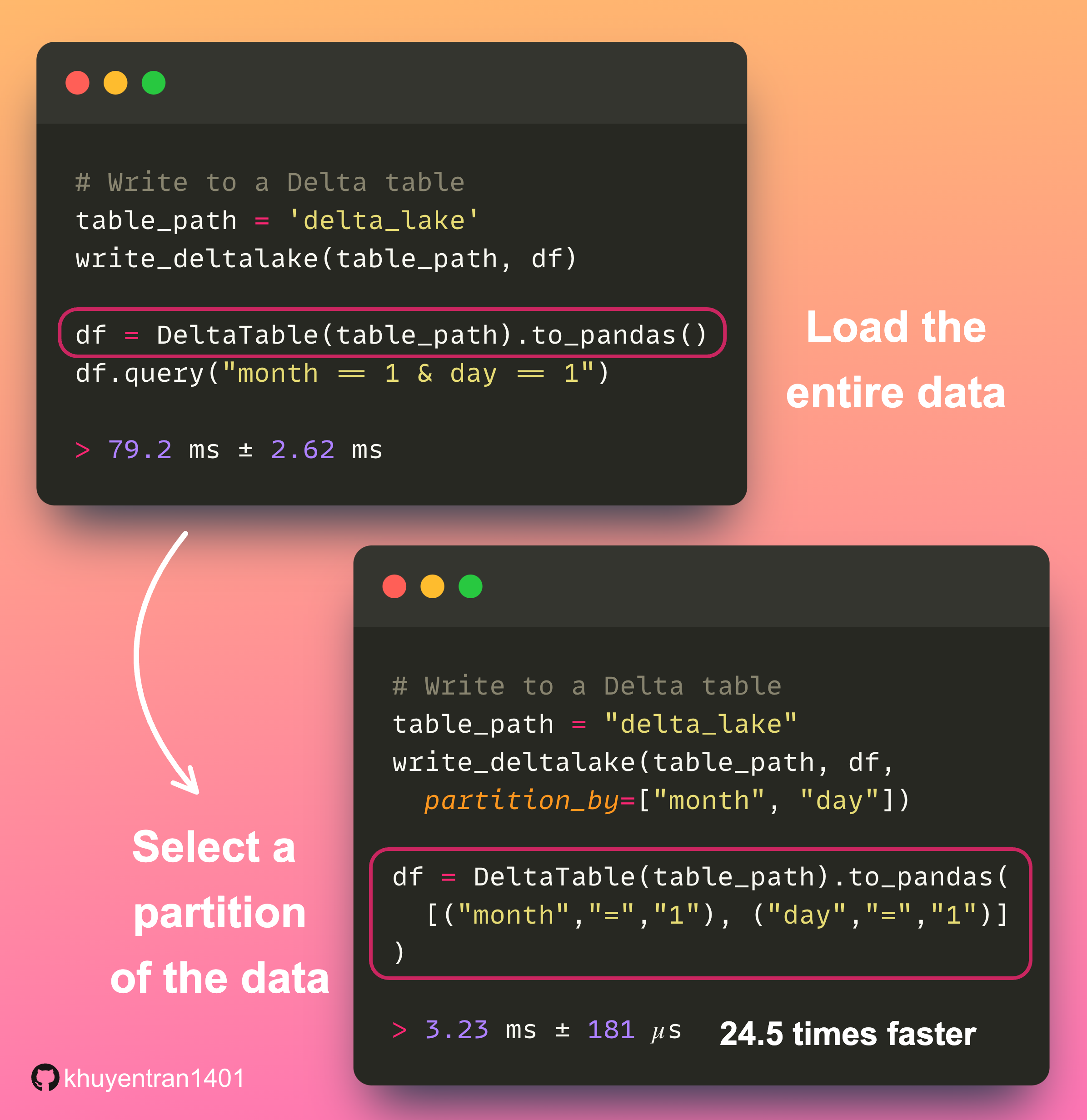

Partitioning data allows queries to target specific segments rather than scanning the entire table, which speeds up data retrieval.
The code above uses Delta Lake to select partitions from a pandas DataFrame. Partitioned data loading is approximately 24.5 times faster than loading the complete dataset and then querying a particular subset.