
What is SkillNER?
SkillNER is an open-source Python library built on top of spaCy that automates the extraction of skills from unstructured text. It uses a curated database of over 60,000 skills combined with spaCy’s PhraseMatcher to identify both hard skills (like Python, SQL, TensorFlow) and soft skills (like communication, leadership) in documents. Unlike generic named entity recognition tools, SkillNER is purpose-built for skill taxonomy, making it especially valuable for HR tech, recruiting platforms, and workforce analytics applications where accurate skill tagging is critical.
Extracting skills from job postings, resumes, or other unstructured text can be time-consuming if done manually. SkillNER automates this process, making it faster and more efficient.
This tool can be useful for:
- Recruiters to automate skill extraction for faster candidate screening.
- Data scientists to extract structured data from unstructured job-related text.
Here’s a quick example:
import spacy
from spacy.matcher import PhraseMatcher
from skillNer.general_params import SKILL_DB
from skillNer.skill_extractor_class import SkillExtractor
# Load the spaCy model
nlp = spacy.load("en_core_web_lg")
# Initialize the SkillExtractor
skill_extractor = SkillExtractor(nlp, SKILL_DB, PhraseMatcher)
# Sample job description
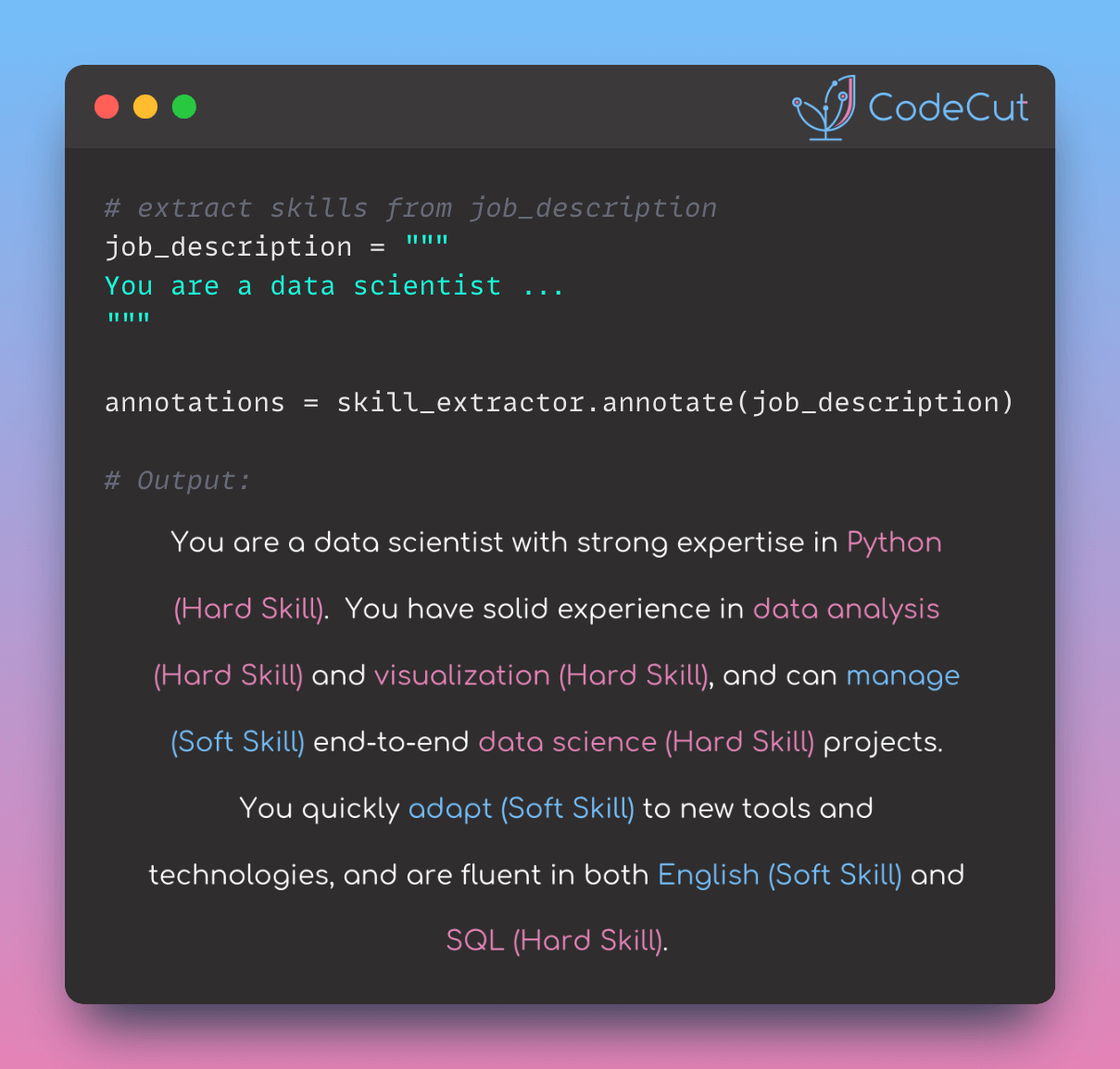
job_description = """
You are a data scientist with strong expertise in Python. You have solid experience in
data analysis and visualization, and can manage end-to-end data science projects.
