
Table of Contents
- Introduction
- Text Preprocessing with regex
- difflib: Python’s Built-in Sequence Matching
- RapidFuzz: High-Performance Fuzzy String Matching
- Sentence Transformers: AI-Powered Semantic Similarity
- When to Use Each Tool
- Final Thoughts
Introduction
Text similarity is a fundamental challenge in data science. Whether you’re detecting duplicates, clustering content, or building search systems, the core question remains: how do you determine when different text strings represent the same concept?
Traditional exact matching fails with real-world data. Consider these common text similarity challenges:
- Formatting variations: “iPhone® 14 Pro Max” vs “IPHONE 14 pro max” – identical products with different capitalization and symbols.
- Missing spaces: “iPhone14ProMax” vs “iPhone 14 Pro Max” – same product name, completely different character sequences.
- Extra information: “Apple iPhone 14 Pro Max 256GB” vs “iPhone 14 Pro Max” – additional details that obscure the core product.
- Semantic equivalence: “wireless headphones” vs “bluetooth earbuds” – different words describing similar concepts.
These challenges require different approaches:
- Regex preprocessing cleans formatting inconsistencies
- difflib provides character-level similarity scoring
- RapidFuzz handles fuzzy matching at scale
- Sentence Transformers understands semantic relationships
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.
Key Takeaways
Here’s what you’ll learn:
- Handle 90% of text variations with regex preprocessing and RapidFuzz matching
- Achieve 5× faster fuzzy matching compared to difflib with production-grade algorithms
- Unlock semantic understanding with Sentence Transformers for conceptual similarity
- Navigate decision trees from simple string matching to AI-powered text analysis
- Implement scalable text similarity pipelines for real-world data challenges
Text Preprocessing with regex
Raw text data contains special characters, inconsistent capitalization, and formatting variations. Regular expressions provide the first line of defense by normalizing text.
These pattern-matching tools, accessed through Python’s re module, excel at finding and replacing text patterns like symbols, whitespace, and formatting inconsistencies.
Let’s start with a realistic dataset that demonstrates common text similarity challenges:
import re
# Sample messy text data
messy_products = [
"iPhone® 14 Pro Max",
"IPHONE 14 pro max",
"Apple iPhone 14 Pro Max 256GB",
"iPhone14ProMax",
"i-Phone 14 Pro Max",
"Samsung Galaxy S23 Ultra",
"SAMSUNG Galaxy S23 Ultra 5G",
"Galaxy S23 Ultra (512GB)",
"Samsung S23 Ultra",
"wireless headphones",
"bluetooth earbuds",
"Sony WH-1000XM4 Headphones",
"WH-1000XM4 Wireless Headphones",
]
With our test data established, we can build a comprehensive preprocessing function to handle these variations:
def preprocess_product_name(text):
"""Clean product names for better similarity matching."""
# Convert to lowercase
text = text.lower()
# Remove special characters and symbols
text = re.sub(r"[®™©]", "", text)
text = re.sub(r"[^\w\s-]", " ", text)
# Normalize spaces and hyphens
text = re.sub(r"[-_]+", " ", text)
text = re.sub(r"\s+", " ", text)
# Remove size/capacity info in parentheses
text = re.sub(r"\([^)]*\)", "", text)
return text.strip()
> 📖 **Related**: These regex patterns use traditional syntax for maximum compatibility. For more readable pattern construction, explore [PRegEx for human-friendly regex syntax](https://codecut.ai/pregex-write-human-readable-regular-expressions-in-python-2/).
# Apply preprocessing to sample data
print("Before and after preprocessing:")
print("-" * 50)
for product in messy_products[:8]:
cleaned = preprocess_product_name(product)
print(f"Original: {product}")
print(f"Cleaned: {cleaned}")
print()
Output:
Before and after preprocessing:
--------------------------------------------------
Original: iPhone® 14 Pro Max
Cleaned: iphone 14 pro max
Original: IPHONE 14 pro max
Cleaned: iphone 14 pro max
Original: Apple iPhone 14 Pro Max 256GB
Cleaned: apple iphone 14 pro max 256gb
Original: iPhone14ProMax
Cleaned: iphone14promax
Original: i-Phone 14 Pro Max
Cleaned: i phone 14 pro max
Original: Samsung Galaxy S23 Ultra
Cleaned: samsung galaxy s23 ultra
Original: SAMSUNG Galaxy S23 Ultra 5G
Cleaned: samsung galaxy s23 ultra 5g
Original: Galaxy S23 Ultra (512GB)
Cleaned: galaxy s23 ultra
Perfect matches emerge after cleaning formatting inconsistencies. Products 1 and 2 now match exactly, demonstrating regex’s power for standardization.
