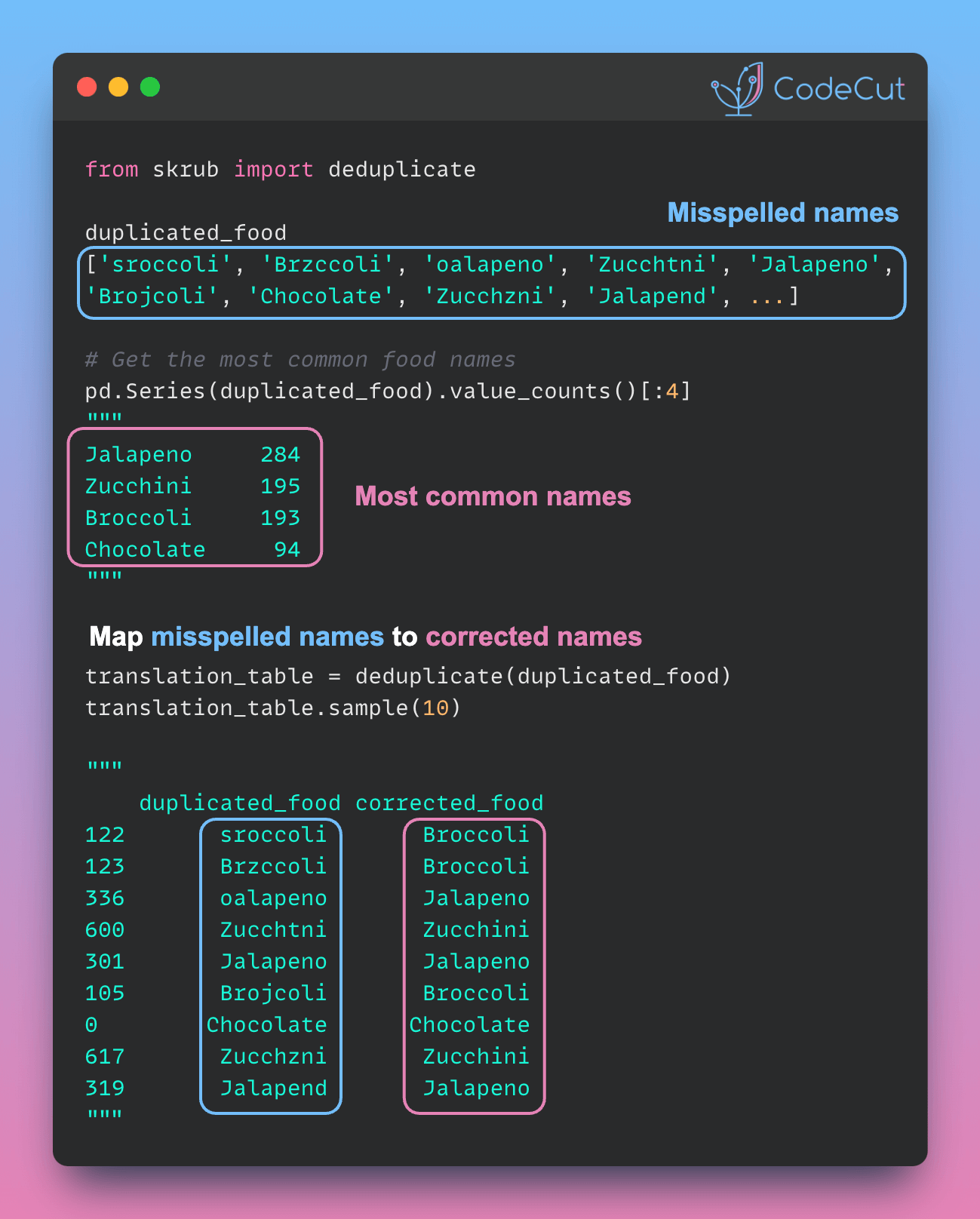

Real-world datasets often contain misspellings and variations in categorical variables, especially when data is manually entered. This can cause issues with data analysis steps that require exact matching, such as GROUP BY operations.
skrub‘s deduplicate() function helps solve this problem by using unsupervised learning to cluster similar strings and automatically correct misspellings.
To demonstrate the deduplicate function, start with generating a duplicated dataset:
from skrub.datasets import make_deduplication_data
import pandas as pd
duplicated_food = make_deduplication_data(
examples=["Chocolate", "Broccoli", 'Jalapeno', 'Zucchini'],
entries_per_example=[100, 200, 300, 200], # their respective number of occurrences
prob_mistake_per_letter=0.05, # 5% probability of typo per letter
random_state=42, # set seed for reproducibility
)
duplicated_food[:5]['Chocolate', 'Cgocolate', 'Chocolate', 'Chqcolate', 'Chocoltte']Get the most common food names:
import collections
counter = collections.Counter(duplicated_food)
counter.most_common(20)[('Jalapeno', 284),
('Zucchini', 195),
('Broccoli', 193),
('Chocolate', 94),
('Jalaoeno', 2),
('Cgocolate', 1),
('Chqcolate', 1),
('Chocoltte', 1),
('Chocdlate', 1),
('ehocolate', 1),
('Chocolatw', 1),
('Brocroli', 1),
('Brojcoli', 1),
('Broccsli', 1),
('Broccqli', 1),
('Bxoccoli', 1),
('sroccoli', 1),
('Brzccoli', 1),
('Jylapeno', 1),
('Jalapony', 1)]The most common words in the dataset are ‘Jalapeno’, ‘Zucchini’, and ‘Broccoli’. Therefore, skub’s deduplicate function replaces misspelled words with the closest matching word from this set.
from skrub import deduplicate
deduplicated_data = deduplicate(duplicated_food)
counter = collections.Counter(deduplicated_data)
counter.items()dict_items([('Chocolate', 100), ('Broccoli', 200), ('Jalapeno', 300), ('Zucchini', 200)])# create a table that maps original to corrected categories
translation_table = pd.Series(deduplicated_data, index=duplicated_food)
# remove duplicates in the original data
translation_table = translation_table[~translation_table.index.duplicated(keep="first")]
translation_table.sample(10)Brojcoli Broccoli
qalapeno Jalapeno
Jalapenh Jalapeno
Jalapeto Jalapeno
Zucchini Zucchini
oalapeno Jalapeno
Bxoccoli Broccoli
Jalqceno Jalapeno
Jzlapeno Jalapeno
ehocolate Chocolate
dtype: object

