
Motivation
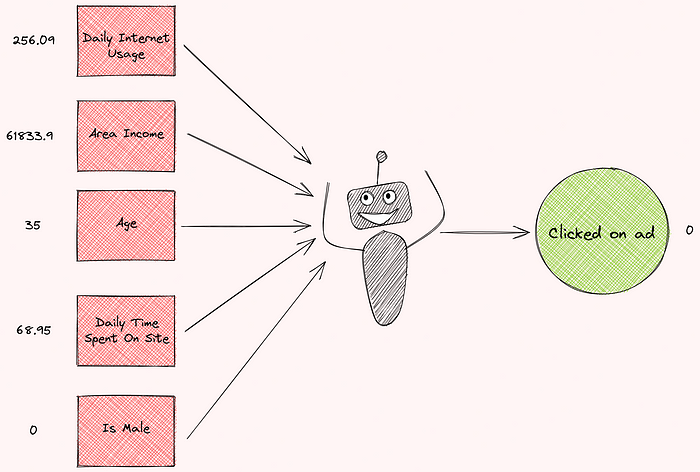
Imagine you are trying to train a machine learning model to predict whether a specific person will click on an ad. After receiving some data about that person, the model predicts that they will not click on the ad.
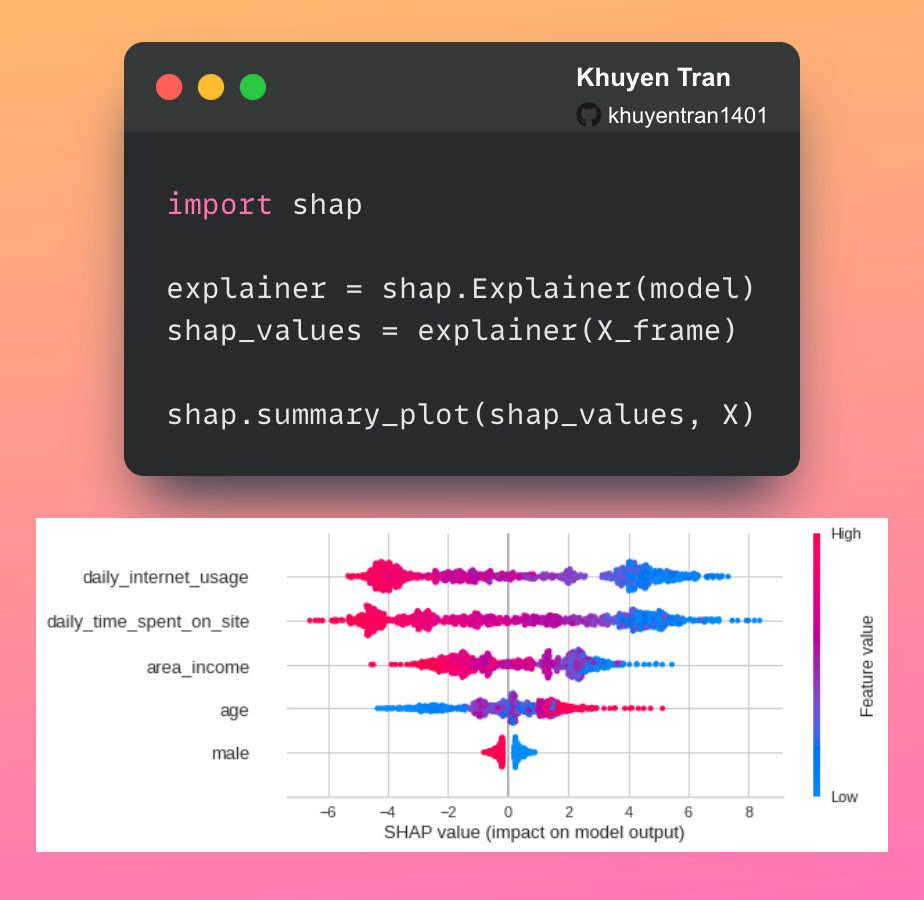
But what factors led to this prediction? How much does each feature contribute to the prediction? Wouldn’t it be nice if you can see a plot indicating how much each feature contributes to the prediction like below?
