📅 Today’s Picks
Build Schema-Flexible Pipelines with Polars Selectors

Problem
Hard-coding column names can break your code when the schema changes.
When columns of the same type are added or removed, you must update your code manually.
Solution
Polars col() function accepts data types to select all matching columns automatically.
This keeps your code flexible and robust to schema changes.
Extract Text from Any Document Format with Docling
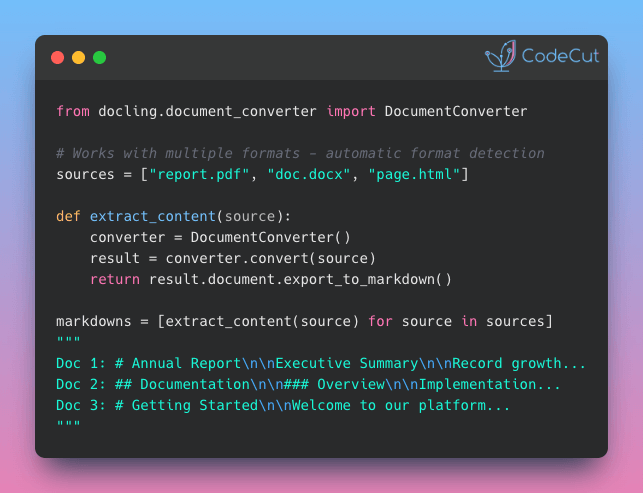
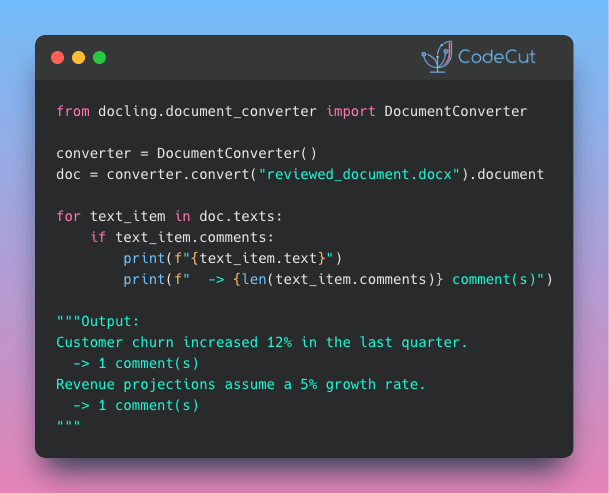
Problem
Have you ever needed to pull text from PDFs, Word files, slide decks, or images for a project? Writing a different parser for each format is slow and error-prone.
Solution
Docling’s DocumentConverter takes care of that by detecting the file type and applying the right parsing method for PDF, DOCX, PPTX, HTML, and images.
Other features of Docling:
- AI-powered image descriptions for searchable diagrams
- Export to pandas DataFrames, JSON, or Markdown
- Structure-preserving output optimized for RAG pipelines
- Built-in chunking strategies for vector databases
- Parallel processing handles large document batches efficiently
☕️ Weekly Finds
evals [LLM] – Framework for evaluating large language models (LLMs) or systems built using LLMs with existing registry of evals and ability to write custom evals
sklearn-bayes [ML] – Python package for Bayesian Machine Learning with scikit-learn API
databonsai [Data Processing] – Python library that uses LLMs to perform data cleaning tasks for categorization, transformation and curation
Looking for a specific tool? Explore 70+ Python tools →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.