
Motivation
Consider you’re an e-commerce platform aiming to enhance recommendation personalization. Your data resides in S3.
To refine recommendations, you plan to retrain recommendation models using fresh customer interaction data whenever a new file is added to S3. But how exactly do you approach this task?
Solutions
Two common solutions to this problem are:
- AWS Lambda: A serverless compute service by AWS, allowing code execution in response to events without managing servers.
- Open-source orchestrators: Tools automating, scheduling, and monitoring workflows and tasks, usually self-hosted.
Using an open-source orchestrator offers advantages over AWS Lambda:
- Cost-Effectiveness: Running long tasks on AWS Lambda can be costly. Open-source orchestrators let you use your infrastructure, potentially saving costs.
- Faster Iteration: Developing and testing workflows locally speeds up the process, making it easier to debug and refine.
- Environment Control: Full control over the execution environment allows you to customize your development tools and IDEs to match your preferences.

While you could solve this problem in Apache Airflow, it would require complex infrastructure and deployment setup. Thus, we’ll use Kestra, which offers an intuitive UI and can be launched in a single Docker command.
Feel free to play and fork the source code of this article here:
Workflow Summary
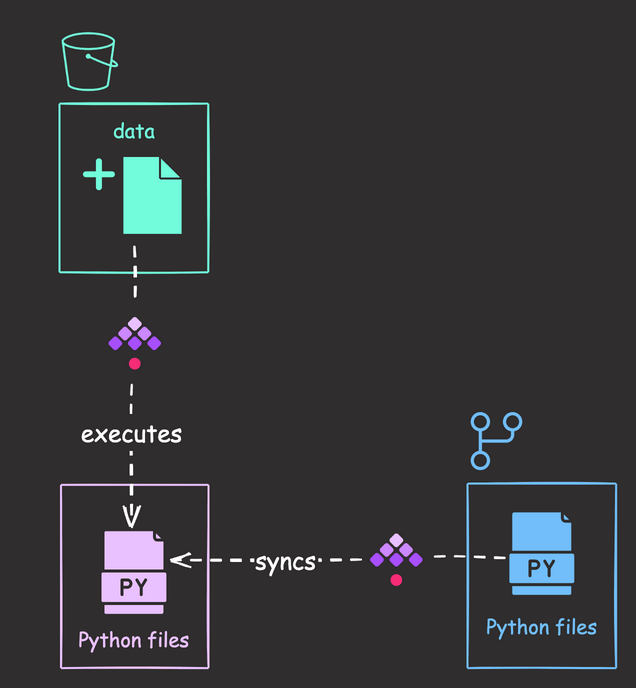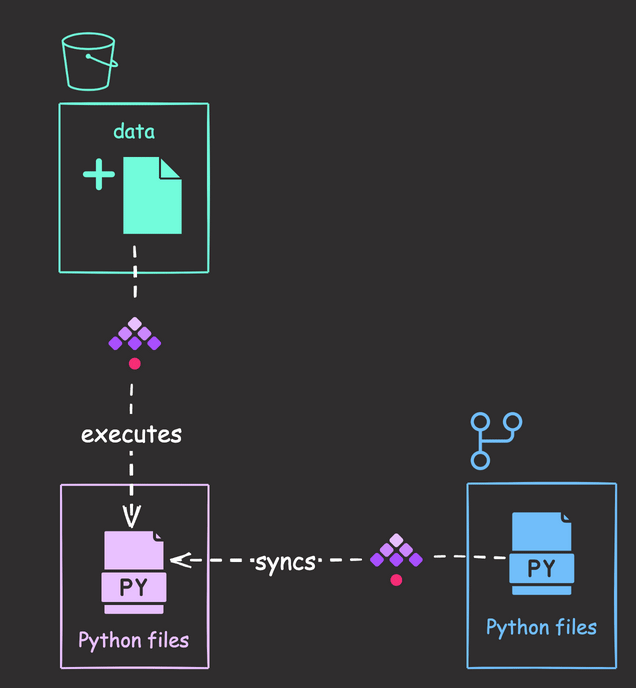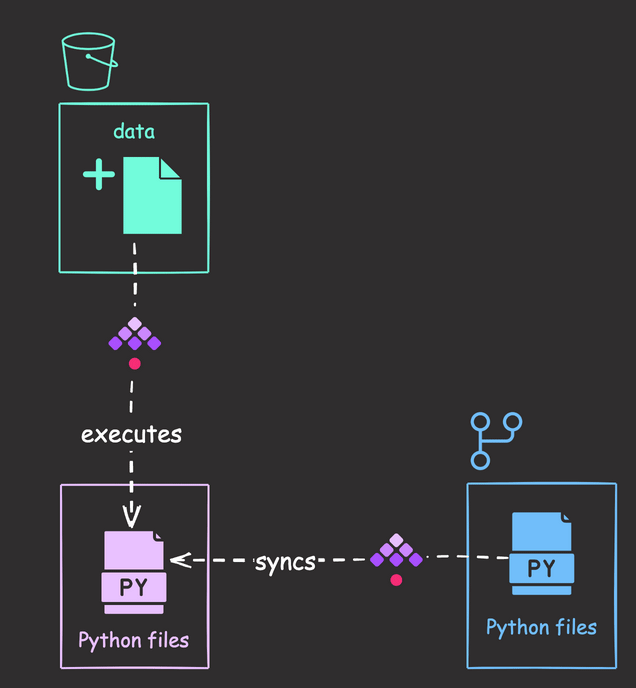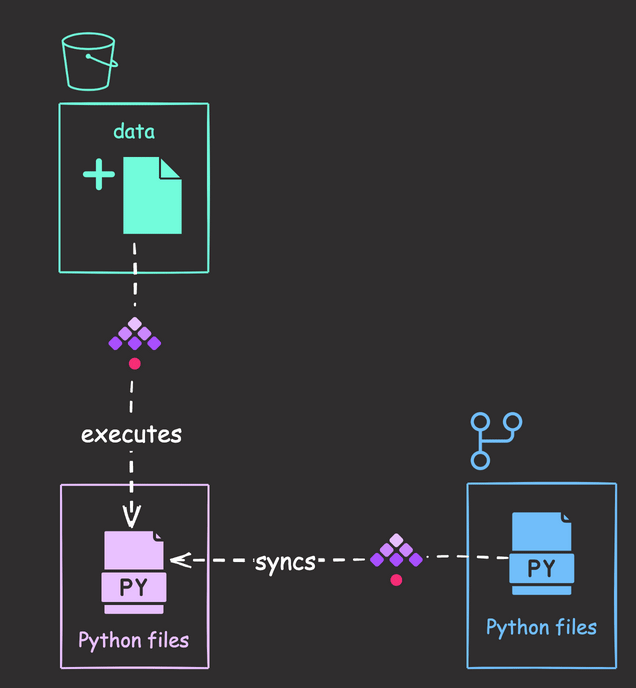
This workflow consists of two main components: Python scripts and orchestration.
