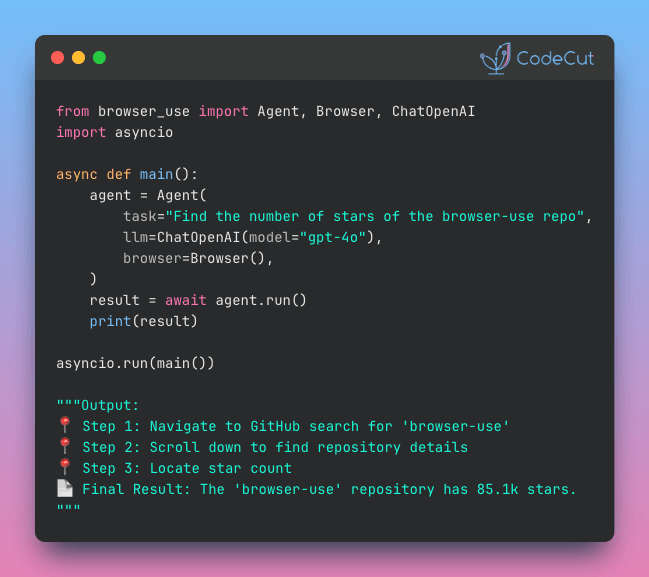
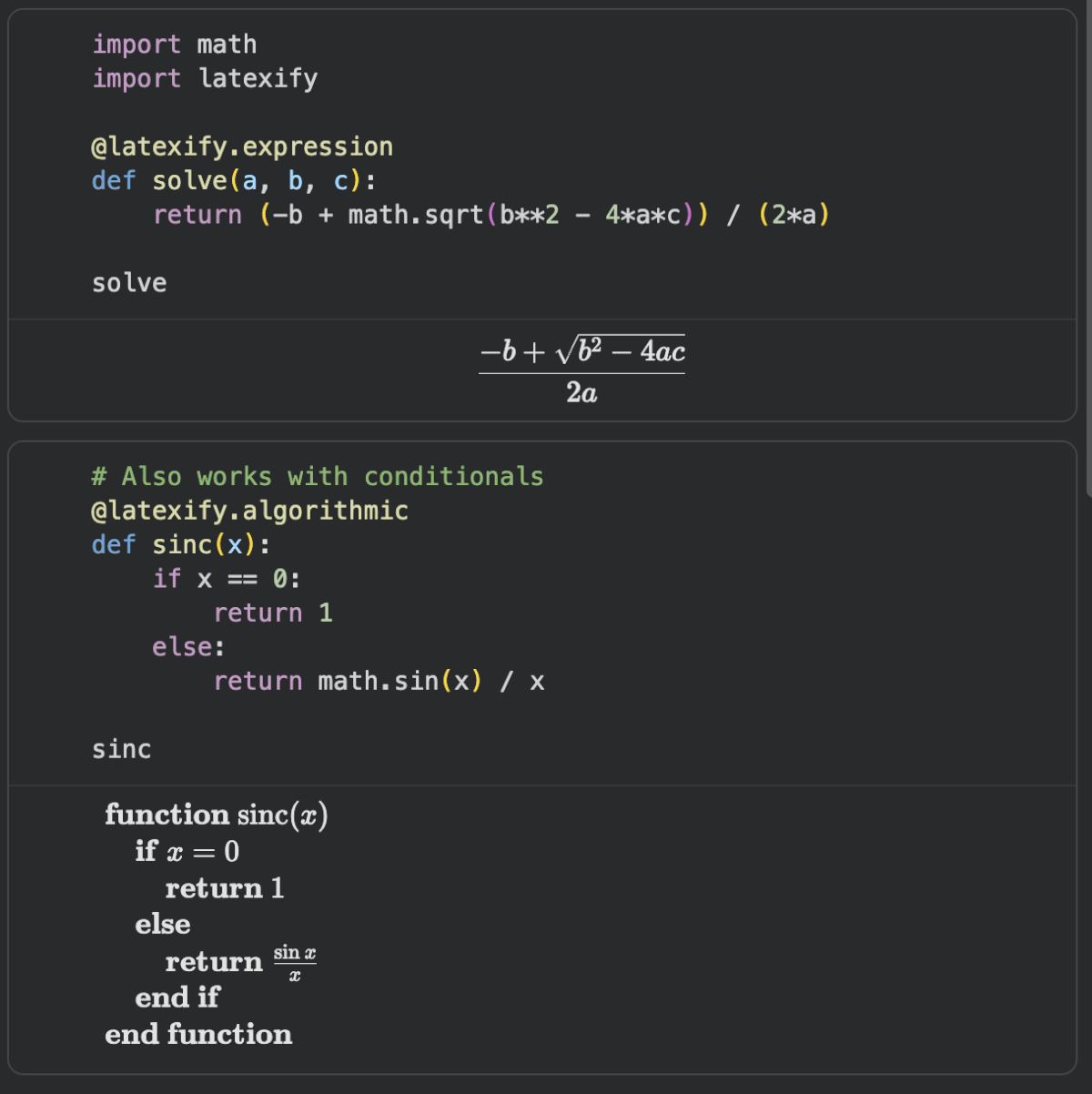
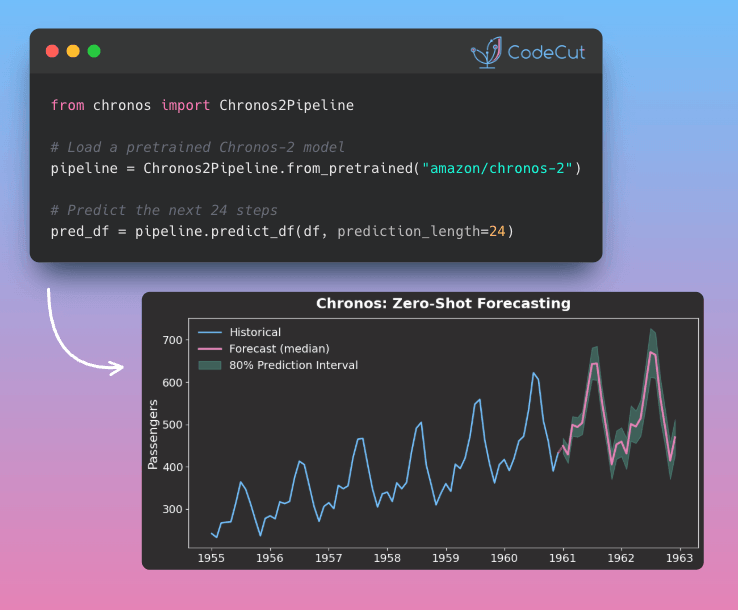
📅 Today’s Picks
PySpark 4.0: Query Nested JSON Without StructType

Problem
Extracting nested JSON in PySpark requires defining StructType inside StructType inside StructType. This creates verbose, inflexible code that breaks when your JSON structure changes.
Solution
PySpark 4.0’s Variant type lets you skip schema definitions entirely. All you need is parse_json() to load and variant_get() to extract with JSONPath.
Key benefits:
- No upfront schema definition
- Handle any nesting depth with simple $.path syntax
- Schema changes don’t break your code
- Extract only the fields you need, when you need them
☕️ Weekly Finds
toon [LLM] – Compact, human-readable JSON encoding for LLM prompts with schema-aware Token-Oriented Object Notation
cocoindex [Data Processing] – Ultra performant data transformation framework for AI with incremental processing
sqlfluff [Data Engineer] – Modular SQL linter and auto-formatter with support for multiple dialects and templated code
Looking for a specific tool? Explore 70+ Python tools →
📚 Latest Deep Dives
Visualize Machine Learning Results with Yellowbrick – Learn to visualize ML model performance with Yellowbrick. Create confusion matrices, ROC curves, and feature importance plots in scikit-learn pipelines.
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.