The Problem with Traditional Approaches
Extracting structured information from a document often involves juggling multiple specialized libraries and APIs, including:
- Tesseract for Optical Character Recognition (OCR)
- OpenCV for image processing
- Transformers for entity extraction
This complexity can lead to significant development overhead, making it difficult to build reliable and efficient document processing pipelines.
# Traditional approach mixing multiple libraries
import pytesseract
import cv2
from transformers import pipeline
import re
def extract_invoice_data(image_path):
# OCR with Tesseract
image = cv2.imread(image_path)
text = pytesseract.image_to_string(image)
# Use regex to find invoice number
invoice_num = re.search(r'Invoice #: (\d+)', text)
# Use transformer for entity extraction
nlp = pipeline("ner")
entities = nlp(text)
# Complex post-processing logic
# ... more code to structure the data
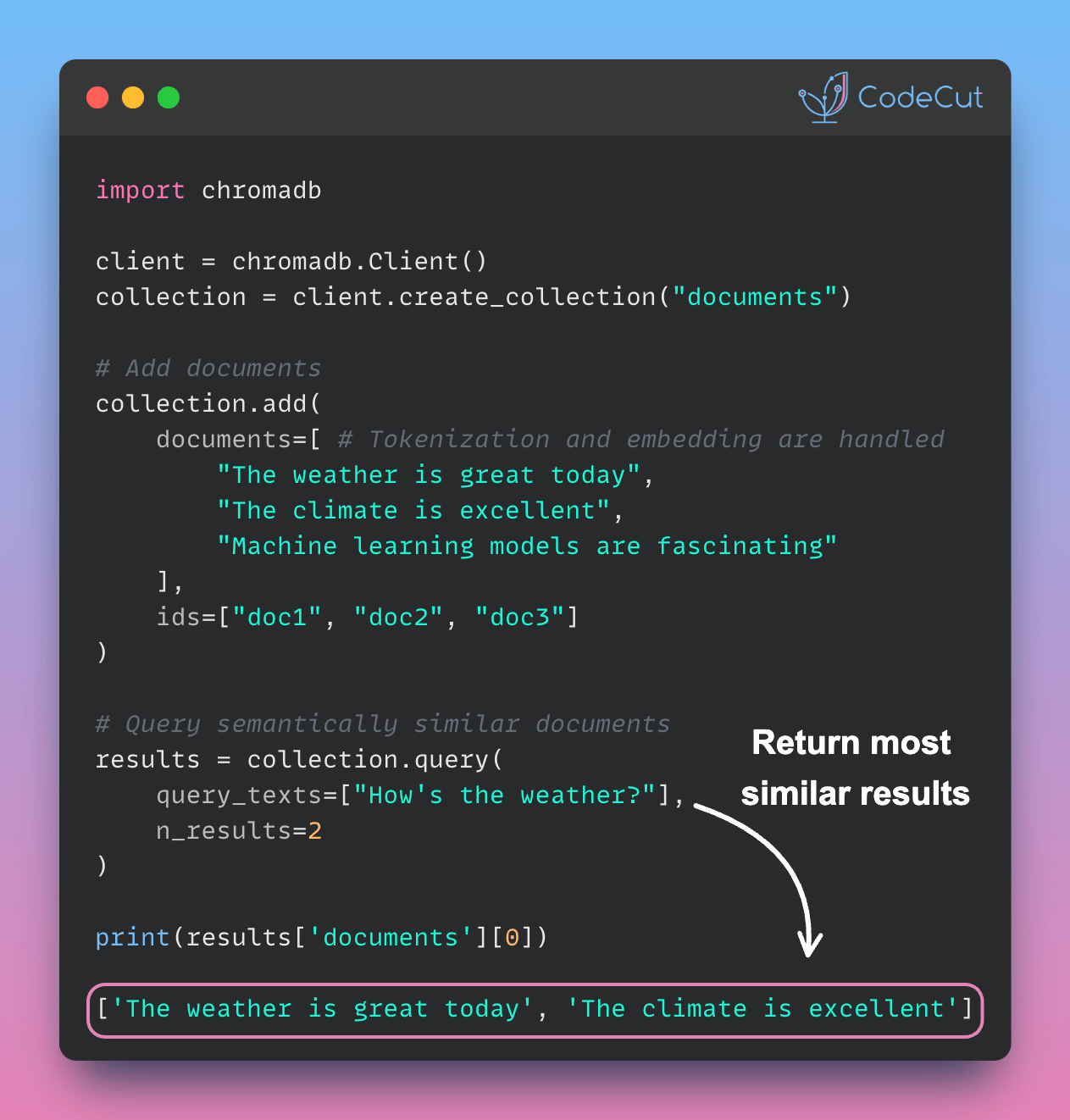
Introducing Sparrow
Sparrow is a unified API that handles various document types and extraction methods, making it easy to switch between different backends (local or cloud) and extraction models while maintaining a consistent output structure.
