

Table of Contents
- Motivation
- What is PRegEx?
- Capture URLs
- Capture Time
- Capture Phone Numbers
- Capture an Email Address
- Next Step
Motivation
Imagine you are trying to find all URLs inside a text. Each of these URLs must:
- Start with either
http://orhttps://or the domain of the URL - End with either
.comor.org
You might end up writing a complicated regular expression(RegEx) like the one below:
import re
text = """You can find me through my
website codecut.ai/ or
GitHub https://github.com/khuyentran1401"""
re.findall(
"(?:https?://)?[^\s]+(?:\.com|\.org)[^\s]+",
text
)
This RegEx is difficult to read and create. Is there a way that you can write a more human-readable RegEx with ease?
That is when PRegEx comes in handy.
Stay Current with CodeCut
Easy-to-digest articles on Python, AI, and open-source tools. Delivered twice a week.
What is PRegEx?
PRegEx is a Python package that allows you to construct RegEx patterns in a more human-friendly way.
To install PRegEx, type:
pip install pregex
The version of PRegEx that will be used in this article is 2.0.1:
pip install pregex==2.0.1
💻 Get the Code: Open the notebook in Google Colab to run it in your browser, or grab the source from GitHub.
To learn how to use PRegEx, let’s start with some examples.
Capture URLs
Get a Simple URL
First, let’s try to get a URL in a text using PRegEx.
from pregex.core.classes import AnyButWhitespace
from pregex.core.quantifiers import OneOrMore
from pregex.core.operators import Either
text = "You can find me through GitHub https://github.com/khuyentran1401"
pre = (
"https://"
+ OneOrMore(AnyButWhitespace())
+ Either(".com", ".org")
+ OneOrMore(AnyButWhitespace())
)
pre.get_matches(text)
In the code above, we use:
AnyButWhitespace()to match any character except for whitespace charactersOneOrMore()to match the provided pattern one or more timesEither()to match either one of the provided patterns
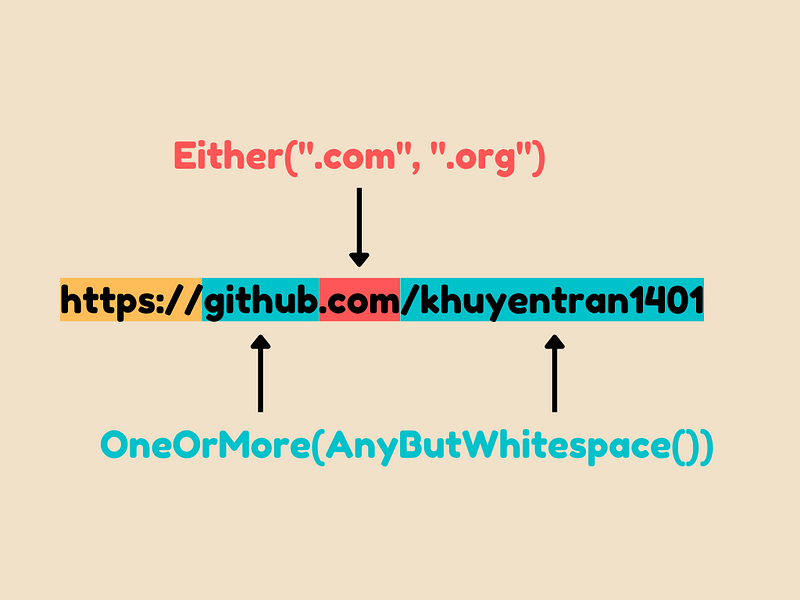
Specifically,
OneOrMore(AnyButWhitespace())matches one or more characters that are not whitespace charactersEither(".com", ".org")matches either.comor.org
HTTP or HTTPS
Sometimes, a URL might use the scheme http instead of https. Let’s make the character s optional by using Optional():

from pregex.core.quantifiers import Optional
text = "You can find me through GitHub http://github.com/khuyentran1401"
pre = (
"http"
+ Optional("s")
+ "://"
+ OneOrMore(AnyButWhitespace())
+ Either(".com", ".org")
+ OneOrMore(AnyButWhitespace())
)
pre.get_matches(text)
Match URL without a Scheme
Some URLs in a text might not include a scheme such as https or http. Let’s make the scheme optional with Optional.

