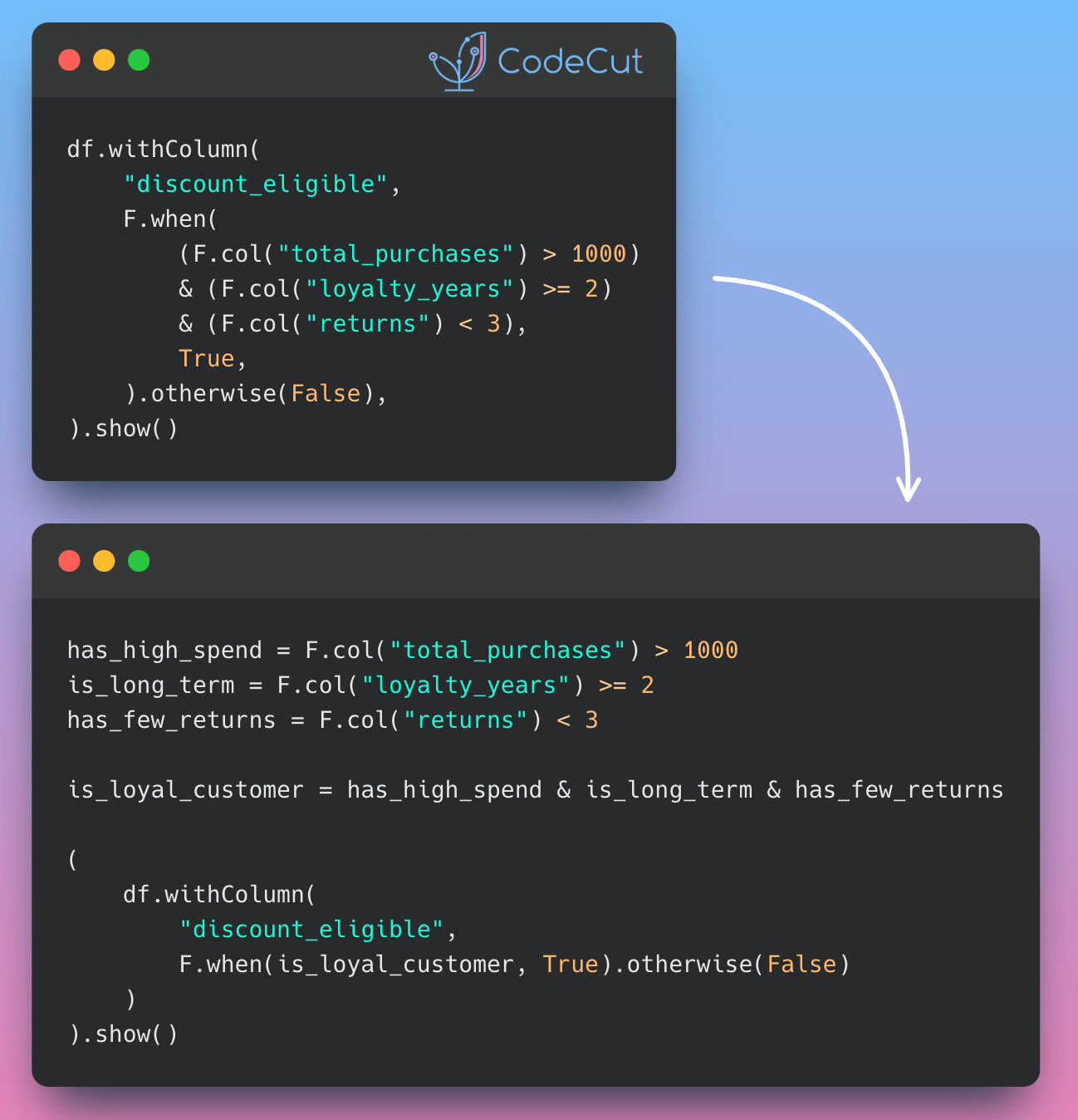
Long chains of logical conditions in PySpark can make code difficult to understand and modify.
from pyspark.sql import functions as F
data = [(1200, 3, 1), (2000, 2, 0), (1500, 3, 2), (1100, 2, 1)]
df = spark.createDataFrame(data, ["total_purchases", "loyalty_years", "returns"])df.withColumn(
"discount_eligible",
F.when(
(F.col("total_purchases") > 1000)
& (F.col("loyalty_years") >= 2)
& (F.col("returns") < 3),
True,
).otherwise(False),
).show()+---------------+-------------+-------+-----------------+
|total_purchases|loyalty_years|returns|discount_eligible|
+---------------+-------------+-------+-----------------+
| 1200| 3| 1| true|
| 2000| 2| 0| true|
| 1500| 3| 2| true|
| 1100| 2| 1| true|
+---------------+-------------+-------+-----------------+To improve readability and maintainability, break down complex logic into meaningful variables:
# Define loyal customer conditions
has_high_spend = F.col("total_purchases") > 1000
is_long_term = F.col("loyalty_years") >= 2
has_few_returns = F.col("returns") < 3
# Combine conditions for discount eligibility
loyal_customer_condition = has_high_spend & is_long_term & has_few_returns
(
df.withColumn(
"discount_eligible", F.when(loyal_customer_condition, True).otherwise(False)
)
).show()+---------------+-------------+-------+-----------------+
|total_purchases|loyalty_years|returns|discount_eligible|
+---------------+-------------+-------+-----------------+
| 1200| 3| 1| true|
| 2000| 2| 0| true|
| 1500| 3| 2| true|
| 1100| 2| 1| true|
+---------------+-------------+-------+-----------------+Benefits of this approach:
- Business logic is clearly documented through function names.
- Easier to add new conditions without cluttering main logic.





