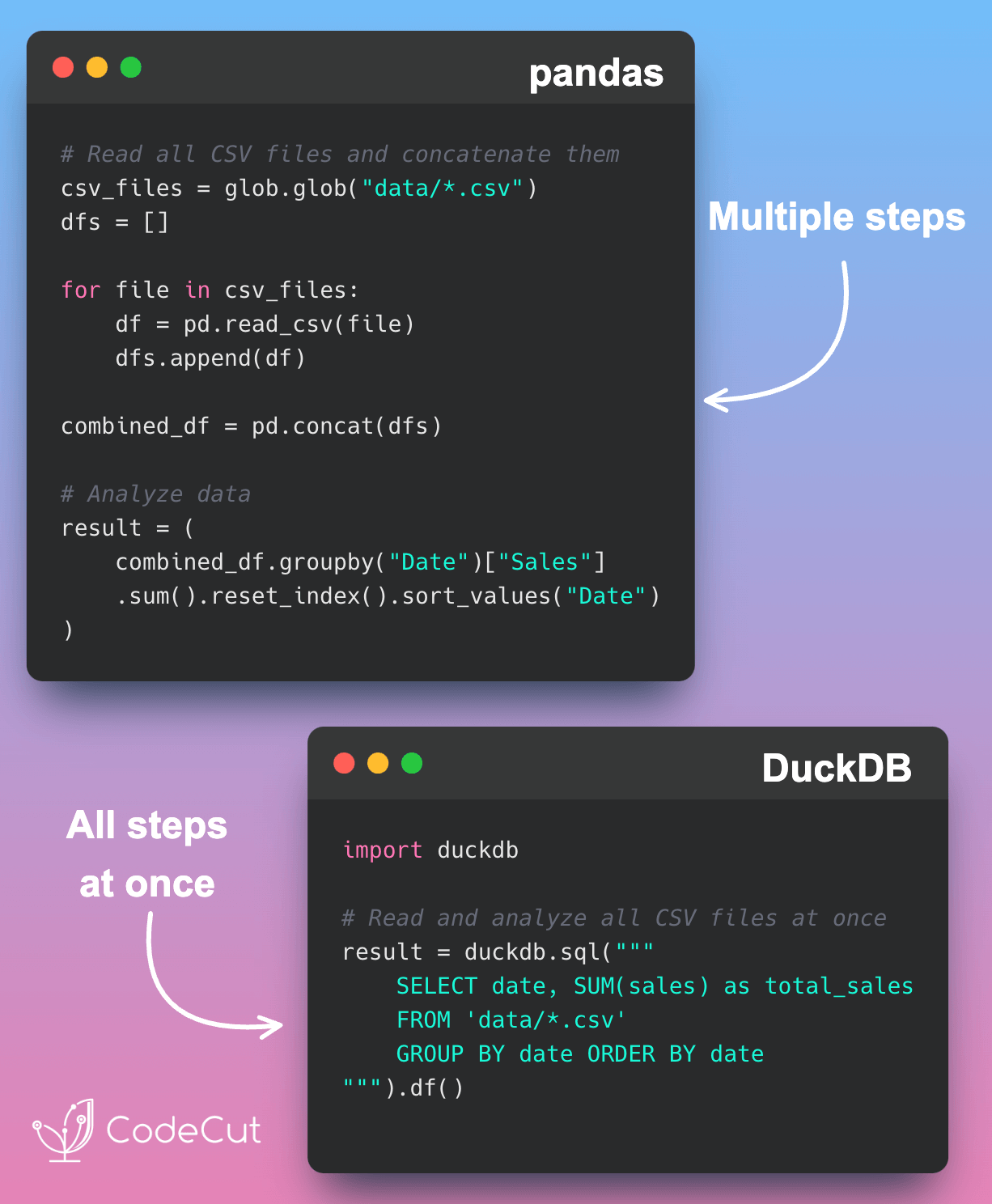
Motivation
Handling large, nested Parquet files can be challenging as it often requires flattening the data or writing custom scripts to extract nested fields. These steps can be time-consuming, error-prone, and may not scale well for complex datasets.
For example, with pandas, you might need to preprocess the data like this:
import pandas as pd
# Create a nested dataset and save it as a Parquet file
data = {
"id": [1, 2],
"details": [
{"name": "Alice", "age": 25},
{"name": "Bob", "age": 30}
]
}
# Convert to a DataFrame
df = pd.DataFrame(data)
# Save as a nested Parquet file
df.to_parquet("nested_data.parquet")
print(df)
id details
0 1 {'name': 'Alice', 'age': 25}
1 2 {'name': 'Bob', 'age': 30}# Read the DataFrame from the Parquet file
df = pd.read_parquet("nested_data.parquet")
# Create a new DataFrame with the flattened structure
flat_df = pd.DataFrame({
"id": df["id"],
"name": [detail["name"] for detail in df["details"]],
"age": [detail["age"] for detail in df["details"]]
})
print(flat_df)
Output:
id name age
0 1 Alice 25
1 2 Bob 30This approach requires additional logic to flatten the nested data, which can lead to unnecessary complexity.
Introduction to DuckDB
DuckDB is an analytical in-process SQL database management system designed for high performance, portability, and simplicity. It supports a rich SQL dialect with advanced features, including the ability to query nested and complex data types directly.
DuckDB can be easily installed via pip for Python users:
pip install duckdbDuckDB eliminates the need for pre-processing nested data by allowing direct SQL queries on nested Parquet files. This makes it an efficient tool for processing structured and semi-structured data.
In this post, we will demonstrate how to query nested Parquet files directly using DuckDB.
Query Nested Parquet Files
DuckDB provides a simple way to query nested Parquet files directly without the need for flattening or complex preprocessing.
Here’s how you can query a nested Parquet file using DuckDB:
import duckdb
# Query the nested Parquet file directly
query_result = duckdb.query("""
SELECT
id,
details.name AS name,
details.age AS age
FROM read_parquet('nested_data.parquet')
""").to_df()
print(query_result)In this example:
- The
read_parquetfunction reads the nested Parquet file. - Nested fields are accessed using dot notation, such as
details.nameanddetails.age.
Output:
id name age
0 1 Alice 25
1 2 Bob 30The result is a flattened representation of the nested data, queried directly from the Parquet file without additional preprocessing.
Conclusion
DuckDB simplifies working with nested Parquet files by allowing direct SQL queries on nested fields. This feature reduces complexity and saves time, making it a valuable tool for data analysis and engineering tasks.