Examples
Bank Statement
Input document:

Query:
*Output:
{
"bank": "First Platypus Bank",
"address": "1234 Kings St., New York, NY 12123",
"account_holder": "Mary G. Orta",
"account_number": "1234567890123",
"statement_date": "3/1/2022",
"period_covered": "2/1/2022 - 3/1/2022",
"account_summary": {
"balance_on_march_1": "$25,032.23",
"total_money_in": "$10,234.23",
"total_money_out": "$10,532.51"
},
"transactions": [
{
"date": "02/01",
"description": "PGD EasyPay Debit",
"withdrawal": "203.24",
"deposit": "",
"balance": "22,098.23"
},
{
"date": "02/02",
"description": "AB&B Online Payment*****",
"withdrawal": "71.23",
"deposit": "",
"balance": "22,027.00"
},
{
"date": "02/04",
"description": "Check No. 2345",
"withdrawal": "",
"deposit": "450.00",
"balance": "22,477.00"
},
{
"date": "02/05",
"description": "Payroll Direct Dep 23422342 Giants",
"withdrawal": "",
"deposit": "2,534.65",
"balance": "25,011.65"
},
{
"date": "02/06",
"description": "Signature POS Debit - TJP",
"withdrawal": "84.50",
"deposit": "",
"balance": "24,927.15"
},
{
"date": "02/07",
"description": "Check No. 234",
"withdrawal": "1,400.00",
"deposit": "",
"balance": "23,527.15"
},
{
"date": "02/08",
"description": "Check No. 342",
"withdrawal": "",
"deposit": "25.00",
"balance": "23,552.15"
},
{
"date": "02/09",
"description": "FPB AutoPay***** Credit Card",
"withdrawal": "456.02",
"deposit": "",
"balance": "23,096.13"
},
{
"date": "02/08",
"description": "Check No. 123",
"withdrawal": "",
"deposit": "25.00",
"balance": "23,552.15"
},
{
"date": "02/09",
"description": "FPB AutoPay***** Credit Card",
"withdrawal": "156.02",
"deposit": "",
"balance": "23,096.13"
},
{
"date": "02/08",
"description": "Cash Deposit",
"withdrawal": "",
"deposit": "25.00",
"balance": "23,552.15"
}
],
"valid": "true"
}Bonds Table
Input document:

Query:
[{"instrument_name":"str", "valuation":0}]Output:
{
"data": [
{
"instrument_name": "UNITS BLACKROCK FIX INC DUB FDS PLC ISHS EUR INV GRD CP BD IDX/INST/E",
"valuation": 19049
},
{
"instrument_name": "UNITS ISHARES III PLC CORE EUR GOVT BOND UCITS ETF/EUR",
"valuation": 83488
},
{
"instrument_name": "UNITS ISHARES III PLC EUR CORP BOND 1-5YR UCITS ETF/EUR",
"valuation": 213030
},
{
"instrument_name": "UNIT ISHARES VI PLC/JP MORGAN USD E BOND EUR HED UCITS ETF DIST/HDGD/",
"valuation": 32774
},
{
"instrument_name": "UNITS XTRACKERS II SICAV/EUR HY CORP BOND UCITS ETF/-1D-/DISTR.",
"valuation": 23643
}
],
"valid": "true"
}Lab Results
Input document:
Query:
{"patient_name": "str", "patient_age": "str", "patient_pid": 0, "lab_results": [{"investigation": "str", "result": 0.00, "reference_value": "str", "unit": "str"}]}Output:
{
"patient_name": "Yash M. Patel",
"patient_age": "21 Years",
"patient_pid": 555,
"lab_results": [
{
"investigation": "Hemoglobin (Hb)",
"result": 12.5,
"reference_value": "13.0 - 17.0",
"unit": "g/dL"
},
{
"investigation": "RBC COUNT",
"result": 5.2,
"reference_value": "4.5 - 5.5",
"unit": "mill/cumm"
},
{
"investigation": "Packed Cell Volume (PCV)",
"result": 57.5,
"reference_value": "40 - 50",
"unit": "%"
},
{
"investigation": "Mean Corpuscular Volume (MCV)",
"result": 87.75,