Orchestration
- Python scripts and flows are stored in Git, with changes synced to Kestra on a schedule.
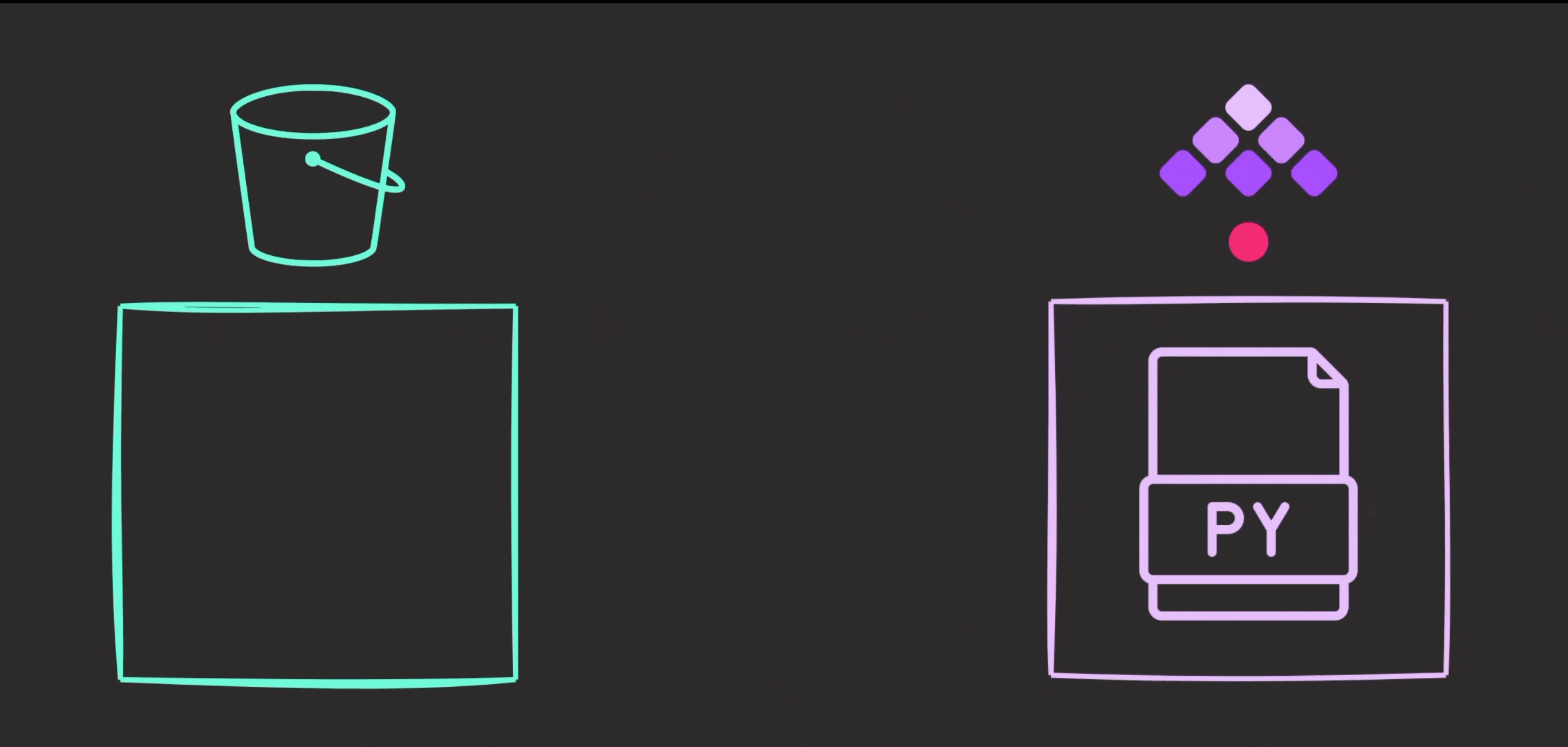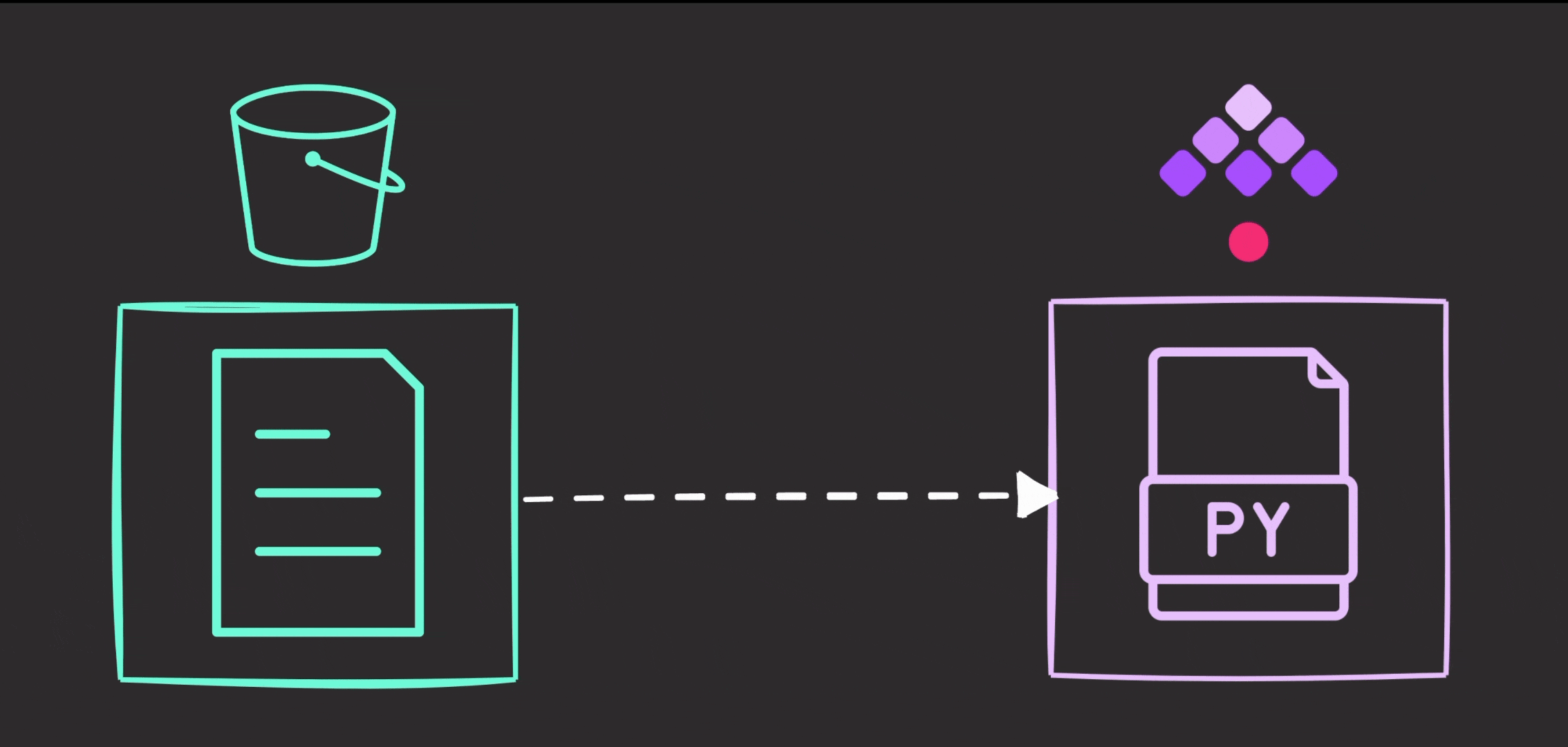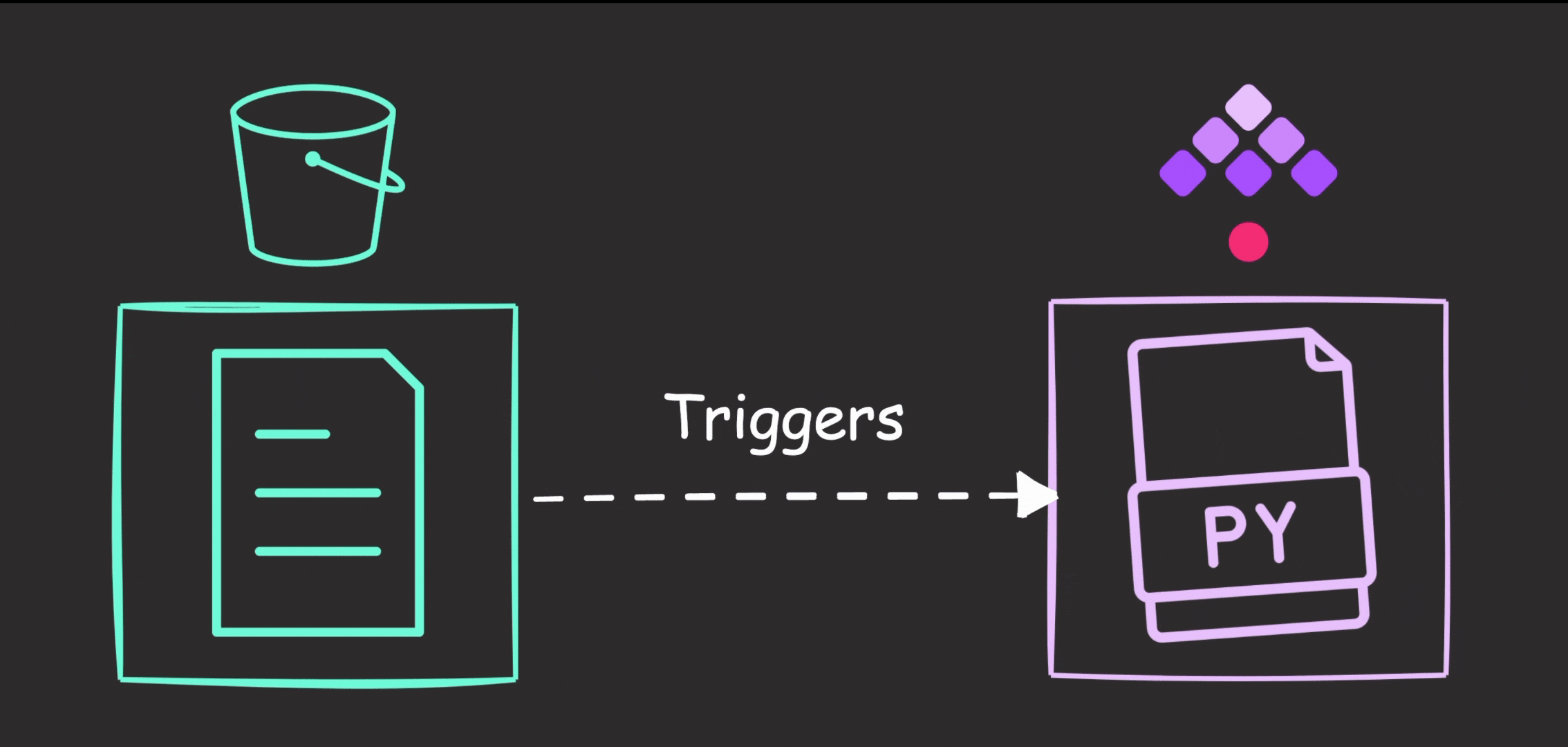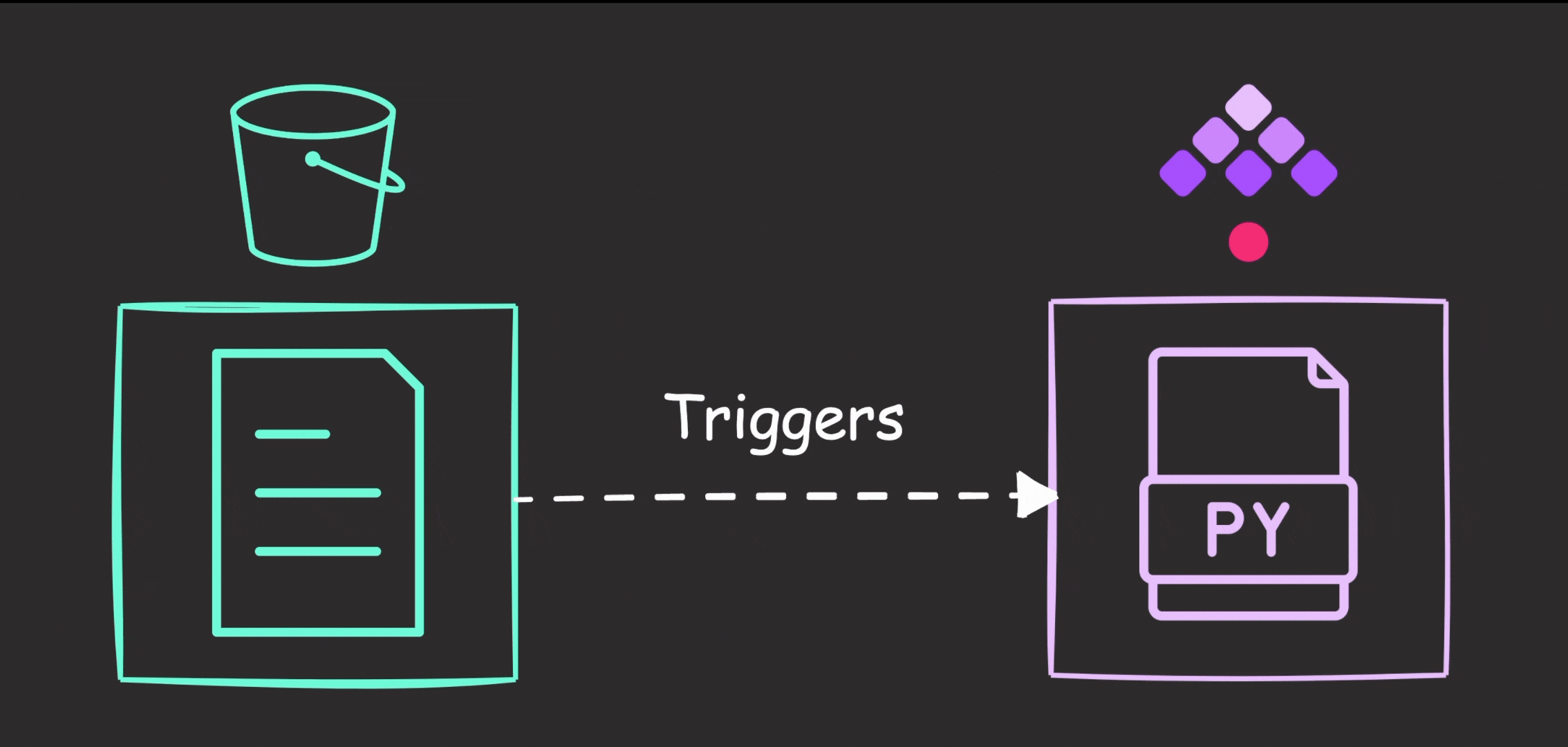
- When a new file appears in the “new” prefix of the S3 bucket, Kestra triggers an execution of a series of Python scripts.
Python Scripts
- download_files_from_s3.py: Download all files from the “old” prefix in the bucket.
- merge_data.py: Merge the downloaded files.
- process.py: Process the merged data.
- train.py: Train the model using the processed data.
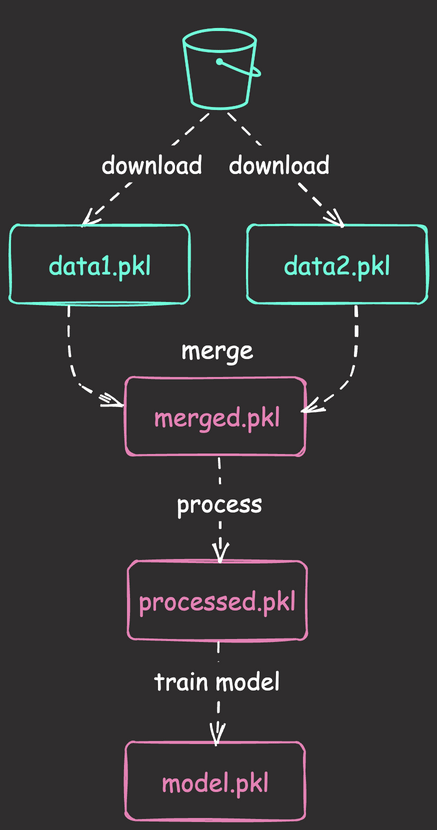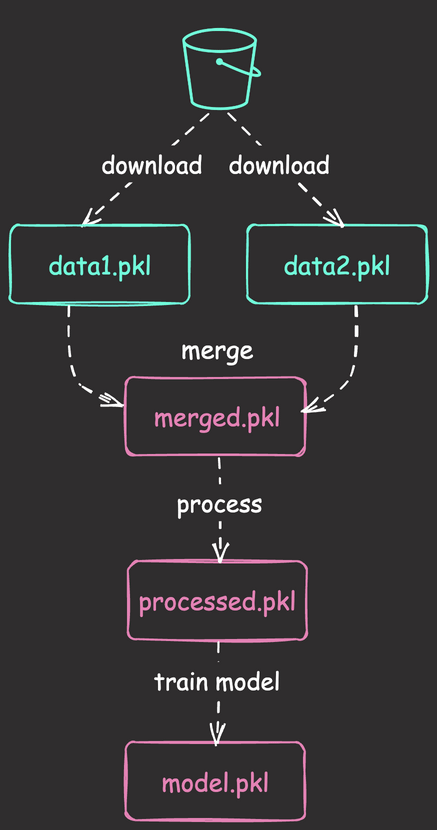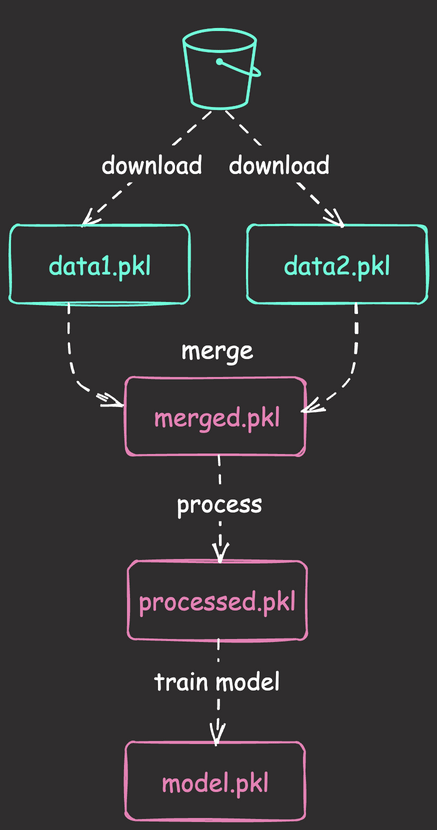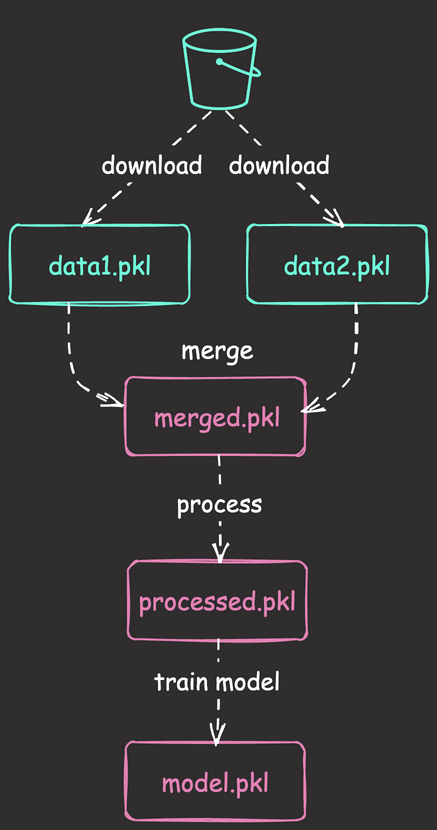
As we will execute the code downloaded from Git within Kestra, make sure to commit these Python scripts to the repository.
git add .
git commit -m 'add python scripts'
git push origin mainOrchestration
