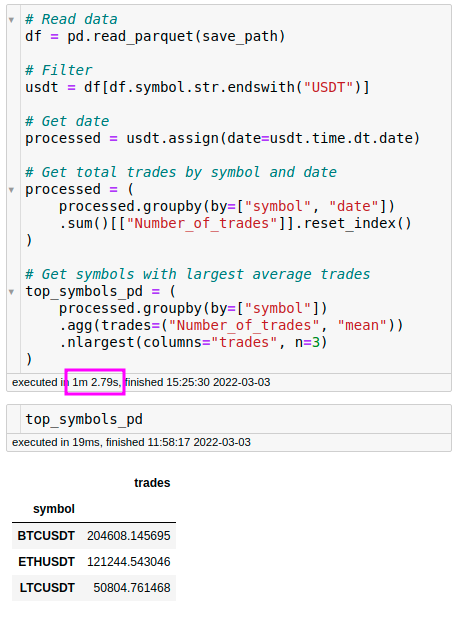
Fugue + DuckDB
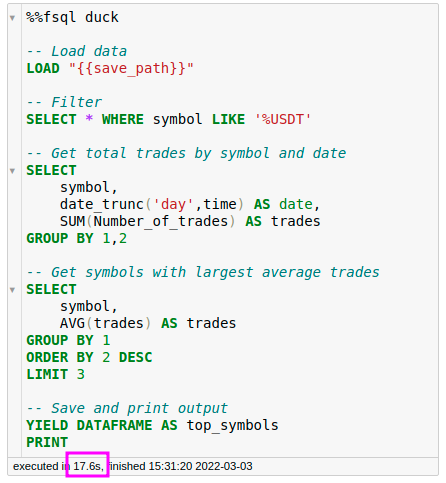
Note: FugueSQL allows for multiple _SELECT_ statements similar to SQL temp tables. This allows the code to be read top-down and eliminates a for of boilerplate code. If _FROM_ is not specified, the SQL statement uses the last DataFrame from the stack.
Observation
We can see that using Fugue + DuckDB is almost 4 times faster than using pandas. It is also slightly easier to write the processing code above in SQL than in pandas.
Why DuckDB Is So Much Faster?
DuckDB is faster because it uses lazy evaluation.
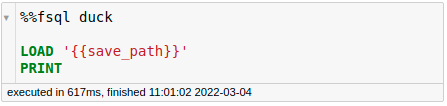
For example, in the code above, the PRINT statement returns a default of 10 records. DuckDB knows that only 10 records are needed by the end result, so it only fetches those records.
On the other hand, Pandas is executed eagerly. This means that only after the entire file is loaded in, the operation to fetch the first 10 rows is run.
But Why Fugue?
DuckDB has its own Python API, why should we use Fugue with DuckDB?
It is because Fugue provides custom functions that allow you to interact with your Python objects easily. In the next sections, we will learn how to improve your SQL code with some of these custom functions.
Use Fugue DataFrame
In the code above, the line
YIELD DATAFRAME AS top_symbols…outputs a fugue DataFrame and saves it as top_symbols .
You can easily turn top_symbols into a pandas DataFrame:
top_symbols.as_pandas()
…or use top_symbols in another SQL query:
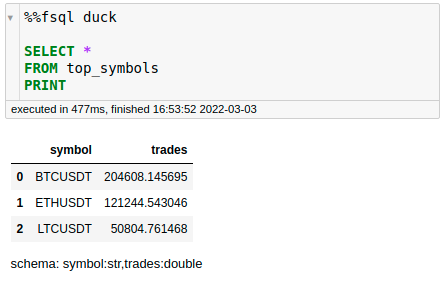
Assign Names to Intermediate Outputs
Sometimes, you might want to assign names to intermediate outputs so they can be used by other processes within the same SQL query. Fugue allows you to assign names to your intermediate outputs using = :
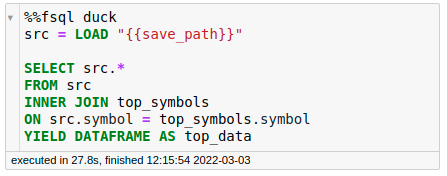
In the code above, I save the intermediate output to src then join src with top_symbols .
Python Extensions
Using Fugue and DuckDB together also allows you to use Python logic in SQL code through extensions. Let’s go through some of these extensions.
