📅 Today’s Picks
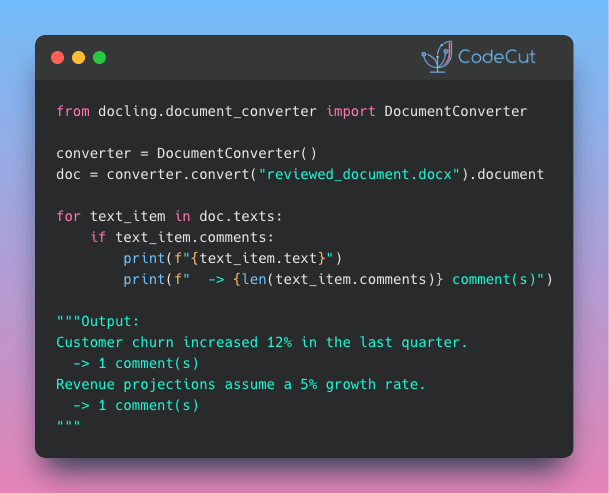
Auto-Summarize Chat History with LangChain Middleware
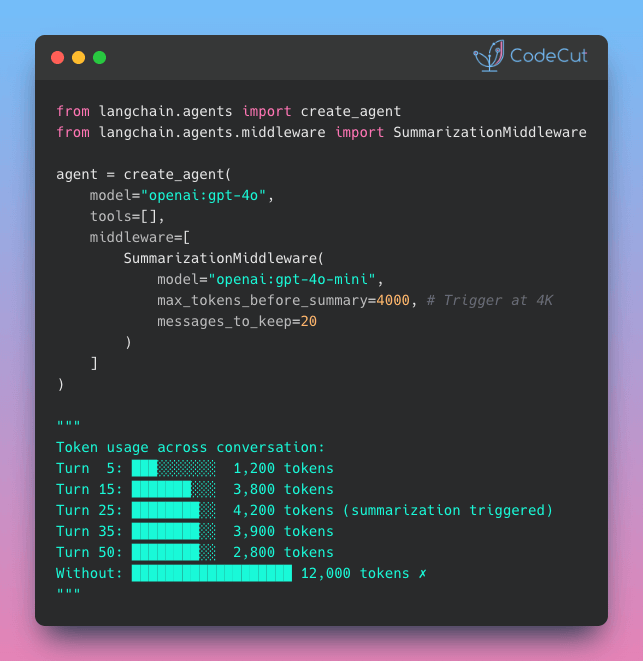
Problem
Long chat histories can quickly increase token usage, leading to higher API costs and slower responses.
Solution
LangChain v1.0 introduces SummarizationMiddleware that automatically condenses older messages when token thresholds are exceeded.
Key features:
- Integrates into existing LangChain agents with minimal code changes
- Automatic summarization when token limits are reached
- Preserves recent context with configurable message retention
- Uses efficient models for summarization (e.g., gpt-4o-mini)
Batch Process DataFrames with PySpark Pandas UDF Vectorization

Problem
Traditional UDFs (User-Defined Functions) run your custom Python function on each row individually, which can significantly slow down DataFrame operations.
Solution
Pandas UDFs solve this by batching data into chunks and applying vectorized pandas transformations across entire columns, rather than looping through rows.
As a result, they can be 10 to 100 times faster on large DataFrames.
☕️ Weekly Finds
lifelines [ML] – Survival analysis in Python with Kaplan Meier, Cox regression, and parametric models
nb-clean [Python Utils] – Clean Jupyter notebooks for version control by removing outputs, metadata, and execution counts
FuzzTypes [Python Utils] – Pydantic extension for autocorrecting field values using fuzzy string matching
Looking for a specific tool? Explore 70+ Python tools →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.