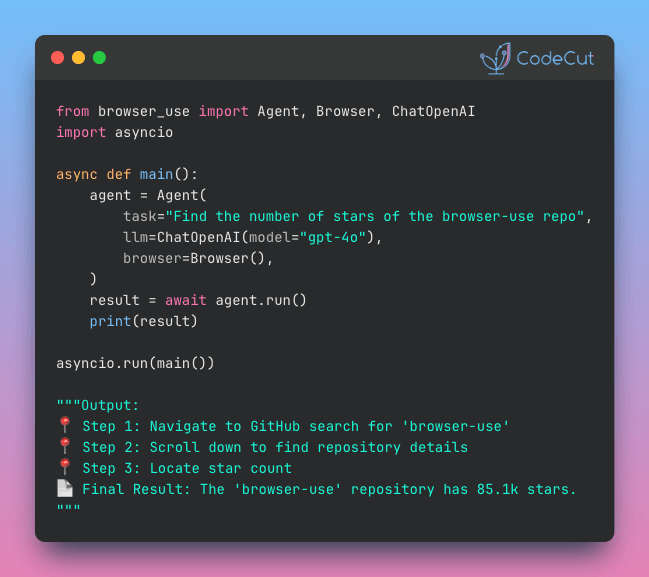
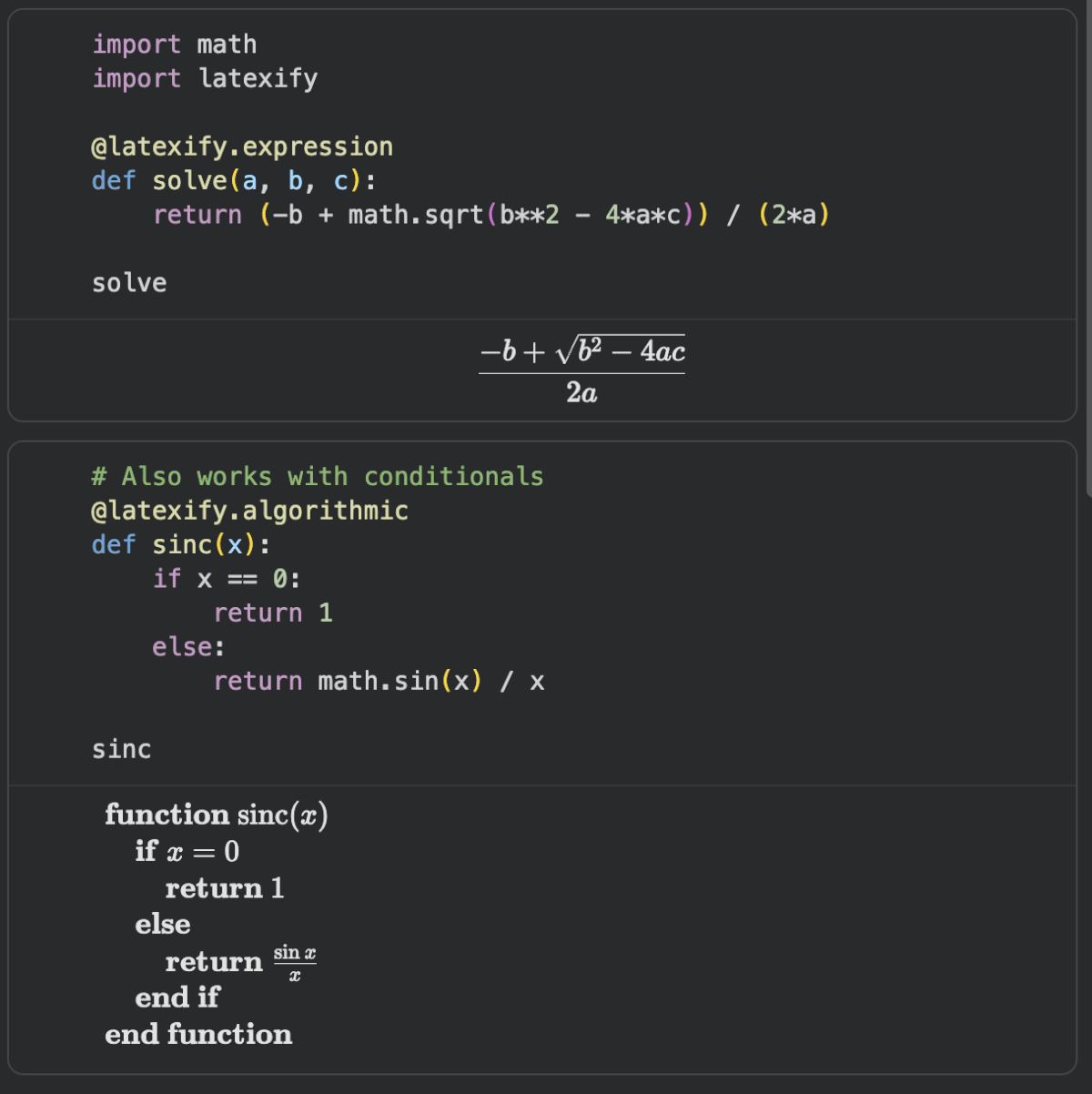
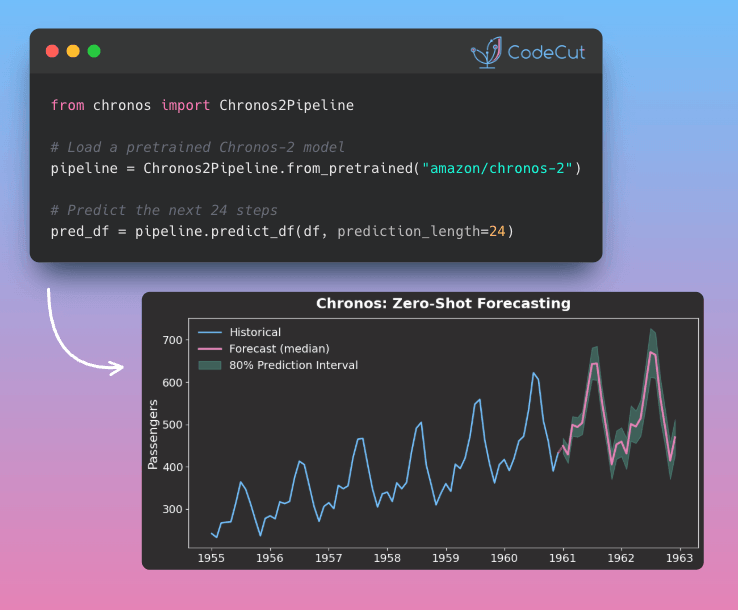
📅 Today’s Picks
Polars v1.35: Native Rolling Rank for Time Series
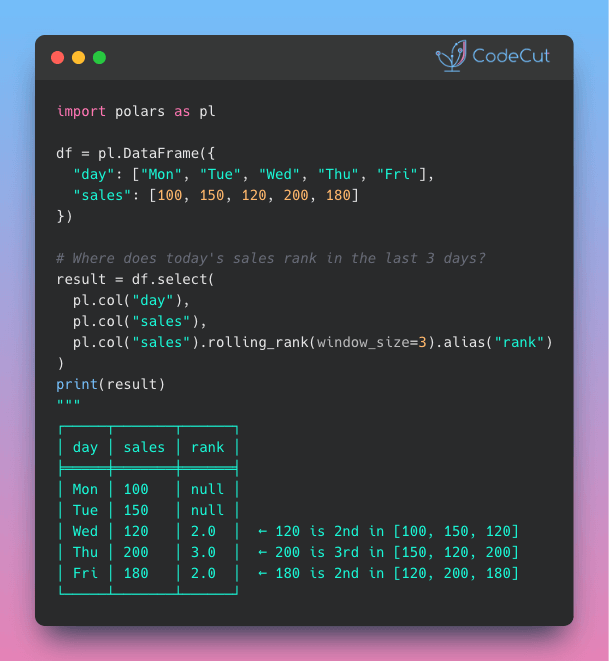
Problem
How do you rank values within a rolling window?
For example, you might want to compare today’s sales to the last 3 days to answer: “How does today’s sales compare to the last 3 days?”
Solution
Polars v1.35 introduces rolling_rank() for native window ranking operations.
How it works:
- Define a window size (e.g., last 3 values)
- Each value gets ranked against others in its window
- Rank 1 = lowest, Rank N = highest
This method is useful for tracking performance over time, detecting anomalies, or alerting when metrics underperform.
Coiled: Run Python in the Cloud with One Decorator (Sponsored)
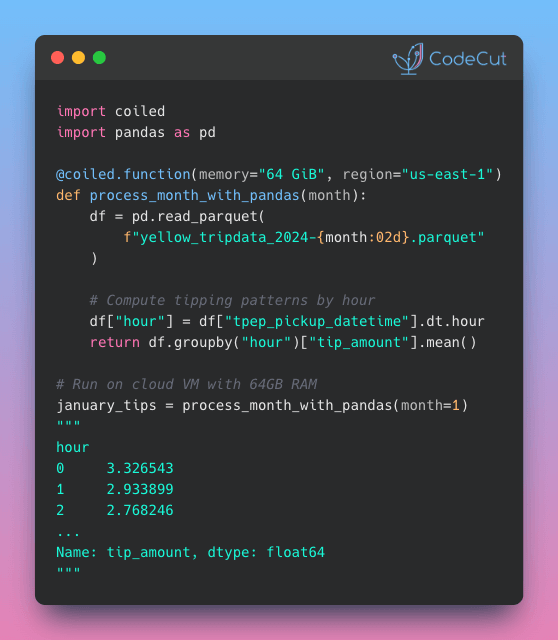
Problem
Imagine you need to run data processing on a file that is larger than your laptop’s RAM. What should you do?
Traditional solutions require buying more RAM, renting expensive cloud VMs, or learning Kubernetes. All of these add complexity and cost.
Solution
Coiled’s serverless functions let you run your Python code on cloud VMs with the memory you need by simply adding a decorator.
Key capabilities:
- Use any data framework: pandas, Polars, DuckDB, Dask, and more
- Process multiple files in parallel with .map()
- Sync local packages to cloud without Docker
- Cut costs with spot instances and auto-fallback
📢 ANNOUNCEMENTS
Cyber Monday: 58% Off Production-Ready Data Science
My book Production-Ready Data Science is on sale for Cyber Monday.
Get 58% off the ebook or 10% off the paperback through December 8th.
The book covers everything I’ve learned about taking data science from prototype to production: dependency management, testing, CI/CD, and workflow automation.
☕️ Weekly Finds
codon [Python Utils] – A high-performance, zero-overhead, extensible Python compiler with built-in NumPy support
khoj [LLM] – Your AI second brain. Self-hostable personal assistant with RAG, semantic search, and support for PDFs, Markdown, Notion, and more
lm-evaluation-harness [MLOps] – A framework for few-shot evaluation of language models. Powers Hugging Face’s Open LLM Leaderboard
Looking for a specific tool? Explore 70+ Python tools →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.