Output
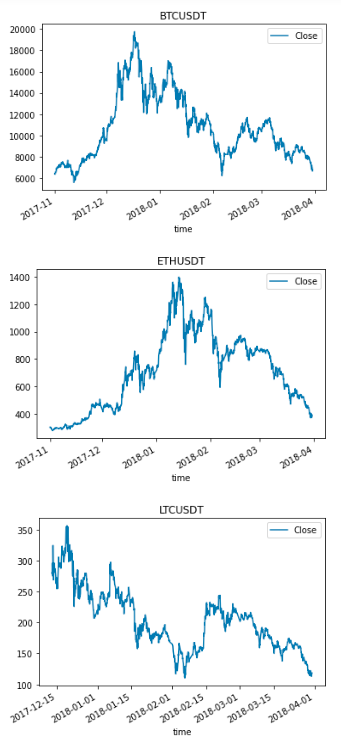
SQL doesn’t allow you to plot the outputs. However, we can create a plotting function in Python then use it in our SQL code.
def plot_by(df:pd.DataFrame, by, y) -> None:
for name, group in df.groupby(by):
group.plot(x="time", y=y, title=name)To use the plot_by function above, simply add OUPUT USING next to plot_by :
Transform
There are some functions that are easier to write in Python than in SQL. If you want to transform outputs of a SQL query using Python, use TRANSFORM .
To see how this extension works, start with creating a function called macd . This function uses pandas-ta to get a certain trend of the time series.
# schema: *,macd:double
def macd(df:pd.DataFrame) -> pd.DataFrame:
"""get macd - the indicator of the trend of the timeseries"""
import pandas_ta
macd = df.ta.macd(close='close', fast=12, slow=26, signal=9)
return df.assign(macd=macd.iloc[:,2])We also add the schema hint as a comment (# schema: *,macd:double) on top of the function macd so Fugue can read this schema hint and apply the schema.
Now we can use this function to transform the data in our query:
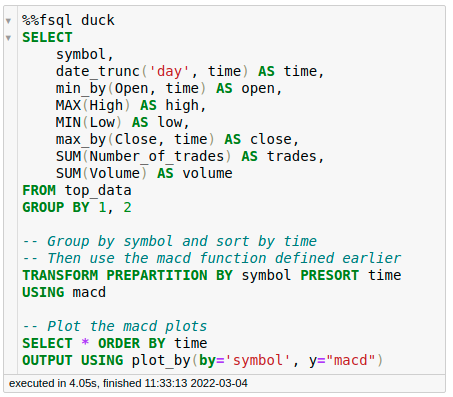
Cool! We have just transformed a SQL output using a Python function.
Learn more about TRANSFORM and PREPARTITION in Fugue here.
Fugue + DuckDB in Production
To bring FugueSQL out of Jupyter notebooks and into Python scripts, all we need to do is wrap the FugueSQL query inside a fsql class. We can then call the .run() method and choose an execution engine to be "duck".
import fugue_duckdb
query = """ src = LOAD "{{save_path}}"
SELECT * WHERE symbol LIKE '%USDT'
SELECT symbol, date_trunc('day',time) AS date, SUM(Number_of_trades) AS trades GROUP BY 1,2
top_symbols = SELECT symbol, AVG(trades) AS trades GROUP BY 1 ORDER BY 2 DESC LIMIT 4
SELECT src.* FROM src INNER JOIN top_symbols ON src.symbol = top_symbols.symbol
SELECT
symbol,
date_trunc('day', time) AS time,
min_by(Open, time) AS open,
MAX(High) AS high,
MIN(Low) AS low,
max_by(Close, time) AS close,
SUM(Number_of_trades) AS trades,
SUM(Volume) AS volume
GROUP BY 1, 2
TRANSFORM PREPARTITION BY symbol PRESORT time
USING macd
SELECT * ORDER BY time
OUTPUT USING plot_by(by='symbol', y="macd")
"""
fsql(query).run("duck")Conclusion
Congratulations! You have just learned to use FugueSQL with DuckDB as a backend to get the most out of local execution. Because of the lazy evaluation DuckDB provides, we can pre-aggregate our data quickly before bringing it to Pandas for further analysis which is hard to do in SQL.
Using Fugue as the interface also allows us to use the strengths of DuckDB seamlessly.