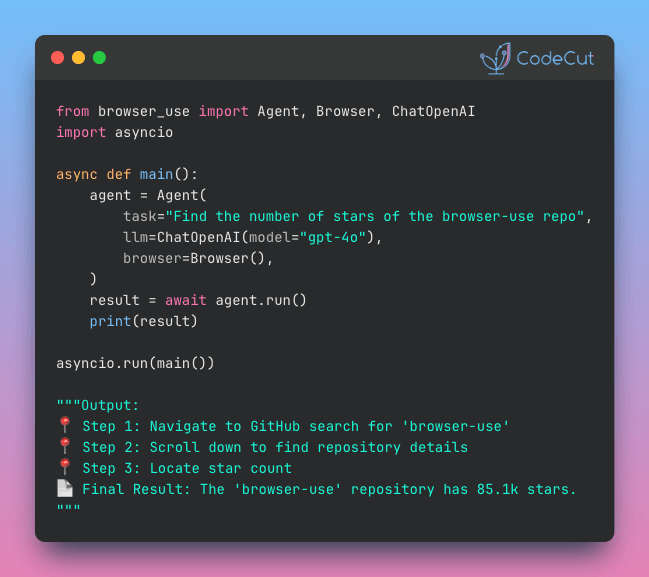
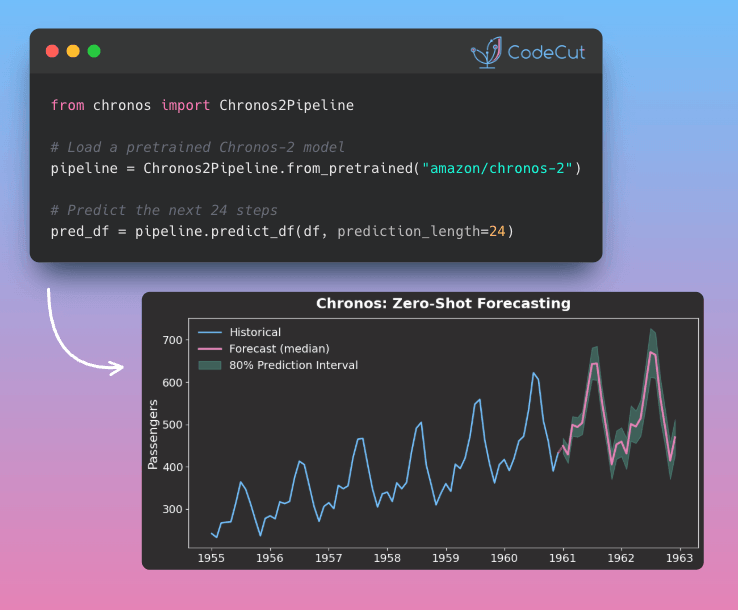
📅 Today’s Picks
Marimo: Keep All Notebook Cells in Sync Without Manual Reruns

Problem
In Jupyter notebooks, changing an input value doesn’t automatically update dependent cells.
Forget to rerun one cell, and you might make decisions based on outdated results without realizing anything is wrong.
Solution
Marimo automatically detects changes and re-executes all dependent cells.
When you change a variable like threshold from 50 to 30, every downstream cell that uses it updates immediately.
Build Scalable Pipelines with DuckDB Memory Spilling
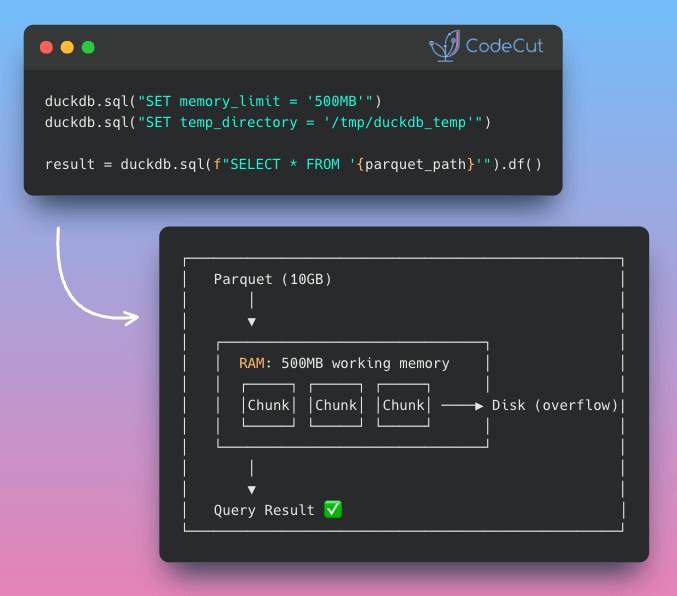
Problem
When datasets exceed available RAM, most tools crash mid-operation.
This forces manual data chunking or expensive hardware upgrades just to complete basic queries.
Solution
DuckDB automatically spills intermediate results to temporary files when data exceeds configured memory limits.
Key benefits:
- Process datasets larger than RAM without code changes
- Configure memory limits to prevent system crashes
- Automatic disk spillover when memory fills
- No manual chunking or batching required
📢 ANNOUNCEMENTS
Cyber Monday: 30% Off Production-Ready Data Science
My book Production-Ready Data Science is on sale for Cyber Monday.
Get 58% off the ebook or 10% off the paperback through December 8th.
The book covers everything I’ve learned about taking data science from prototype to production: dependency management, testing, CI/CD, and workflow automation.
☕️ Weekly Finds
Nano-PDF [LLM] – Natural language PDF editing using Gemini with multi-page parallel processing
Codon [Python Utils] – High-performance Python compiler that generates native machine code for 10-100x speedups
lm-evaluation-harness [LLM] – Unified framework for few-shot evaluation of language models across 200+ tasks
Looking for a specific tool? Explore 70+ Python tools →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.