That is when Shapley value comes in handy.
What is Shapley Value?
The Shapley value is a method used in game theory that involves fairly distributing both gains and costs to actors working in a coalition.
Since each actor contributes differently to the coalition, the Shapley value makes sure that each actor gets a fair share depending on how much they contribute.

A Simple Example
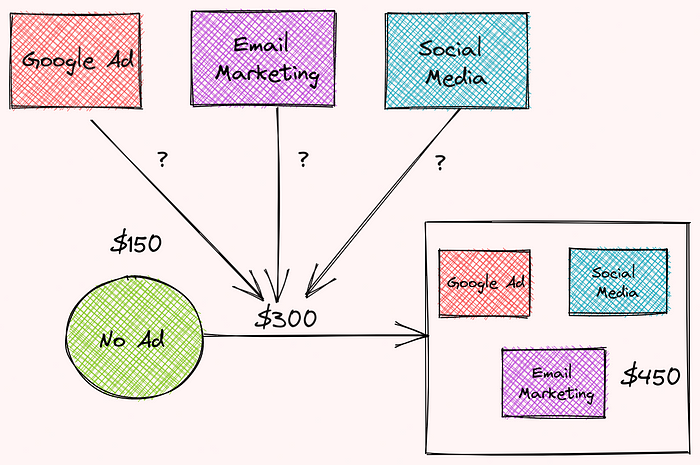
Shapley value is used for a wide range of problems that question the contribution of each worker/feature in a group. To understand how Shapley value works, let’s imagine that your company has just done A/B testing, where they test different combinations of advertisement strategies.
The revenues for each strategy in a specific month are:
- no ad: $150
- social media: $300
- Google advertisement: $200
- email marketing: $350
- social media and Google advertisement $320
- social media and email marketing: $400
- Google advertisement and email marketing: $350
- email marketing, Google advertisement, and social media: $450

The difference in revenues between using three ads and using no ads is $300. How much does each ad contribute to this difference?
We can figure that out by calculating the Shapley value for each type of advertisement. This article provides an excellent way to calculate the Shap value. I will summarize it here.
We start by calculating the total contribution of Google advertisements to the company’s revenue. The total contribution of Google advertisement could be calculated by the formula:

Let’s find the marginal contribution of Google advertisement and its weight.
