
Table of Contents
- What Are Git Submodules?
- Using Git Submodules in Practice
- Team Collaboration
- Managing Submodules Through VS Code
- Submodules vs Python Packaging
- Conclusion
Data science teams often develop reusable code for preprocessing, feature engineering, and model utilities that multiple projects need to share. Without proper management, these shared dependencies become a source of inconsistency and wasted effort.
Consider a fintech company with three ML teams in separate repositories due to different security clearances and deployment pipelines:
- Fraud Detection repo: High-security environment, quarterly releases
- Credit Scoring repo: Regulatory compliance, monthly releases
- Trading Algorithm repo: Real-time trading, daily releases
All three teams need the same calculate_risk_score() utility, but they can’t merge repositories due to security policies and different release cycles. Copying the utility creates version drift:
Week 1: All teams copy the same utility
Fraud Detection: calculate_risk_score() v1.0
Credit Scoring: calculate_risk_score() v1.0
Trading Algorithm: calculate_risk_score() v1.0
Week 3: Trading team fixes a critical bug but others don't know
Fraud Detection: calculate_risk_score() v1.0 (✗ still broken)
Credit Scoring: calculate_risk_score() v1.0 (✗ still broken)
Trading Algorithm: calculate_risk_score() v1.1 (✓ bug fixed)
Week 5: Each team has different versions
Fraud Detection: calculate_risk_score() v1.2 (≠ different optimization)
Credit Scoring: calculate_risk_score() v1.0 (✗ original broken version)
Trading Algorithm: calculate_risk_score() v1.3 (≠ completely different approach)
Git submodules provide the solution to this version drift problem.
Key Takeaways
Here’s what you’ll learn:
- Eliminate version drift across ML projects by referencing specific code commits
- Share utilities like risk calculation functions across teams without code duplication
- Maintain separate repositories with different security clearances and release cycles
- Update shared code versions precisely using Git submodule commands
- Implement reproducible ML workflows with consistent dependency versions
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.
What Are Git Submodules?
Git submodules let you embed one Git repository inside another as a subdirectory. Instead of copying code between projects, you reference a specific commit from a shared repository, ensuring all projects use identical code versions.
your-project/
├── main.py
└── shared-utils/ # ← Git submodule
└── features.py
This ensures every team member gets the same shared code version, preventing the version drift shown in the example above.
📚 For comprehensive Git fundamentals and production-ready workflows that complement Git submodule techniques, check out Production-Ready Data Science.
Using Git Submodules in Practice
Consider our fintech company with fraud detection, credit scoring, and trading projects that all need shared ML utilities for risk calculation and feature engineering.
The shared ml-utils repository contains common ML functions:
ml-utils/
├── __init__.py
├── features.py
└── README.md
# features.py
def calculate_risk_score(data):
return data['income'] / max(data['debt'], 1)
def extract_time_features(df, time_col):
df['hour'] = pd.to_datetime(df[time_col]).dt.hour
df['is_weekend'] = pd.to_datetime(df[time_col]).dt.dayofweek.isin([5, 6])
...
return df
def calculate_velocity(df, user_col, time_col):
df = df.copy()
df['transaction_count_1h'] = df.groupby(user_col)[time_col].transform('count')
...
return df
Imagine your fraud detection project looks like this:
fraud-detection/
├── main.py
└── README.md
To add the shared utilities to your fraud detection project, you can run:
git submodule add https://github.com/khuyentran1401/ml-utils.git ml-utils
This will transform the structure of your project to:
fraud-detection/
├── main.py
├── README.md
├── .gitmodules
└── ml-utils/ # ← Submodule directory
├── features.py # Shared ML functions
├── __init__.py
└── README.md
The .gitmodules file tracks the submodule configuration:
[submodule "ml-utils"]
path = ml-utils
url = https://github.com/khuyentran1401/ml-utils.git
Now you can use the shared utilities in your fraud detection pipeline:
# fraud_detection/train_model.py
from ml_utils.features import extract_time_features, calculate_velocity
def prepare_fraud_features(transactions_df):
# Extract time-based features for fraud detection
df = extract_time_features(transactions_df, 'transaction_time')
# Calculate transaction velocity features
df = calculate_velocity(df, 'user_id', 'transaction_time')
return df
# Fraud detection model uses consistent utilities
fraud_features = prepare_fraud_features(raw_transactions)
Team Collaboration
When a new team member joins the fraud detection team, they get the complete setup including shared ML utilities:
# Clone the fraud detection project with all ML utilities
git clone --recurse-submodules https://github.com/khuyentran1401/fraud-detection.git
cd fraud-detection
Alternatively, initialize submodules after cloning:
git clone https://github.com/khuyentran1401/fraud-detection.git
cd fraud-detection
git submodule update --init --recursive
When the code of the shared utilities is updated, you can update the submodule to the latest version:
# Update to latest ML utilities
git submodule update --remote ml-utils
This updates your local copy but doesn’t record which version your project uses. Commit this change so teammates get the same utilities version:
# Commit the submodule update
git add ml-utils
git commit -m "Update ML utilities: improved risk calculation accuracy"
For comprehensive version control of both code and data in ML projects, see our DVC guide.
Managing Submodules Through VS Code
To simplify the process of managing submodules, you can use VS Code’s Source Control panel.
To manage submodules through VS Code’s Source Control panel:
- Open your main project folder in VS Code
- Navigate to Source Control panel (Ctrl+Shift+G)
- You’ll see separate sections for main project and each submodule
- Stage and commit changes in the submodule first
- Then commit the submodule update in the main project
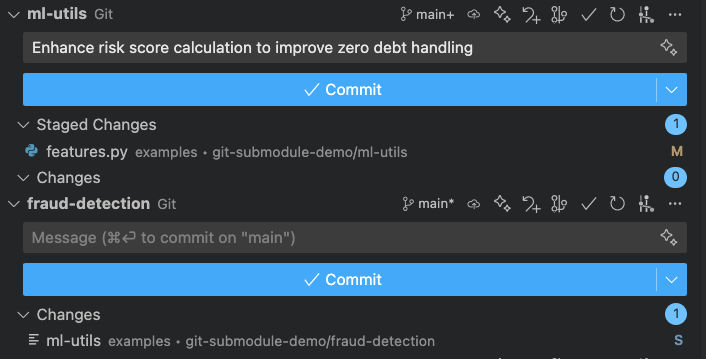
The screenshot shows VS Code’s independent submodule management:
- ml-utils submodule (top): Has staged changes ready to commit with its own message
- fraud-detection main project (bottom): Shows submodule as changed, waits for submodule commit
Submodules vs Python Packaging
Python packaging lets you distribute shared utilities as installable packages:
pip install company-ml-utils==1.2.3
This works well for stable libraries with infrequent changes. However, for internal ML utilities that evolve rapidly, packaging creates bottlenecks:
- Requires build/publish workflow for every change
- Slower iteration during active development
- Package contents are hidden – can’t debug into utility functions
- Stuck with released versions – can’t access latest bug fixes until next release
Git submodules work differently by making the source code directly accessible in your project for immediate access, full debugging visibility, and precise version control.
Conclusion
Git submodules provide an effective solution for managing shared ML code across data science projects, enabling source-level access while maintaining reproducible workflows.
Use submodules when you need direct access to shared utility source code, frequent iterations on internal libraries, or full control over dependency versions. For stable, external dependencies, traditional Python packaging remains the better choice.
📚 Want to go deeper? Learning new techniques is the easy part. Knowing how to structure, test, and deploy them is what separates side projects from real work. My book shows you how to build data science projects that actually make it to production. Get the book →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.