To make our code more readable, we will assign PRegEx’s methods to a variable.
text = "You can find me through my website codecut.ai/ or GitHub https://github.com/khuyentran1401"
at_least_one_character_except_white_space = OneOrMore(AnyButWhitespace())
optional_scheme = Optional("http" + Optional("s") + "://")
domain_choice = Either(".com", ".org")
pre = (
optional_scheme
+ at_least_one_character_except_white_space
+ domain_choice
+ at_least_one_character_except_white_space
)
pre.get_matches(text)
Let’s take a look at the underlying RegEx pattern:
pre.get_pattern()
We have just avoided creating a complicated pattern with some human-readable lines of code!
Capture Time
AnyDigit() matches any numeric character. Let’s use this to match a time in a text.
from pregex.core.classes import AnyDigit
text = "It is 6:00 pm now"
pre = AnyDigit() + ":" + AnyDigit()
pre.get_matches(text)
Right now, we only match one digit on either side of :. Let’s make this more general by wrapping OneOrMore() around AnyDigit():

pre = OneOrMore(AnyDigit()) + ":" + OneOrMore(AnyDigit())
pre.get_matches(text)
Capture Phone Numbers
Common formats for a phone number are:
##########
###-###-####
### ### ####
###.###.####
These formats either have punctuation or nothing between numbers. We can use AnyFrom("-", " ", ".") to match either -, ., or space.
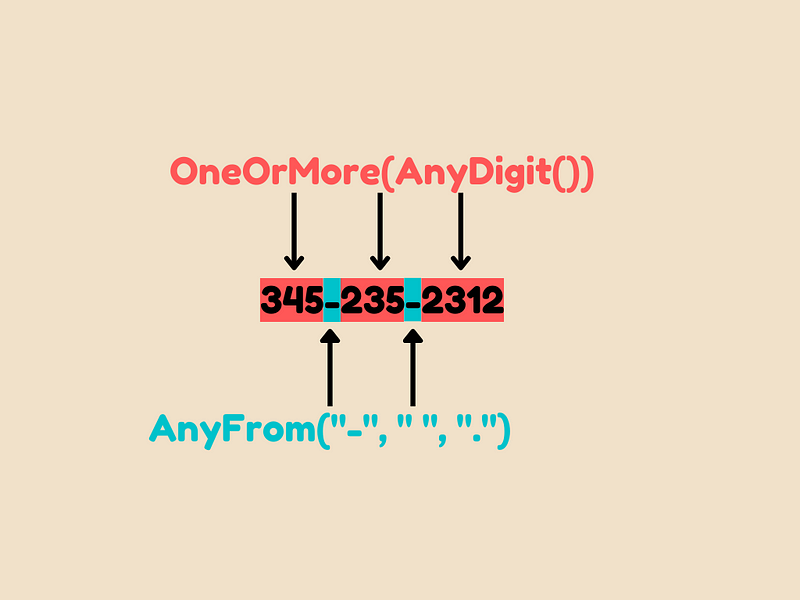
We also use Optional() to make punctuation optional.
from pregex.core.classes import AnyFrom
text = "My phone number is 3452352312 or 345-235-2312 or 345 235 2312 or 345.235.2312"
punctuation = AnyFrom("-", " ", ".")
optional_punctuation = Optional(punctuation)
at_least_one_digit = OneOrMore(AnyDigit())
pre = (
at_least_one_digit
+ optional_punctuation
+ at_least_one_digit
+ optional_punctuation
+ at_least_one_digit
)
pre.get_matches(text)
Capture an Email Address
Now let’s utilize what we have learned so far to capture an email address from a text.

text = "My email is abcd@gmail.com"
pre = (
OneOrMore(AnyButWhitespace())
+ "@"
+ OneOrMore(AnyButWhitespace())
+ Either(".com", ".org", ".io", ".net")
)
pre.get_matches(text)
Next Step
This article gives you an overview of how to use PRegEx to match complicated patterns without spending hours on them.
I encouraged you to check out PRegEx’s documentation for other useful methods.
📚 Want to go deeper? Learning new techniques is the easy part. Knowing how to structure, test, and deploy them is what separates side projects from real work. My book shows you how to build data science projects that actually make it to production. Get the book →
Stay Current with CodeCut
Easy-to-digest articles on Python, AI, and open-source tools. Delivered twice a week.

2 thoughts on “PRegEx: Write Human-Readable Regular Expressions in Python”
Absolutely amazing library. Would consider using PregEx in my next workflow.
Thank you! I’m glad to hear that