Find Marginal Contribution of Google Advertisement
First, we will find the marginal contribution of Google advertisement to the following groups:
- no advertisement
- Google advertisement + social media
- Google advertisement + email marketing
- Google advertisement + email marketing + social media
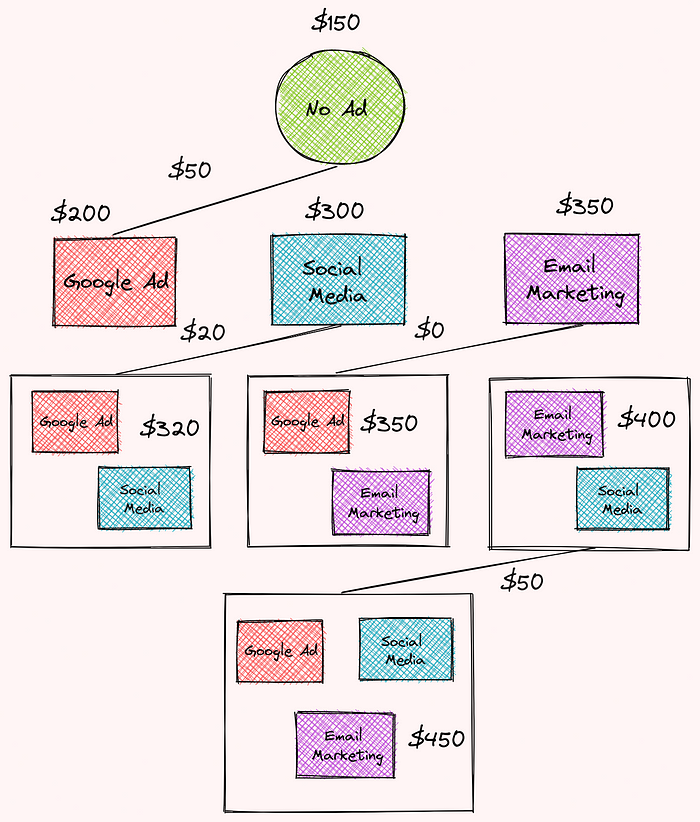
The marginal contribution of Google advertisement to no advertisement is:

The marginal contribution of Google advertisement to the Google advertisement and social media group is:
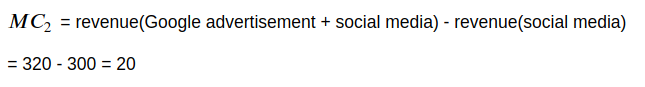
The marginal contribution of Google advertisement to the Google advertisement and email marketing group is:

The marginal contribution of Google advertisement to the Google advertisement, email marketing, and social media group is:

Find Weights
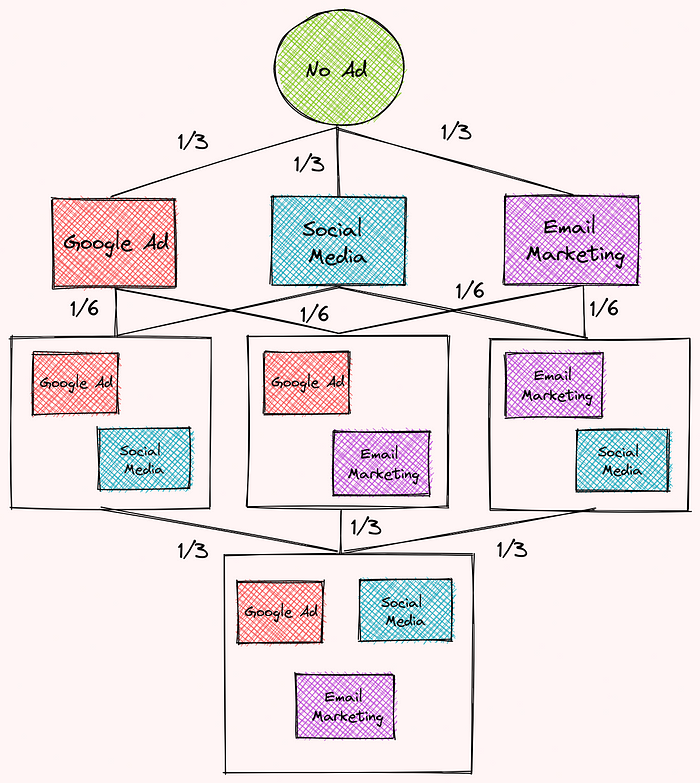
To find the weights, we will organize the combinations of different advertisement strategies into multiple levels like below. Each level corresponds to the number of advertisement strategies in each combination.
Then we will assign weights based on the number of edges at each level. We saw that:
- The first level contains 3 edges so the weight of each edge will be 1/3
- The second level contains 6 edges so the weight of each edge will be 1/6
- The third level contains 3 edges so the weight of each edge will be 1/3
Find the Total Contribution of Google Advertisement
Now we are ready to find Google advertisement’s total contribution based on the weights and marginal contribution we found earlier!