Start Kestra
Download the Docker Compose file by executing the following command:
curl -o docker-compose.yml \
https://raw.githubusercontent.com/kestra-io/kestra/develop/docker-compose.ymlEnsure that Docker is running. Then, start the Kestra server with the following command:
docker-compose up -dAccess the UI by opening the URL http://localhost:8080 in your browser.
Sync from Git
Since the Python scripts are in GitHub, we will use Git Sync to update the code from GitHub to Kestra every minute. To set this up, create a file named “sync_from_git.yml” under the “_flows” directory.
.
├── _flows/
│ └── sync_from_git.yml
└── src/
├── download_files_from_s3.py
├── helpers.py
├── merge_data.py
├── process.py
└── train.pyIf you are using VSCode, you can use the Kestra plugin to enable flow autocompletion and validation in .yaml files.

Below is the implementation of the flow to synchronize code from Git:
id: sync_from_git
namespace: dev
tasks:
- id: git
type: io.kestra.plugin.git.Sync
url: https://github.com/khuyentran1401/mlops-kestra-workflow
branch: main
username: "{{secret('GITHUB_USERNAME')}}"
password: "{{secret('GITHUB_PASSWORD')}}"
dryRun: false # if true, you'll see what files will be added, modified
# or deleted based on the Git version without overwriting the files yet
triggers:
- id: schedule
type: io.kestra.core.models.triggers.types.Schedule
cron: "*/1 * * * *" # every minuteA username and password are necessary only if the GitHub repository is private. To pass these secrets to Kestra, place them in the “.env” file:
# .env
GITHUB_USERNAME=mygithubusername
GITHUB_PASSWORD=mygithubtoken
AWS_ACCESS_KEY_ID=myawsaccesskey
AWS_SECRET_ACCESS_KEY=myawssecretaccesskey
# ! This line should be emptyNext, encode these secrets using the following bash script:
while IFS='=' read -r key value; do
echo "SECRET_$key=$(echo -n "$value" | base64)";
done < .env > .env_encodedExecuting this script generates a “.env_encoded” file containing encoded secrets:
# .env_encoded
SECRET_GITHUB_USERNAME=bXlnaXRodWJ1c2VybmFtZQ==
SECRET_GITHUB_PASSWORD=bXlnaXRodWJ0b2tlbg==
SECRET_AWS_ACCESS_KEY_ID=bXlhd3NhY2Nlc3NrZXk=
SECRET_AWS_SECRET_ACCESS_KEY=bXlhd3NzZWNyZXRhY2Nlc3NrZXk=Include the encoded environment file in your Docker Compose file for Kestra to access the environment variables:
# docker-compose.yml
kestra:
image: kestra/kestra:latest-full
env_file:
- .env_encodedEnsure to exclude the environment files in the “.gitignore” file:
# .gitignore
.env
.env_encodedLastly, commit both the new flow and the Docker Compose file to Git:
git add _flows/sync_from_git.yml docker-compose.yml
git commit -m 'add Git Sync'
git push origin mainNow, with the sync_from_git flow set to run every minute, you can conveniently access and trigger the execution of Python scripts directly from the Kestra UI.
Orchestration
We’ll create a flow triggered when a new file is added to the “new” prefix within the “winequality-red” bucket.
