
Traditional NER Approach with spaCy
Traditional named entity recognition (NER) models are limited to predefined entity types, which can be restrictive for many applications. For example, spaCy’s default English model is trained to recognize only a few entity types, such as PERSON, ORG, GPE, DATE, and MONEY. To extract other types of entities, you would need to train separate models for each entity type or use large language models, which can be computationally expensive and resource-intensive.
Here’s an example of a traditional NER approach using spaCy:
import spacy
# Load a pre-trained model with fixed entity types
nlp = spacy.load("en_core_web_sm")
text = """
Maria Rodriguez loves making sushi and pizza in her spare time. She practices yoga
and rock climbing on weekends in Boulder, Colorado. Her friend Tom enjoys baking
fresh croissants and often brings them when they go hiking together in the Rocky Mountains.
"""
# Can only detect pre-defined entity types
doc = nlp(text)
for ent in doc.ents:
print(f"{ent.text} => {ent.label_}")
This code outputs:
Maria Rodriguez => PERSON
Boulder => GPE
Colorado => GPE
Tom => PERSON
the Rocky Mountains => LOC
As you can see, the model can only detect the predefined entity types, such as PERSON, GPE, and LOC.
GLiNER: A Lightweight and Flexible NER Model
GLiNER is a lightweight and flexible NER model that allows you to extract any custom entity types from text without retraining the model. You can specify the entity types you want to extract at inference time, making it a practical solution for many NLP applications.
Installation
To use GLiNER, you need to install the gliner library and download the pre-trained model. You can do this by running the following commands:
pip install glinerGLiNER Approach
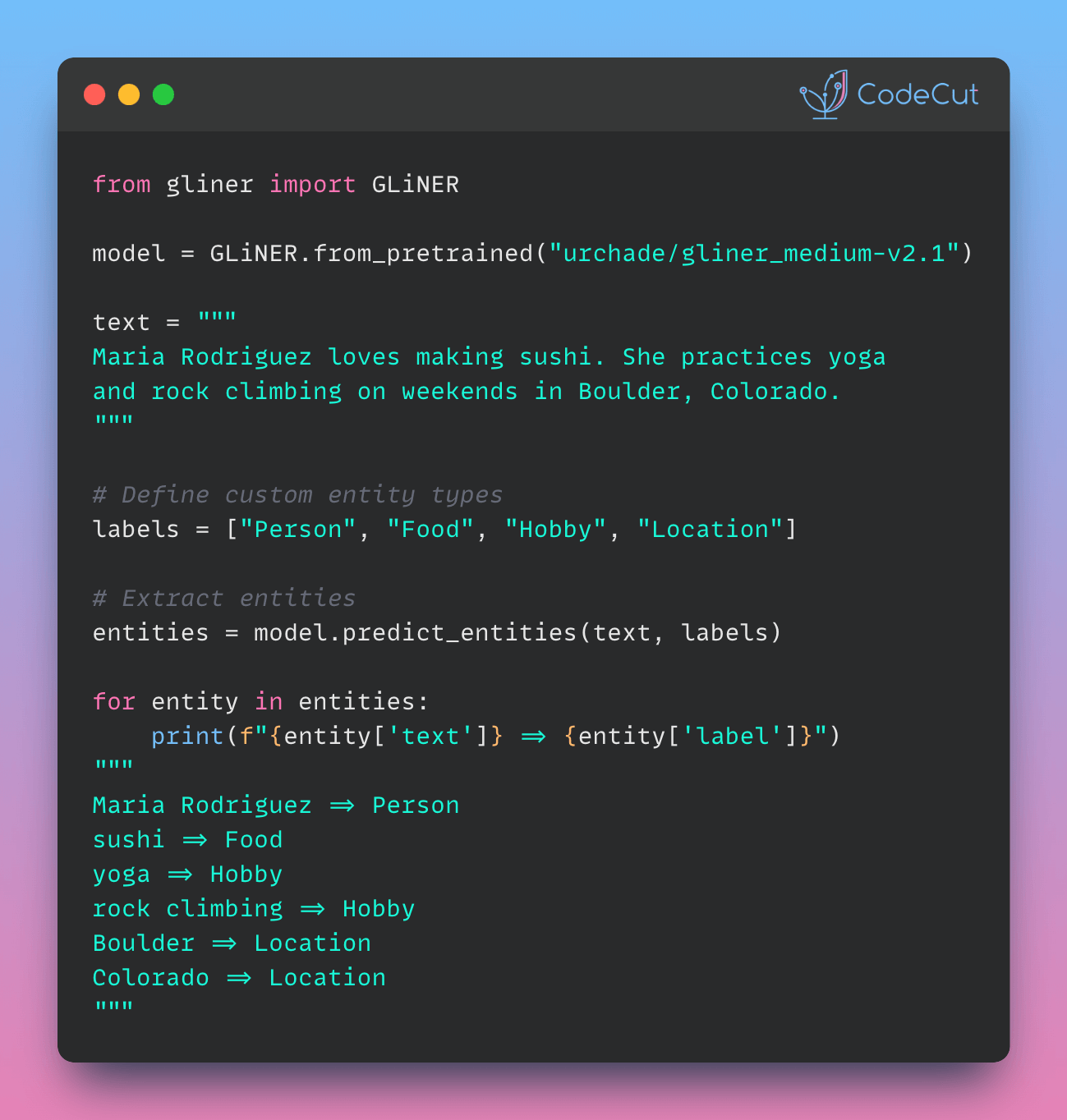
Now, let’s use GLiNER to extract custom entity types from the same text:
from gliner import GLiNER
# Initialize the model
model = GLiNER.from_pretrained("urchade/gliner_medium-v2.1")
text = """
Maria Rodriguez loves making sushi and pizza in her spare time. She practices yoga
and rock climbing on weekends in Boulder, Colorado. Her friend Tom enjoys baking
fresh croissants and often brings them when they go hiking together in the Rocky Mountains.
"""
# Define custom entity types
labels = ["Person", "Food", "Hobby", "Location"]
# Extract entities
entities = model.predict_entities(text, labels)
# Print the extracted entities
for entity in entities:
print(f"{entity['text']} => {entity['label']}")
This code outputs:
Maria Rodriguez => Person
sushi => Food
pizza => Food
yoga => Hobby
rock climbing => Hobby
Boulder, Colorado => Location
Tom => Person
fresh croissants => Food
Rocky Mountains => Location
As you can see, GLiNER can identify multiple custom entity types (persons, foods, hobbies, and locations) in a single pass without needing separate models or extensive training for each category.
Conclusion
GLiNER is a powerful and flexible NER model that allows you to extract custom entity types from text without retraining the model. Its lightweight architecture makes it a practical solution for many NLP applications. You can use GLiNER to extract entities from text by specifying the entity types you want to extract at inference time.
You can find more information about GLiNER on the official GitHub repository.