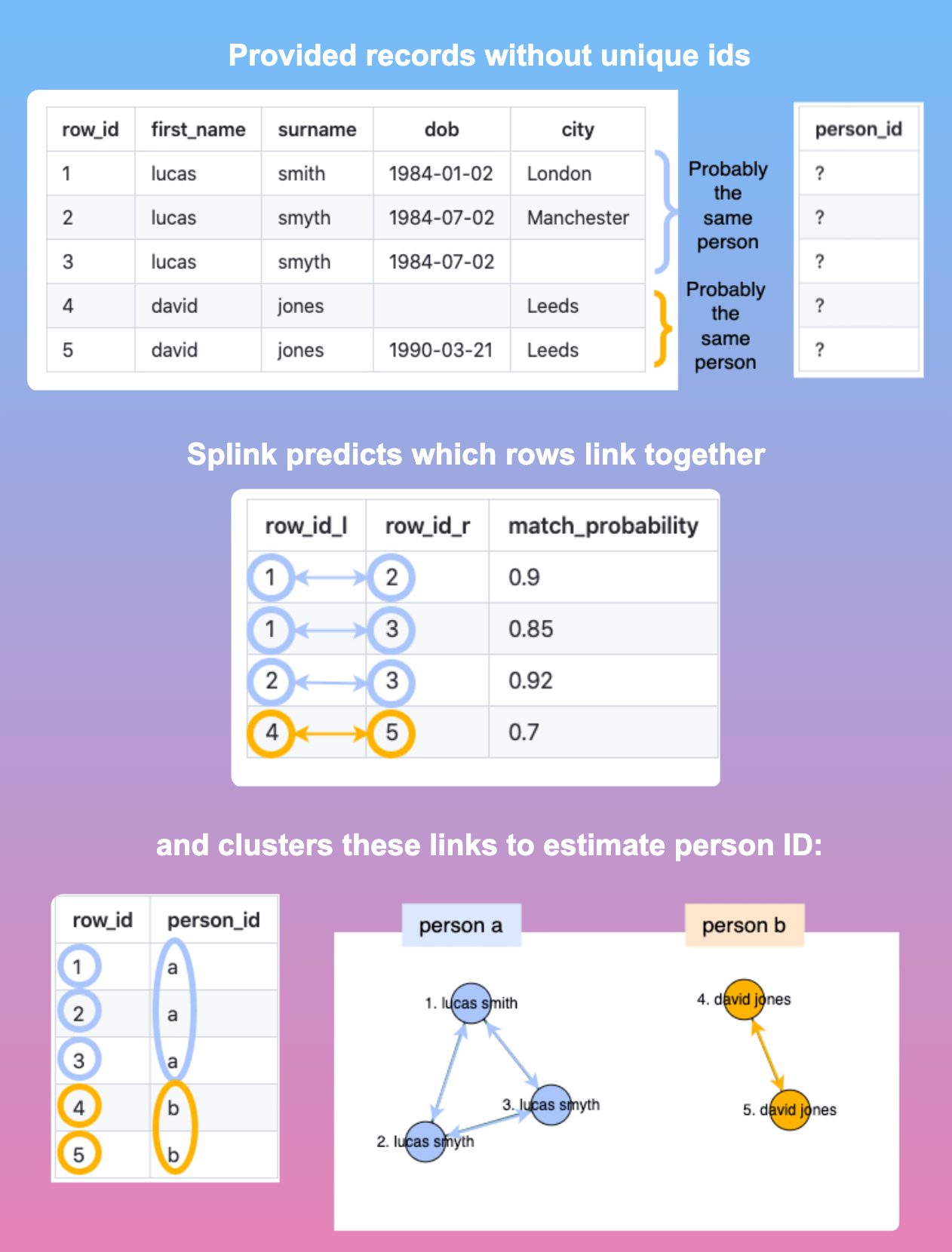

Matching and deduplicating records across multiple datasets without unique identifiers is a time-consuming and error-prone process.
Splink solves this problem with probabilistic record linkage, enabling you to deduplicate and link records quickly and accurately.
Key benefits include:
- Fast processing: Link 1 million records on a laptop in just 1 minute
- High accuracy: Advanced term frequency adjustments and customizable fuzzy matching logic
- Unsupervised learning: No training data required
- Interactive outputs: Explore and diagnose linkage issues with intuitive visualizations
Historical People: Quick and Dirty Record Linkage Example
This example demonstrates how to obtain initial record linkage results as quickly as possible using the Splink library.
Importing Libraries and Loading Data
from splink.datasets import splink_datasets
from splink import block_on, SettingsCreator
import splink.comparison_library as cl
from splink import Linker, DuckDBAPI
# Load the historical 50k dataset
df = splink_datasets.historical_50k
df.head(5)| unique_id | full_name | first_and_surname | first_name | surname | dob | birth_place | postcode_fake | occupation |
|---|---|---|---|---|---|---|---|---|
| Q2296770-1 | thomas clifford, 1st baron clifford of chudleigh | thomas chudleigh | thomas | chudleigh | 1630-08-01 | devon | tq13 8df | politician |
| Q2296770-2 | thomas of chudleigh | thomas chudleigh | thomas | chudleigh | 1630-08-01 | devon | tq13 8df | politician |
| Q2296770-3 | tom 1st baron clifford of chudleigh | tom chudleigh | tom | chudleigh | 1630-08-01 | devon | tq13 8df | politician |
| Q2296770-4 | thomas 1st chudleigh | thomas chudleigh | thomas | chudleigh | 1630-08-01 | devon | tq13 8hu | politician |
| Q2296770-5 | thomas clifford, 1st baron chudleigh | thomas chudleigh | thomas | chudleigh | 1630-08-01 | devon | tq13 8df | politician |
Defining Settings
# Define the settings for the record linkage model
settings = SettingsCreator(
link_type="dedupe_only",
blocking_rules_to_generate_predictions=[
block_on("full_name"),
block_on("substr(full_name,1,6)", "dob", "birth_place"),
block_on("dob", "birth_place"),
block_on("postcode_fake"),
],
comparisons=[
cl.ForenameSurnameComparison(
"first_name",
"surname",
forename_surname_concat_col_name="first_and_surname",
),
cl.DateOfBirthComparison("dob", input_is_string=True),
cl.LevenshteinAtThresholds("postcode_fake", 2),
cl.JaroWinklerAtThresholds("birth_place", 0.9).configure(
term_frequency_adjustments=True
),
cl.ExactMatch("occupation").configure(term_frequency_adjustments=True),
],
)Creating a Linker and Estimating Probabilities
# Create a linker object
linker = Linker(df, settings, db_api=DuckDBAPI(), set_up_basic_logging=False)
# Define deterministic rules
deterministic_rules = [
"l.full_name = r.full_name",
"l.postcode_fake = r.postcode_fake and l.dob = r.dob",
]
# Estimate the probability of two random records matching
linker.training.estimate_probability_two_random_records_match(
deterministic_rules, recall=0.6
)
# Estimate the u probability using random sampling
linker.training.estimate_u_using_random_sampling(max_pairs=2e6)Predicting Matches
# Predict matches with a threshold match probability of 0.9
results = linker.inference.predict(threshold_match_probability=0.9)Displaying Results
# Display the results as a pandas dataframe
results.as_pandas_dataframe(limit=5)This will output the first 5 rows of the results dataframe, which contains information about the matched records, including the match weight, match probability, and the values of the compared columns.