You quickly adapt to new tools and technologies, and are fluent in both English and SQL.
"""
# Extract skills from the job description
annotations = skill_extractor.annotate(job_description)
annotationsOutput:
{'text': 'you are a data scientist with strong expertise in python you have solid experience in data analysis and visualization and can manage end to end data science projects you quickly adapt to new tools and technologies and are fluent in both english and sql',
'results': {'full_matches': [{'skill_id': 'KS120GV6C72JMSZKMTD7',
'doc_node_value': 'data analysis',
'score': 1,
'doc_node_id': [15, 16]}],
'ngram_scored': [{'skill_id': 'KS125LS6N7WP4S6SFTCK',
'doc_node_id': [9],
'doc_node_value': 'python',
'type': 'fullUni',
'score': 1,
'len': 1},
{'skill_id': 'KS1282T6STD9RJZ677XL',
'doc_node_id': [18],
'doc_node_value': 'visualization',
'type': 'fullUni',
'score': 1,
'len': 1},
{'skill_id': 'KS1218W78FGVPVP2KXPX',
'doc_node_id': [21],
'doc_node_value': 'manage',
'type': 'lowSurf',
'score': 0.63417345,
'len': 1},
{'skill_id': 'KS7LO8P3MXB93R3C9RWL',
'doc_node_id': [25, 26],
'doc_node_value': 'data science',
'type': 'lowSurf',
'score': 2,
'len': 2},
{'skill_id': 'KS120626HMWCXJWJC7VK',
'doc_node_id': [30],
'doc_node_value': 'adapt',
'type': 'lowSurf',
'score': 0.503605,
'len': 1},
{'skill_id': 'KS123K75YYK8VGH90NCS',
'doc_node_id': [41],
'doc_node_value': 'english',
'type': 'lowSurf',
'score': 1,
'len': 1},
{'skill_id': 'KS440W865GC4VRBW6LJP',
'doc_node_id': [43],
'doc_node_value': 'sql',
'type': 'fullUni',
'score': 1,
'len': 1}]}}skill_extractor.describe(annotations)
Why It Beats Manual Parsing
Before tools like SkillNER, extracting skills from resumes meant writing brittle regex patterns or maintaining hand-curated keyword lists that fell apart the moment a candidate wrote “ML” instead of “machine learning.” SkillNER handles these variations automatically through its built-in skill database and fuzzy matching, reducing the engineering cost of building skill-aware applications from weeks to minutes. For teams processing hundreds of resumes daily, this is the difference between a functional recruiting pipeline and a bottleneck.
Conclusion
SkillNER turns skill extraction from a manual, error-prone task into a reliable automated step in your NLP pipeline. It’s a solid choice when you need fast, accurate skill tagging without training a custom NER model from scratch.
Read Next
Comparing NER approaches? Read our deep dive: langextract vs spaCy: AI-Powered vs Rule-Based Entity Extraction. Find the right entity extraction tool for your use case.