"reference_value": "83 - 101",
"unit": "fL"
},
{
"investigation": "MCH",
"result": 27.2,
"reference_value": "27 - 32",
"unit": "pg"
},
{
"investigation": "MCHC",
"result": 32.8,
"reference_value": "32.5 - 34.5",
"unit": "g/dL"
},
{
"investigation": "RDW",
"result": 13.6,
"reference_value": "11.6 - 14.0",
"unit": "%"
},
{
"investigation": "WBC COUNT",
"result": 9000,
"reference_value": "4000-11000",
"unit": "cumm"
},
{
"investigation": "Neutrophils",
"result": 60,
"reference_value": "50 - 62",
"unit": "%"
},
{
"investigation": "Lymphocytes",
"result": 31,
"reference_value": "20 - 40",
"unit": "%"
},
{
"investigation": "Eosinophils",
"result": 1,
"reference_value": "00 - 06",
"unit": "%"
},
{
"investigation": "Monocytes",
"result": 7,
"reference_value": "00 - 10",
"unit": "%"
},
{
"investigation": "Basophils",
"result": 1,
"reference_value": "00 - 02",
"unit": "%"
},
{
"investigation": "Absolute Neutrophils",
"result": 6000,
"reference_value": "1500 - 7500",
"unit": "cells/mcL"
},
{
"investigation": "Absolute Lymphocytes",
"result": 3100,
"reference_value": "1300 - 3500",
"unit": "cells/mcL"
},
{
"investigation": "Absolute Eosinophils",
"result": 100,
"reference_value": "00 - 500",
"unit": "cells/mcL"
},
{
"investigation": "Absolute Monocytes",
"result": 700,
"reference_value": "200 - 950",
"unit": "cells/mcL"
},
{
"investigation": "Absolute Basophils",
"result": 100,
"reference_value": "00 - 300",
"unit": "cells/mcL"
},
{
"investigation": "Platelet Count",
"result": 320000,
"reference_value": "150000 - 410000",
"unit": "cumm"
}
],
"valid": "true"
}How to Use Sparrow
Sparrow can be used by passing a JSON query string argument with field names and types to fetch, along with the input document and pipeline.
Arguments
query: JSON query string argument with field names and types to fetchfile-path: input document (image or multipage PDF)pipeline: Sparrow pipeline used to process query requestcrop_size=N: crop N pixels from all borders of the input imagesdebug-dir: folder where processed images are storeddebug: if True, additional messages will be printed
Options
--options mlx: set MLX as backend for local inference--options mlx-community/Qwen2-VL-72B-Instruct-4bit: name for Vision LLM model, supported by MLX--options tables_only: process tables only--options validation_off: disable response validation
Examples
Running locally with Apple MLX backend:
./sparrow.sh "[{"instrument_name":"str", "valuation":0}]" --pipeline "sparrow-parse" --options mlx --options mlx-community/Qwen2-VL-72B-Instruct-4bit --file-path "/data/bonds_table.png"Sparrow Parse pipeline, with GPU backend on Hugging Face:
./sparrow.sh "[{"instrument_name":"str", "valuation":0}]" --pipeline "sparrow-parse" --options huggingface --options katanaml/sparrow-qwen2-vl-7b --file-path "/data/bonds_table.png"Conclusion
Sparrow simplifies document processing by providing a unified API that handles various document types and extraction methods. Its schema-based approach ensures consistent output format regardless of the input document format or the extraction backend used. With Sparrow, you can streamline your document processing pipeline and reduce development overhead.