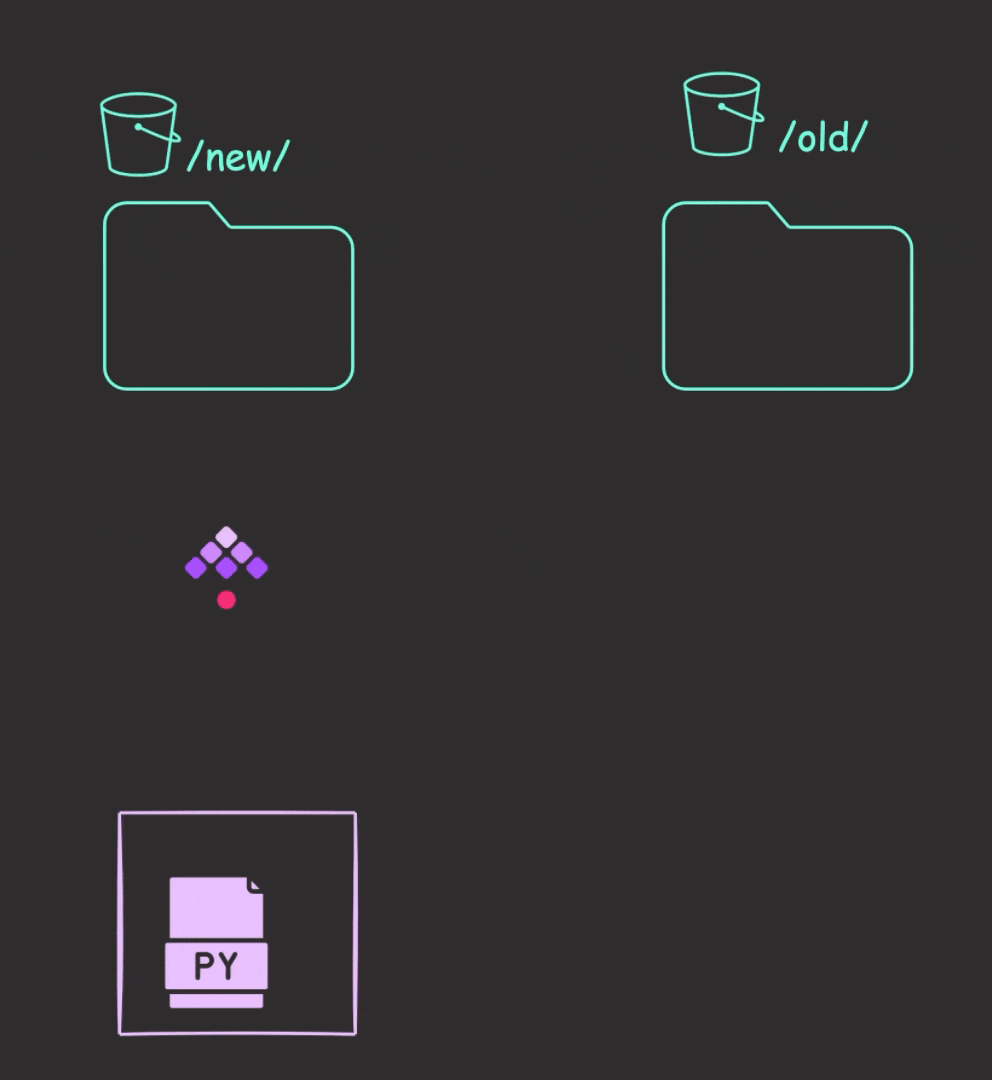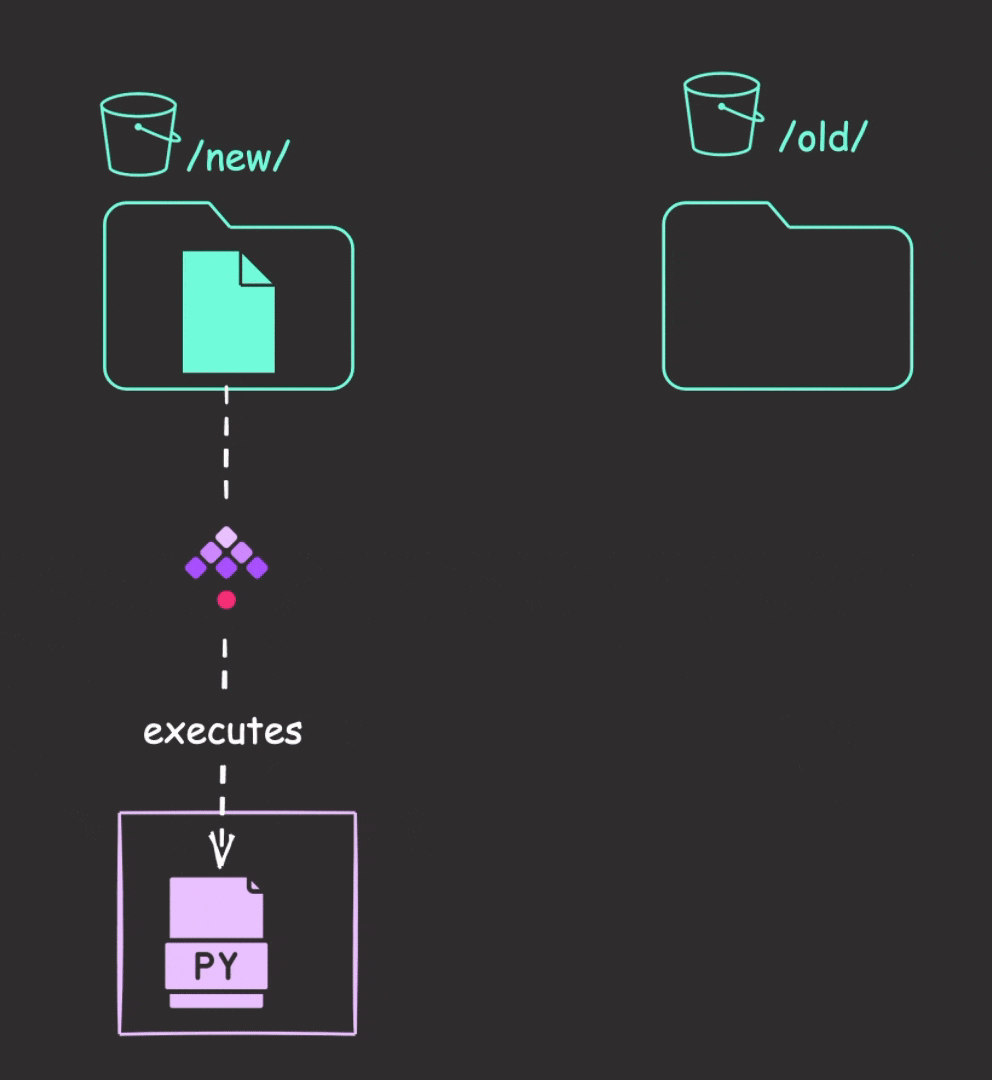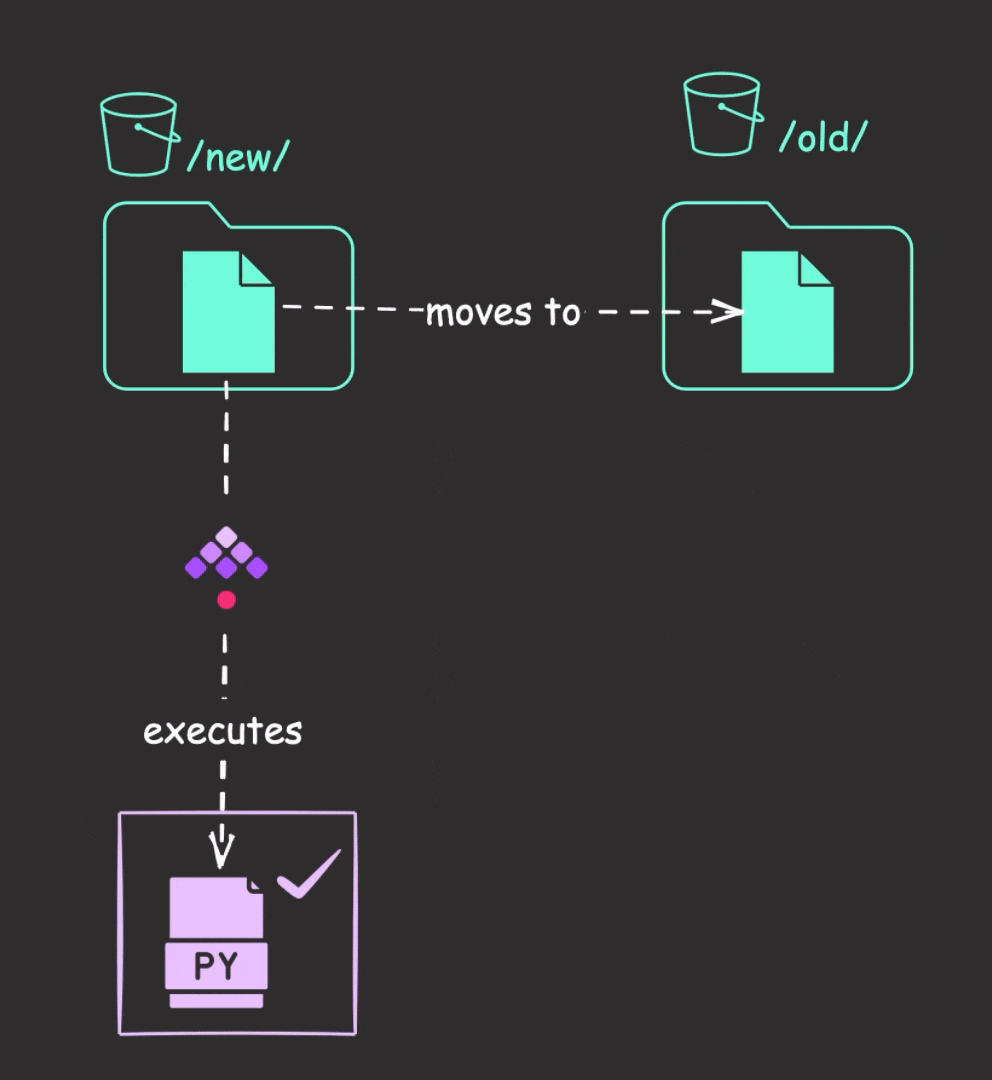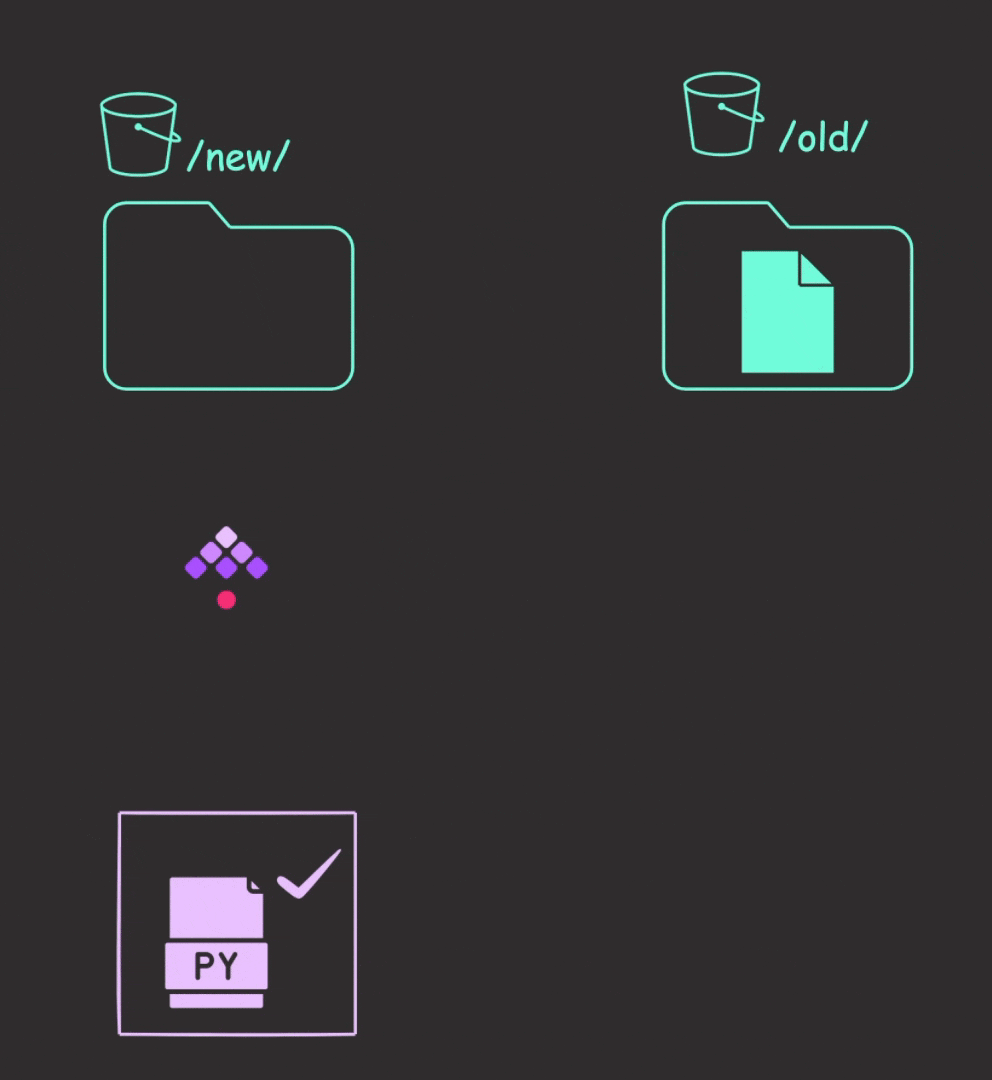
Upon detecting a new file, Kestra will download it to internal storage and execute the Python files. Finally, it moves the file from the “new” prefix to the “old” prefix in the bucket to avoid duplicate detection during subsequent polls.