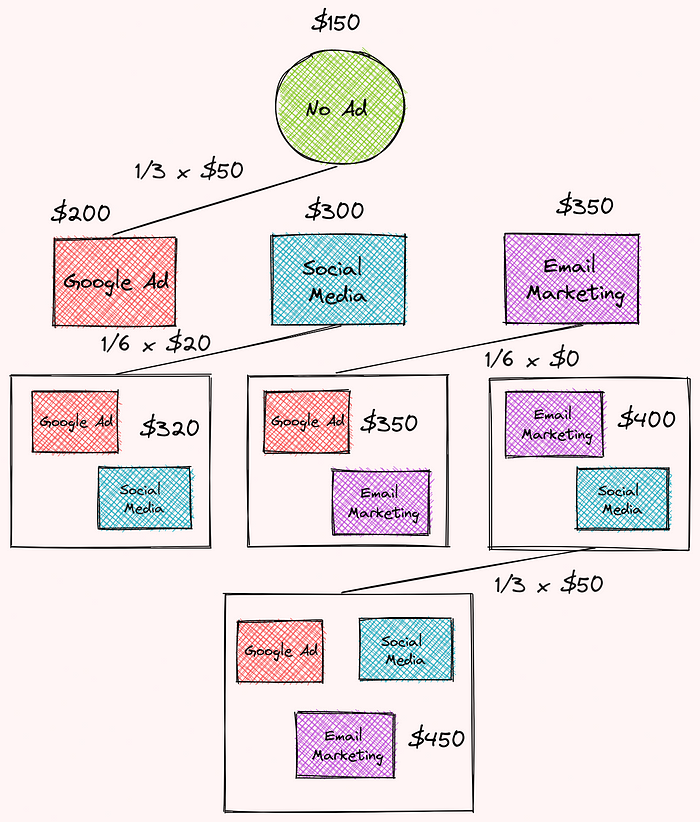
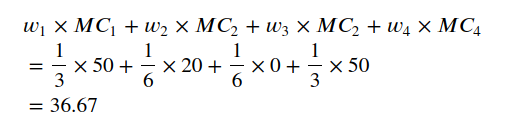
Cool! So Google advertisement contributes $36.67 to the total difference in revenues between using 3 advertisement strategies and using no advertisement. 36.67 is the Shapey value for Google advertisement.

Repeat the steps above for two other advertisement strategies, we can see that:
- Email marketing contributes $151.67
- Social media contributes $111.67
- Google advertisement contributes $36.67
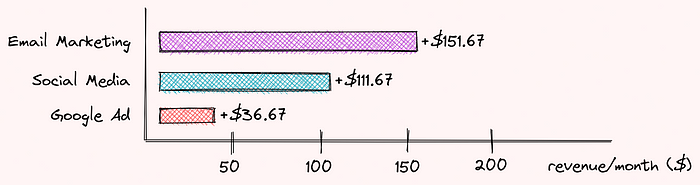
Together they contribute $300 to the difference between using 3 different types of advertisement and using no advertisement! Pretty cool, isn’t it?
Now that we understand the Shapley value, let’s see how we can use it to interpret a machine learning model.
SHAP — Explain Any Machine Learning Models in Python
SHAP is a Python library that uses Shapley values to explain the output of any machine learning model.
To install SHAP, type:
pip install shapFeel free to play and fork the source code here:
Train a Model
To understand how SHAP works, we will experiment with an advertising dataset:
import pandas as pd
data = pd.read_csv("advertising.csv")
data.columns = data.columns.map(lambda row: "_".join(row.lower().split(" ")))
data| | daily_time_spent_on_site | age | area_income | daily_internet_usage | ad_topic_line | city | male | country | timestamp | clicked_on_ad |
|---:|---------------------------:|------:|--------------:|-----------------------:|:--------------------------------------|:-----------------|-------:|:-----------|:--------------------|----------------:|
| 0 | 68.95 | 35 | 61833.9 | 256.09 | Cloned 5thgeneration orchestration | Wrightburgh | 0 | Tunisia | 2016-03-27 00:53:11 | 0 |
| 1 | 80.23 | 31 | 68441.9 | 193.77 | Monitored national standardization | West Jodi | 1 | Nauru | 2016-04-04 01:39:02 | 0 |
| 2 | 69.47 | 26 | 59785.9 | 236.5 | Organic bottom-line service-desk | Davidton | 0 | San Marino | 2016-03-13 20:35:42 | 0 |
| 3 | 74.15 | 29 | 54806.2 | 245.89 | Triple-buffered reciprocal time-frame | West Terrifurt | 1 | Italy | 2016-01-10 02:31:19 | 0 |
| 4 | 68.37 | 35 | 73890 | 225.58 | Robust logistical utilization | South Manuel | 0 | Iceland | 2016-06-03 03:36:18 | 0 |
| 5 | 59.99 | 23 | 59761.6 | 226.74 | Sharable client-driven software | Jamieberg | 1 | Norway | 2016-05-19 14:30:17 | 0 |
| 6 | 88.91 | 33 | 53852.8 | 208.36 | Enhanced dedicated support | Brandonstad | 0 | Myanmar | 2016-01-28 20:59:32 | 0 |
| 7 | 66 | 48 | 24593.3 | 131.76 | Reactive local challenge | Port Jefferybury | 1 | Australia | 2016-03-07 01:40:15 | 1 |
| 8 | 74.53 | 30 | 68862 | 221.51 | Configurable coherent function | West Colin | 1 | Grenada | 2016-04-18 09:33:42 | 0 |
| 9 | 69.88 | 20 | 55642.3 | 183.82 | Mandatory homogeneous architecture | Ramirezton | 1 | Ghana | 2016-07-11 01:42:51 | 0 |Or goal is to build a machine learning model to predict whether a user clicked on an ad based on some information about that person.
