
Motivation
Creating high-quality training data for NLP models is a critical but time-consuming process. Without a systematic approach to data labeling and quality control, data scientists often struggle with scaling their labeling efforts while maintaining consistency.
Data scientists need to iterate quickly between manual labeling, pattern discovery, and automation, but most tools force them to handle these steps separately, making the process inefficient and error-prone.
Example:
# Traditional approach: Manual labeling + separate automation
import pandas as pd
from sklearn.model_selection import train_test_split
# Manual labeling in spreadsheet
labeled_data = pd.read_csv("labeled_data.csv")
# Try to automate with basic rules (error-prone and hard to maintain)
def label_rules(text):
if any(word in text.lower() for word in ['great', 'excellent']):
return 'positive'
elif any(word in text.lower() for word in ['bad', 'terrible']):
return 'negative'
return None
# No way to easily combine manual and automated labels
labeled_data['rule_based'] = labeled_data['text'].apply(label_rules)
Introduction to Refinery
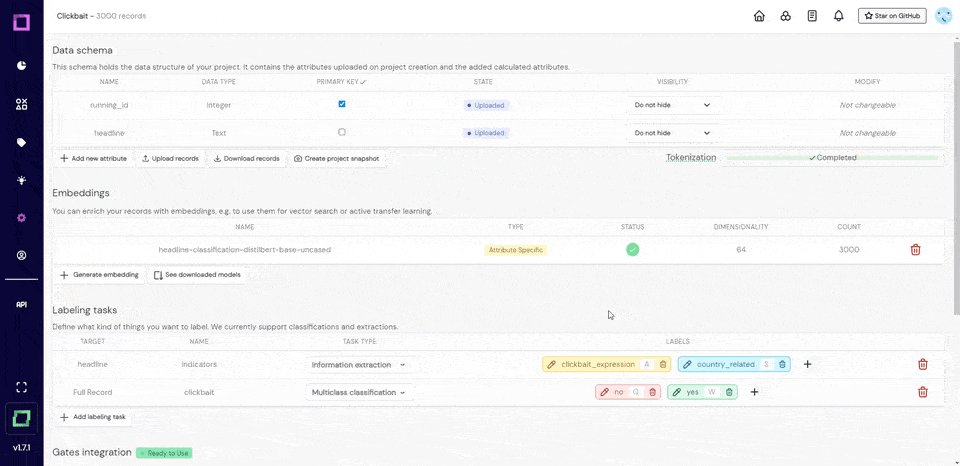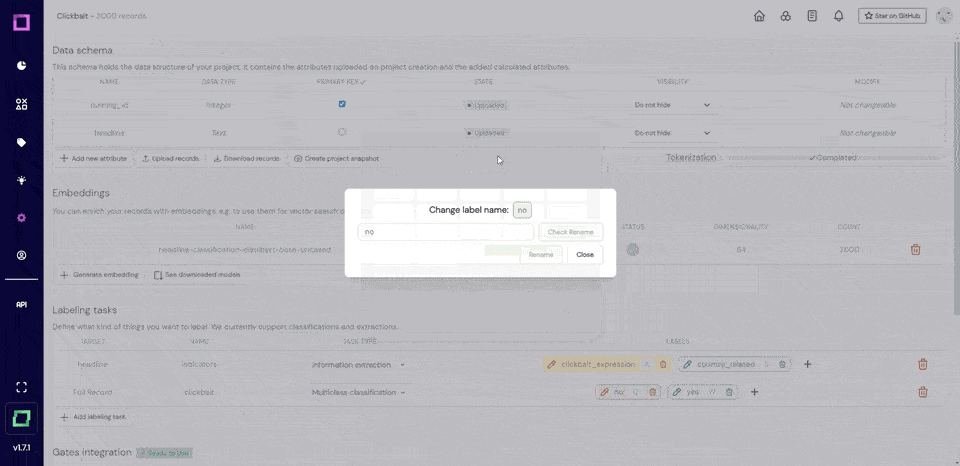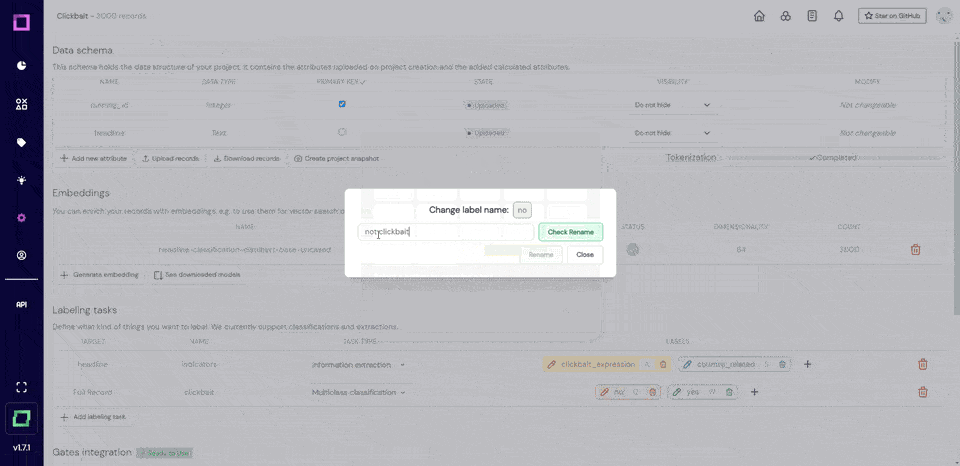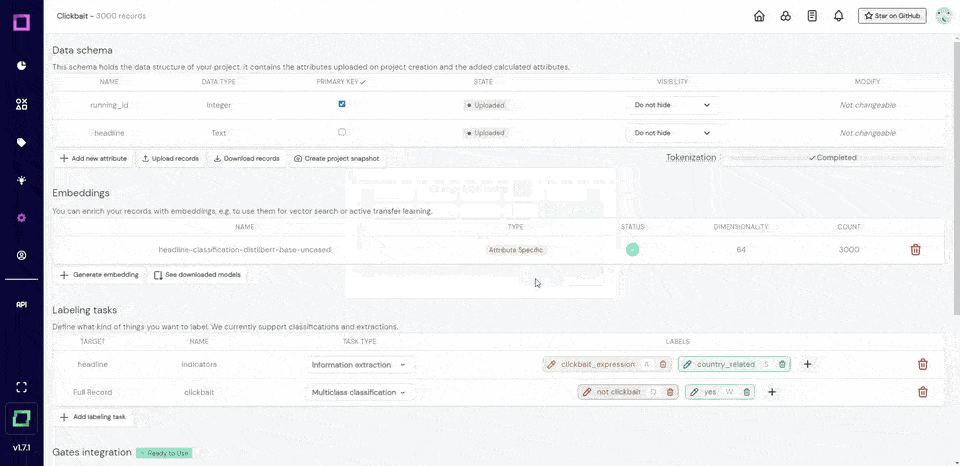
Refinery is an open-source tool that provides an integrated environment for building and maintaining NLP training data.
While Refinery doesn’t eliminate the need for manual labeling, it ensures that your valuable time is spent efficiently by combining manual expertise with automation in a unified workflow. Installation is simple:
pip install kern-refineryIntegrated Labeling Workflow
Refinery provides a systematic workflow for creating training data:
- Start a project – Create a new project or use a sample one
- Look at your data – Browse through your data to understand what you’re working with
- Add embeddings – Turn your text into numbers that capture meaning (optional)
- Set up labeling tasks – Define what you want to label (categories or text spans)
- Label some examples – Manually label data to teach the system
- Find patterns – Sort and filter your data to spot recurring patterns
- Create rules – Write simple functions that automatically apply labels based on patterns
- Add smart helpers – Use machine learning to predict labels based on your examples
- Combine all approaches – Merge predictions from all sources into final labels
- Evaluation – Create filtered views to verify and assess prediction quality
- Download your data – Export your labeled dataset for model training
You can repeat these steps to keep improving your dataset.
For more details on these steps, view Refinery’s quickstart guide.
Conclusion
Refinery transforms labeling from a linear manual process into an iterative workflow that combines human expertise with automation, enabling data scientists to build higher-quality training datasets more efficiently.