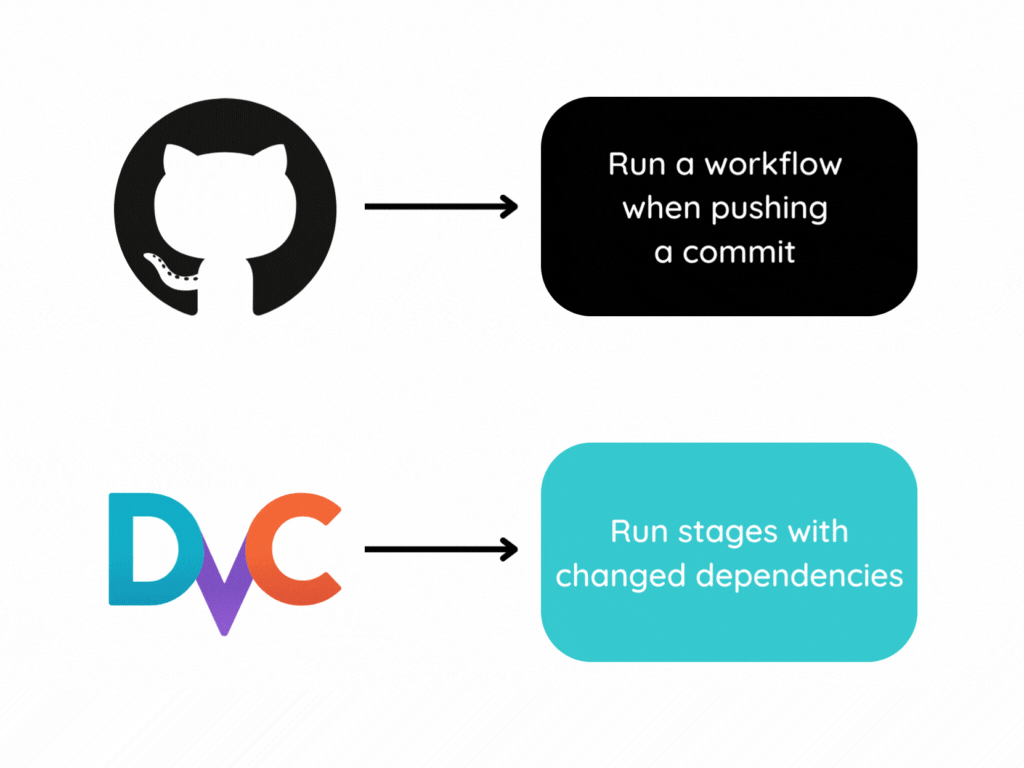
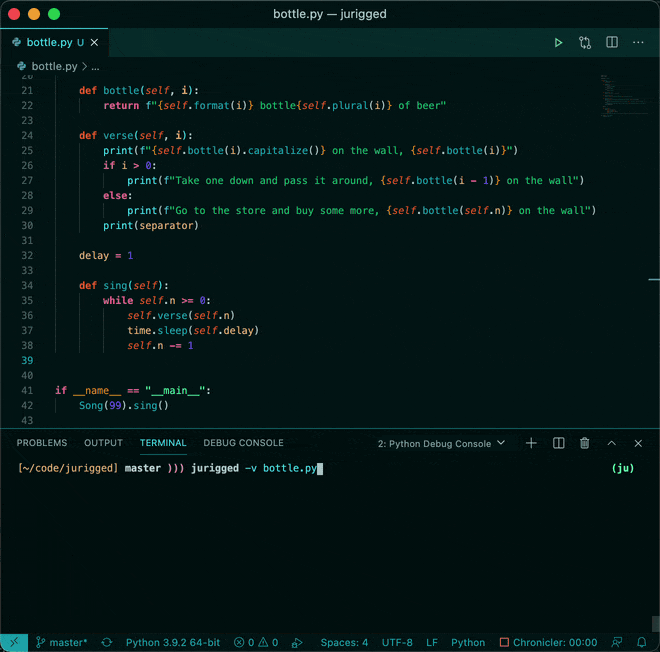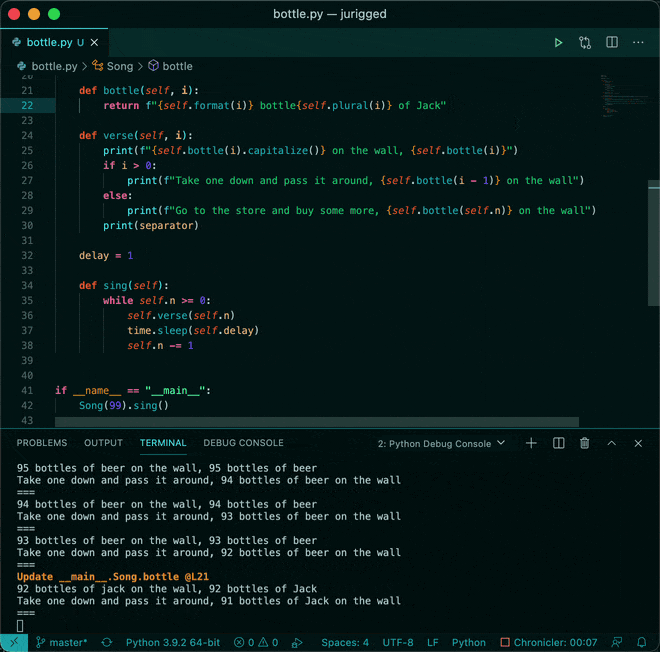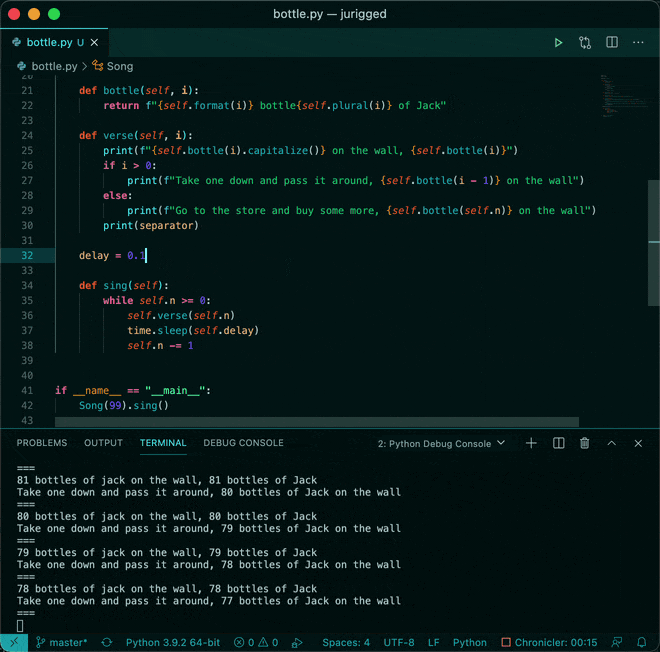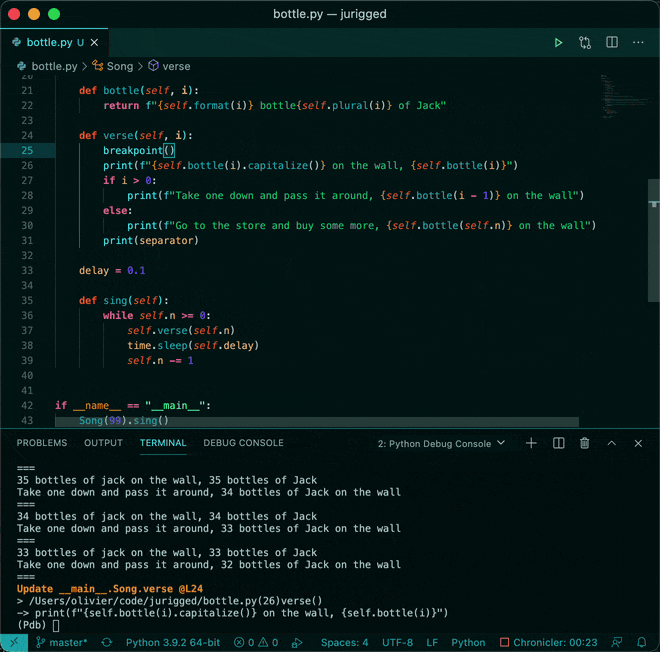
Data Analysis & Manipulation Analyze Data Manage Data Feature Engineer SQL Machine Learning & AI Machine Learning Natural Language Processing Time Series LLM Code Quality Python Tips Python Utilities Code Optimization DevOps Testing Git Command Line Environment Management Better Outputs Tools NumPy Pandas Polars PySpark Delta Lake DuckDB Jupyter Notebook Visualization & Reporting Dashboard Visualization Workflow & Automation Workflow Automation Scrape Data X Streamline Code Updates with DVC and GitHub Actions Vectorized Operations in PySpark: pandas_udf vs Standard UDF Hyperfine: Compare the Speed of Two Commands Compare Dependencies of Two Requirements Files Jurigged: Seamless Live Code Updates Without Restarts Write Modular SQL Code with dbt 5 Steps to Transform Messy Functions into Production-Ready Code pyfakefs: Create Fake File System in Memory for Testing Optimizing PySpark Queries with Nested Data Structures Page1 … Page4 Page5 Page6