We will use Patsy to turn the DataFrame into an array of features and an array of target values:
from patsy import dmatrices
y, X = dmatrices(
"clicked_on_ad ~ daily_time_spent_on_site + age + area_income + daily_internet_usage + male -1",
data=data,
)
X_frame = pd.DataFrame(data=X, columns=X.design_info.column_names)Split the data into train and test sets:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)Next, we will use XGBoost to build a model and make predictions:
import xgboost
model = xgboost.XGBClassifier().fit(X_train, y_train)
predict = model.predict(X_test)To see how well the model performs, we will use the F1 score:
from sklearn.metrics import f1_score
f1 = f1_score(y_test, predict)
f10.9619047619047619Pretty good!
Interpret the Model
The model did a good job of predicting whether a user clicked an ad. But how did it come up with such predictions? How much did each feature contribute to the difference between the final prediction and the average prediction?
Note that this problem is very similar to the problem we addressed at the beginning of the article.
That is why finding the Shapley value of each feature can help us determine their contribution. The steps to get the importance of the feature i, where i is the index of features, is similar to before:
- Get all subsets that don’t contain the feature
i - Find the marginal contribution of the feature
ito each of these subsets - Aggregate all marginal contributions to compute the contributions of the feature
i
To find the Shapley values using SHAP, simply insert your trained model to shap.Explainer :
import shap
explainer = shap.Explainer(model)
shap_values = explainer(X_frame)SHAP Waterfall Plot
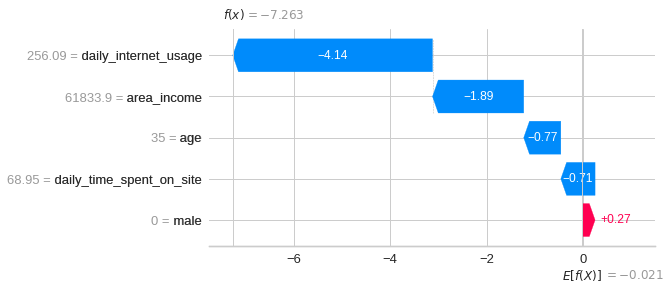
Visualize the first prediction’s explanation:
shap.plots.waterfall(shap_values[0])Aha! Now we know the contribution of each feature to the first prediction. Explanations for the graph above:

- The blue bar shows how much a particular feature decreases the value of the prediction.
- The red bar shows how much a particular feature increases the value of the prediction.
- Negative values imply probabilities of less than 0.5 that the person clicked the ad
For each of these subsets, SHAP doesn’t remove a feature and then retrain the model but replaces that feature with the average value of that feature, then generates the predictions.
We should expect the total contribution to be equal to the difference between the prediction and the mean prediction. Let’s check that:
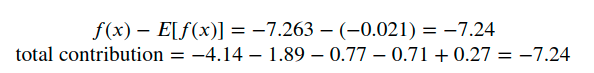
Cool! They’re equal.