id: run_ml_pipeline
namespace: dev
tasks:
- id: run_python_commands
type: io.kestra.plugin.scripts.python.Commands
namespaceFiles:
enabled: true
env:
AWS_ACCESS_KEY_ID: "{{secret('AWS_ACCESS_KEY_ID')}}"
AWS_SECRET_ACCESS_KEY: "{{secret('AWS_SECRET_ACCESS_KEY')}}"
docker:
image: ghcr.io/kestra-io/pydata:latest
beforeCommands:
- pip install -r requirements.txt
commands:
- python src/download_files_from_s3.py
- python src/merge_data.py
- python src/process.py
- python src/train.py
outputFiles:
- "*.pkl"
triggers:
- id: watch
type: io.kestra.plugin.aws.s3.Trigger
interval: PT1S
accessKeyId: "{{secret('AWS_ACCESS_KEY_ID')}}"
secretKeyId: "{{secret('AWS_SECRET_ACCESS_KEY')}}"
region: us-east-2
bucket: winequality-red
prefix: new
action: MOVE
moveTo:
bucket: winequality-red
key: oldThe run_python_commands task uses:
namespaceFilesto access all files in your local project, synchronized with your Git repository.envto retrieve environment variables.dockerto execute the script within the docker containerghcr.io/kestra-io/pydata:latest.beforeCommandsto install requirements from the “requirements.txt” file prior to executing commands.commandsto sequentially run a list of commands.outputFilesto send all pickle files from local file system to Kestra’s internal storage.
Finally, add the upload task to upload the model’s pickle file to S3.

id: run_ml_pipeline
namespace: dev
tasks:
- id: run_python_commands
type: io.kestra.plugin.scripts.python.Commands
namespaceFiles:
enabled: true
env:
AWS_ACCESS_KEY_ID: "{{secret('AWS_ACCESS_KEY_ID')}}"
AWS_SECRET_ACCESS_KEY: "{{secret('AWS_SECRET_ACCESS_KEY')}}"
docker:
image: ghcr.io/kestra-io/pydata:latest
beforeCommands:
- pip install -r requirements.txt
commands:
- python src/download_files_from_s3.py
- python src/merge_data.py
- python src/process.py
- python src/train.py model_path=model/model.pkl
outputFiles:
- "*.pkl"
# ------------------------- ADD THIS ------------------------- #
- id: upload
type: io.kestra.plugin.aws.s3.Upload
accessKeyId: "{{secret('AWS_ACCESS_KEY_ID')}}"
secretKeyId: "{{secret('AWS_SECRET_ACCESS_KEY')}}"
region: us-east-2
from: '{{outputs.run_python_commands.outputFiles["model/model.pkl"]}}'
bucket: winequality-red
key: model.pkl
# ------------------------------------------------------------ #
triggers:
...That’s it! Name this flow “run_ml_pipeline.yml” and commit it to Git.
git add run_ml_pipeline.yml
git commit -m 'add run_ml_pipeline'
git push origin mainTrigger the Flow
To initiate the flow, simply add a new file to the “new” prefix within the “winequality-red” bucket on S3.
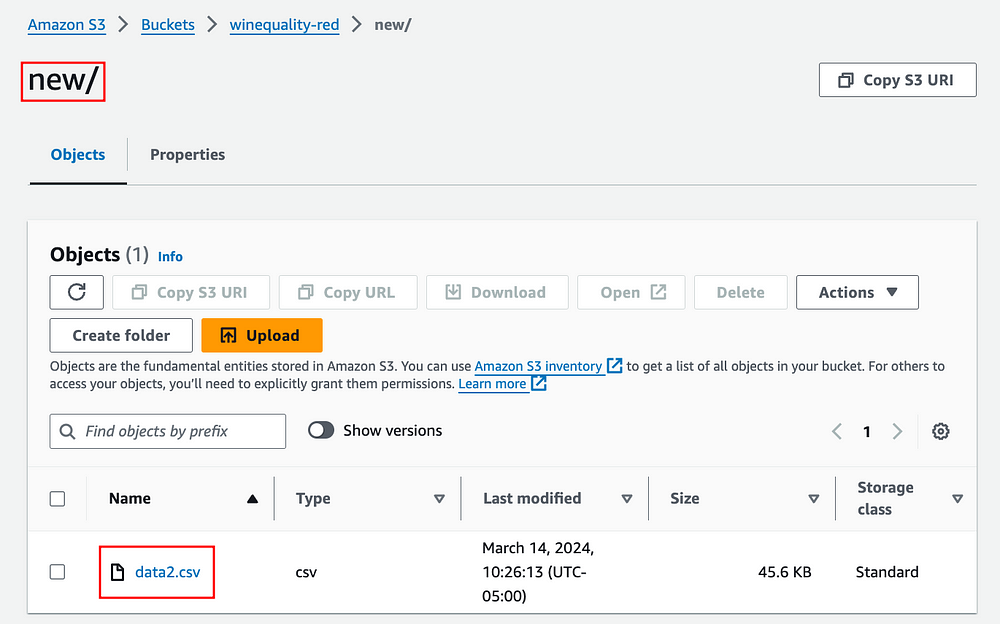
This action will trigger the run_ml_pipeline flow, initiating the download of data from the “old” prefix, merging all files, processing the data, and training the model.


Once the workflow completes execution, the “model.pkl” file is uploaded to S3.

Conclusion
This article shows how to use Kestra to automate the execution of Python scripts for data science tasks whenever a new file is added to S3. If you are looking for ways to automate your machine learning pipeline, give this solution a try.


2 thoughts on “Setting Up Automated Model Training Workflows with AWS S3”
Thanks for the article. Can you please share where is Kestra hosted?
In this article, I hosted it in Docker. However, you can also host it kestra anywhere with standalone Java binary, K8s cluster (with Helm). Check out this guide for more info.