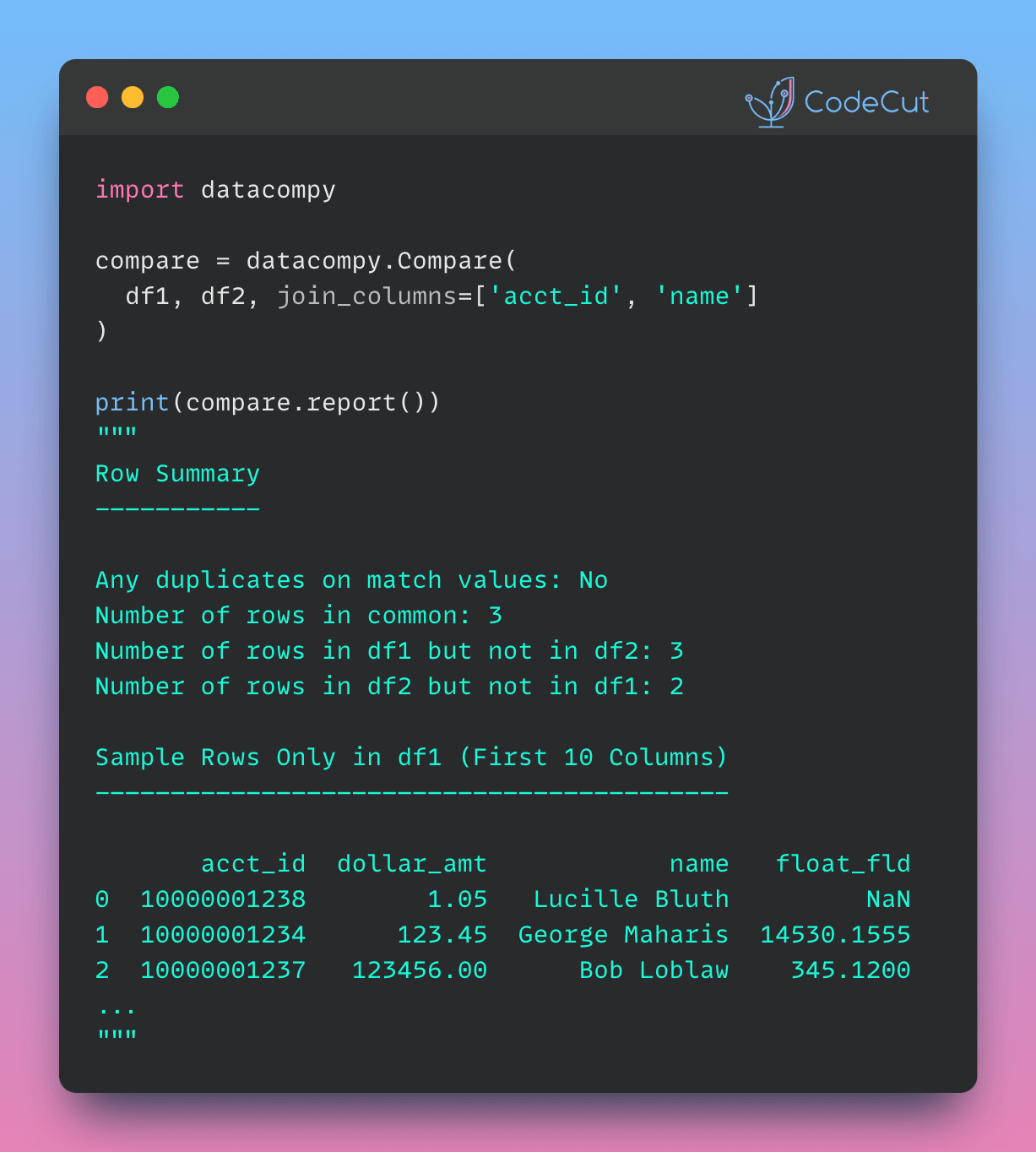
When dealing with Parquet files in pandas, it is common to first load the data into a pandas DataFrame and then apply filters.
To improve query execution speed, push down the filers to the PyArrow engine to leverage PyArrow’s processing optimizations.
In the code above, filtering a dataset of 100 million rows using PyArrow is approximately 113 times faster than filtering using pandas.