Visualize the second prediction’s explanation:
shap.plots.waterfall(shap_values[1])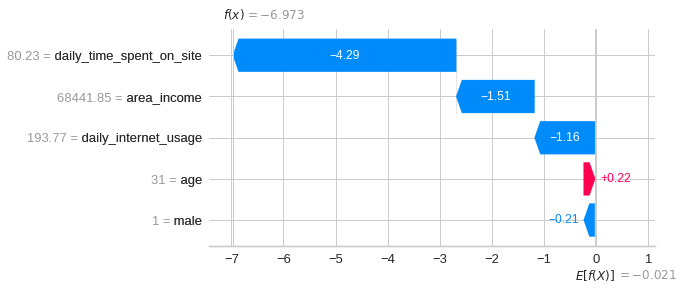
SHAP Summary Plot
Instead of looking at each individual instance, we can visualize the overall impact of these features across multiple instances using SHAP summary plot:
shap.summary_plot(shap_values, X)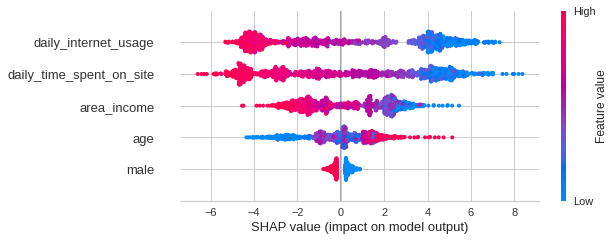
The SHAP summary plot tells us the most important features and their range of effects over the dataset.
From the plot above, we can gain some interesting insights into the model’s predictions:
- The daily internet usage of a user has the strongest effect on whether that user clicked on an ad.
- As the daily internet usage increases, a user is less likely to click on an ad.
- As the daily time spent on the site increases, a user is less likely to click on an ad.
- As the area income increases, a user is less likely to click on an ad.
- As the age increases, a user is more likely to click on an ad.
- If a user is a male, that user is less likely to click on an ad.
SHAP Bar Plot
We can also get a global feature importance plot using the SHAP bar plot.
shap.plots.bar(shap_values)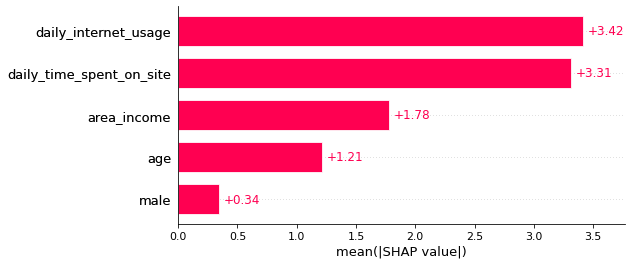
SHAP Dependence Scatter Plot
We can observe the effect of a single feature on all predictions made by the model using the SHAP dependence scatter plot.
Daily Internet Usage
Scatter plot of the daily internet usage feature:
shap.plots.scatter(shap_values[:, "daily_internet_usage"])
From the plot above, we can see that as the daily internet usage increases, the SHAP value for the daily internet usage decreases. This confirms what we saw in the earlier plot.
We can also observe the interaction between the daily internet usage feature with other features in the same plot by adding color=shap_values .
The scatter plot will attempt to pick out the feature column with the strongest interaction with daily internet usage, which is daily time spent on site.
shap.plots.scatter(shap_values[:, "daily_internet_usage"], color=shap_values)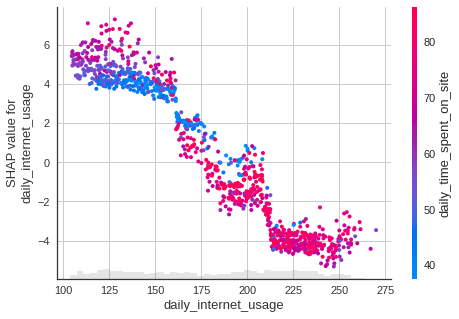
Cool! From the plot above, we can see that a person who uses the internet for 150 minutes per day and spends a small amount of time on the website per day is more likely to click the ad.
