
To reduce the memory usage of a Pandas DataFrame, you can start by changing the data type of a column.
The current memory usage of the DataFrame can be understood by using the info() function.
from sklearn.datasets import load_iris
import pandas as pd
X, y = load_iris(as_frame=True, return_X_y=True)
df = pd.concat([X, pd.DataFrame(y, columns=["target"])], axis=1)
df.info()Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
4 target 150 non-null int64
dtypes: float64(4), int64(1)
memory usage: 6.0 KBUse Smaller Data Types
By default, Pandas uses float64 for floating-point numbers, which can be oversized for columns with smaller value ranges. Here are some alternatives:
- float16: Suitable for values between -32768 and 32767.
- float32: Suitable for integers between -2147483648 and 2147483647.
- float64: The default, suitable for a wide range of values.
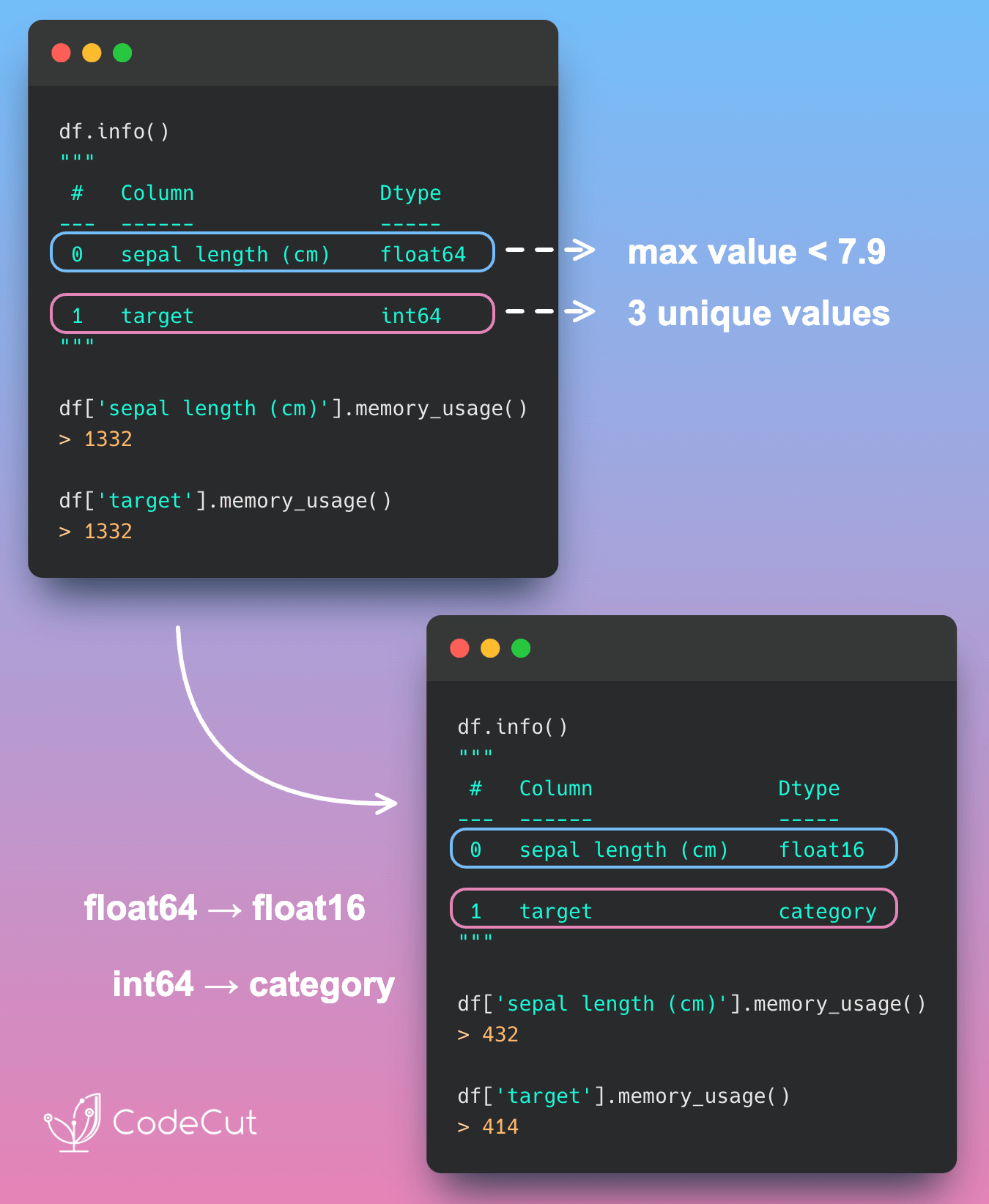
For example, if you know that the values in the “sepal length (cm)” column will never exceed 32767, you can use float16 to reduce memory usage.
df['sepal length (cm)'].max()Output:
7.9df['sepal length (cm)'].memory_usage()Output:
1332df["sepal length (cm)"] = df["sepal length (cm)"].astype("float16")
df['sepal length (cm)'].memory_usage()Output:
432Here, the memory usage of the “sepal length (cm)” column decreased from 1332 bytes to 432 bytes, a reduction of approximately 67.6%.
Convert to Category Columns
If you have a categorical variable with low cardinality, you can change its data type to category to reduce memory usage.
The “target” column has only 3 unique values, making it a good candidate for the category data type to save memory.
# View category
df['target'].nunique()Output:
3df['target'].memory_usage()Output:
1332df["target"] = df["target"].astype("category")
df['target'].memory_usage()Output:
414Here, the memory usage of the “target” column decreased from 1332 bytes to 414 bytes, a reduction of approximately 68.9%.
Apply Optimizations to All Columns
If we apply this reduction to the rest of the columns, the memory usage of the DataFrame decreased from 6.0 KB to 1.6 KB, a reduction of approximately 73.3%.
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].apply(lambda x: x.astype('float16'))
df.info()Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float16
1 sepal width (cm) 150 non-null float16
2 petal length (cm) 150 non-null float16
3 petal width (cm) 150 non-null float16
4 target 150 non-null category
dtypes: category(1), float16(4)
memory usage: 1.6 KB