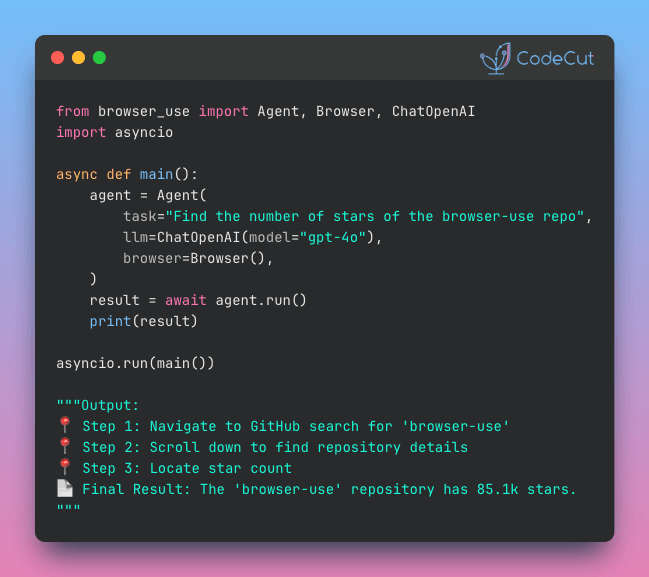
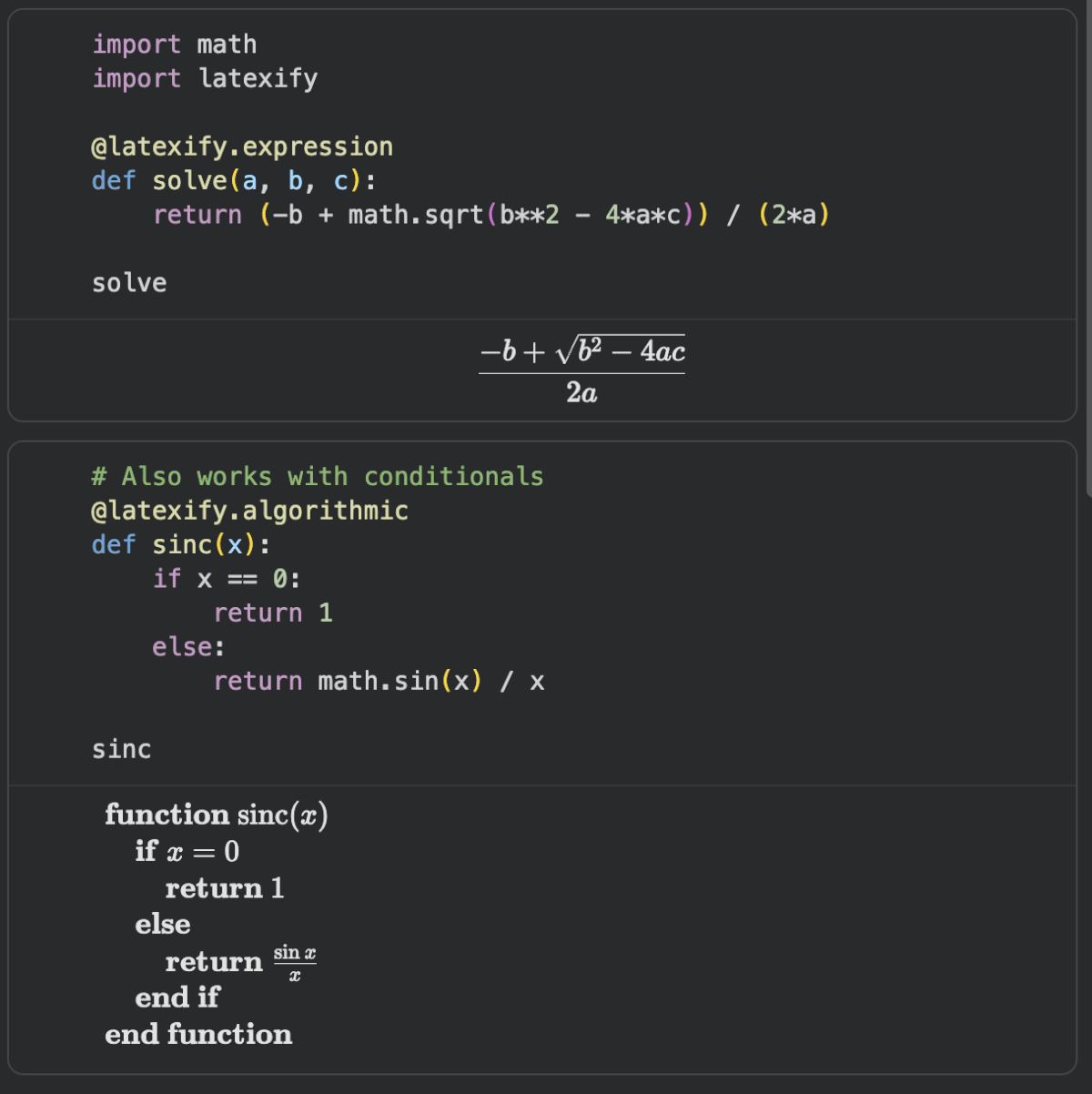
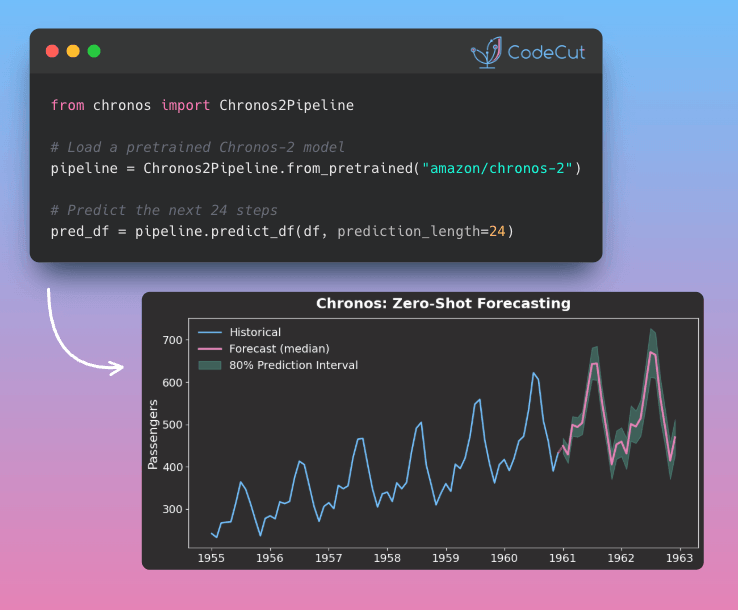
Grab your coffee. Here are this week’s highlights.
📅 Today’s Picks
Build AI Agent Memory with Graphiti Knowledge Graphs
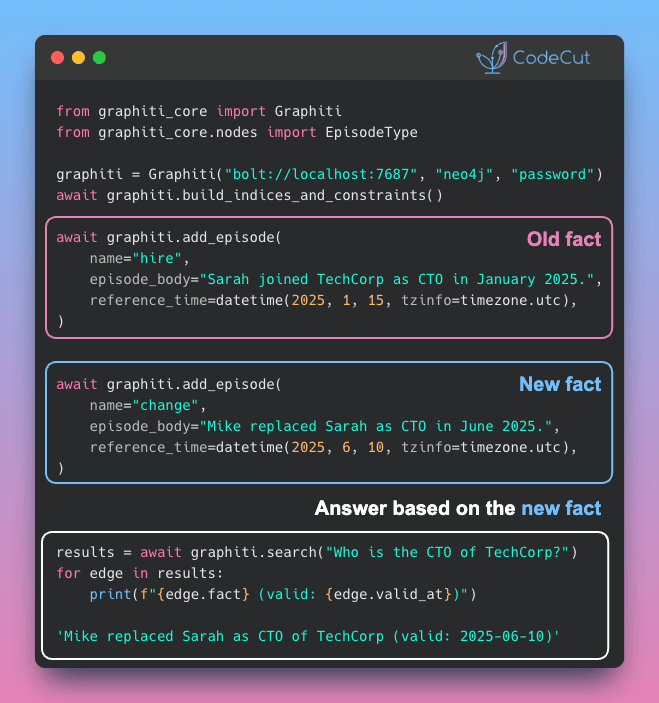
Problem
Traditional RAG pipelines rely on batch processing and static document summaries. When data changes, you re-embed, re-index, and wait.
That delay means your agent is always working with stale information, unable to track how facts evolve over time.
Solution
Graphiti is an open-source Python framework that builds knowledge graphs with real-time, incremental updates. This lets you add new information at any time without reprocessing your entire dataset.
Key features:
- Track when facts happened and when they were recorded, so you always know what’s current
- Search by meaning, keywords, or relationships in one query
- Get the most relevant results for a specific person, company, or entity
- Works with Neo4j, FalkorDB, and Kuzu as the graph backend
Polars sink_csv: Stream Million-Row Exports Without Memory Spikes

Problem
Writing large DataFrames to CSV is memory-intensive because the entire dataset is serialized in memory before being written to disk.
Solution
Polars’ streaming CSV sink avoids this by writing data in chunks rather than all at once.
Key benefits:
- Eliminate out-of-memory errors on large exports
- Write multi-million row DataFrames with minimal RAM
- Support for cloud storage destinations (S3, GCS, Azure)
Switch from write_csv to sink_csv on a lazy frame to enable streaming.
☕️ Weekly Finds
Flowise [AI Agents] – Low-code platform for building AI agents and workflows visually with drag-and-drop components
cleanlab [Machine Learning] – Data-centric AI package that automatically detects data quality issues, label errors, and outliers in ML datasets
OpenBB [Finance] – Open-source financial data platform for analysts, quants, and AI agents with dozens of data integrations
Looking for a specific tool? Explore 70+ Python tools →
📚 Latest Deep Dives
5 Python Tools for Structured LLM Outputs: A Practical Comparison – Compare 5 Python tools for structured LLM outputs. Learn when to use Instructor, PydanticAI, LangChain, Outlines, or Guidance for JSON extraction.
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.