Let’s look at the scatter plots of some other features:
Daily Time Spent on Site
shap.plots.scatter(shap_values[:, "daily_time_spent_on_site"], color=shap_values)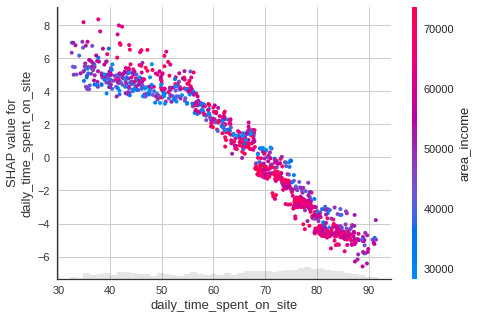
Area Income
shap.plots.scatter(shap_values[:, "area_income"], color=shap_values)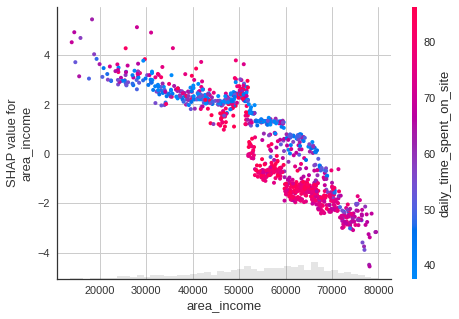
Age
shap.plots.scatter(shap_values[:, "age"], color=shap_values)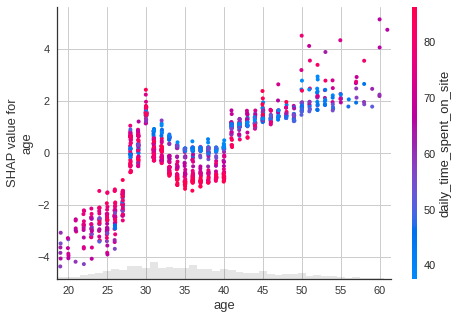
Gender
shap.plots.scatter(shap_values[:, "male"], color=shap_values)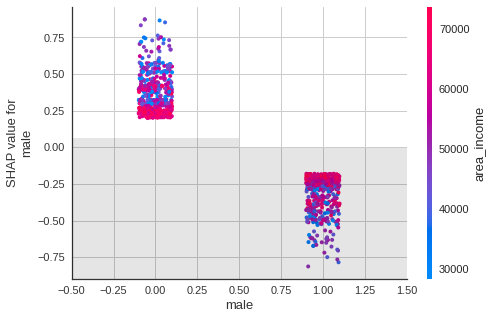
SHAP Interaction Plot
You can also observe the matrix of interactions between features with the SHAP interaction value summary plot. In this plot, the main effects are on the diagonal and the interaction effects are off the diagonal.
# Get interaction values
shap_interaction_values = explainer.shap_interaction_values(X)
# Summarize the interaction values
shap.summary_plot(shap_interaction_values, X_frame)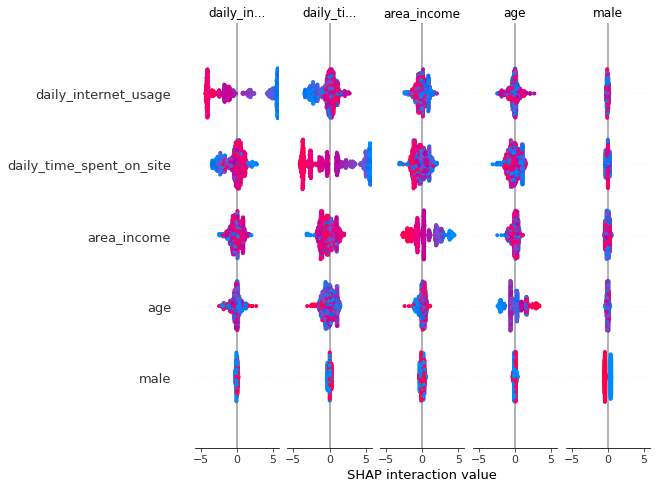
Pretty cool!
Conclusion
Congratulations! You have just learned about Shapey value and how to use it to interpret a machine learning model. I hope this article will give you the essential knowledge to interpret your own machine learning model using Python.
I recommend checking out SHAP’s documentation to learn more about other applications of SHAP.

3 thoughts on “Explain Any Machine Learning Model in Python with SHAP”
Absolutely a great article. Wasn’t aware of Shap. Thanks for posting in such great detail and with well chosen examples. Will incorporate in my own applications. Should be very useful for reducing the dimensionality of the problem, carrying unnecessary baggage in the ML model
Hi Ravi, thank you! I’m glad you found the article useful and will actually use Shap.
That’s a great example of model explainability. It is mentioned that the base value is the average of the prediction. The question is which set does the waterfall plot consider to calculate the prediction for the base value? the average of X_train pred or X_test pred or what?