However, regex preprocessing fails with critical variations. Let’s test exact matching after preprocessing:
# Test exact matching after regex preprocessing
test_cases = [
("iPhone® 14 Pro Max", "IPHONE 14 pro max", "Case + symbols"),
("iPhone® 14 Pro Max", "Apple iPhone 14 Pro Max 256GB", "Extra words"),
("iPhone® 14 Pro Max", "iPhone14ProMax", "Missing spaces"),
("Apple iPhone 14 Pro Max", "iPhone 14 Pro Max Apple", "Word order"),
("wireless headphones", "bluetooth earbuds", "Semantic gap")
]
# Test each case
for product1, product2, issue_type in test_cases:
cleaned1 = preprocess_product_name(product1)
cleaned2 = preprocess_product_name(product2)
is_match = cleaned1 == cleaned2
result = "✓" if is_match else "✗"
print(f"{result} {issue_type}: {is_match}")
Output:
✓ Case + symbols: True
✗ Extra words: False
✗ Missing spaces: False
✗ Word order: False
✗ Semantic gap: False
Regex achieves only 1/5 exact matches despite preprocessing. Success: case and symbol standardization. Failures:
- Extra words: “apple iphone” vs “iphone” remain different
- Missing spaces: “iphone14promax” vs “iphone 14 pro max” fail matching
- Word reordering: Different arrangements of identical words don’t match
- Semantic gaps: No shared text patterns between conceptually similar products
These limitations require character-level similarity measurement instead of exact matching. Python’s built-in difflib module provides the solution by analyzing character sequences and calculating similarity ratios.
difflib: Python’s Built-in Sequence Matching
difflib is a Python built-in module that provides similarity ratios. It analyzes character sequences to calculate similarity scores between text strings.
from difflib import SequenceMatcher
def calculate_similarity(text1, text2):
"""Calculate similarity ratio between two strings."""
return SequenceMatcher(None, text1, text2).ratio()
# Test difflib on key similarity challenges
test_cases = [
("iphone 14 pro max", "iphone 14 pro max", "Exact match"),
("iphone 14 pro max", "i phone 14 pro max", "Spacing variation"),
("iphone 14 pro max", "apple iphone 14 pro max 256gb", "Extra words"),
("iphone 14 pro max", "iphone14promax", "Missing spaces"),
("iphone 14 pro max", "iphone 14 prro max", "Typo"),
("apple iphone 14 pro max", "iphone 14 pro max apple", "Word order"),
("wireless headphones", "bluetooth earbuds", "Semantic gap")
]
for text1, text2, test_type in test_cases:
score = calculate_similarity(text1, text2)
result = "✓" if score >= 0.85 else "✗"
print(f"{result} {test_type}: {score:.3f}")
Output:
✓ Exact match: 1.000
✓ Spacing variation: 0.971
✗ Extra words: 0.739
✓ Missing spaces: 0.903
✓ Typo: 0.971
✗ Word order: 0.739
✗ Semantic gap: 0.333
difflib achieves 4/7 successful matches (≥0.85 threshold). Successes: exact matches, spacing variations, typos, and missing spaces. Failures:
- Word reordering: “Apple iPhone” vs “iPhone Apple” drops to 0.739
- Extra content: Additional words reduce scores to 0.739
- Semantic gaps: Different words for same concept score only 0.333
These results highlight difflib’s core limitation: sensitivity to word order and poor handling of extra content. RapidFuzz tackles word reordering and extra content issues with sophisticated matching algorithms that understand token relationships beyond simple character comparison.
RapidFuzz: High-Performance Fuzzy String Matching
RapidFuzz is a high-performance fuzzy string matching library with C++ optimization. It addresses word reordering and complex text variations that difflib cannot handle effectively.
To install RapidFuzz, run:
pip install rapidfuzz
Let’s test RapidFuzz on the same test cases:
from rapidfuzz import fuzz
# Test RapidFuzz using WRatio algorithm
test_cases = [
("iphone 14 pro max", "iphone 14 pro max", "Exact match"),
("iphone 14 pro max", "i phone 14 pro max", "Spacing variation"),
("iphone 14 pro max", "apple iphone 14 pro max 256gb", "Extra words"),
("iphone 14 pro max", "iphone14promax", "Missing spaces"),
("iphone 14 pro max", "iphone 14 prro max", "Typo"),
("apple iphone 14 pro max", "iphone 14 pro max apple", "Word order"),
("wireless headphones", "bluetooth earbuds", "Semantic gap"),
("macbook pro", "laptop computer", "Conceptual gap")
]
for text1, text2, test_type in test_cases:
score = fuzz.WRatio(text1, text2) / 100 # Convert to 0-1 scale
result = "✓" if score >= 0.85 else "✗"
print(f"{result} {test_type}: {score:.3f}")
Output:
✓ Exact match: 1.000
✓ Spacing variation: 0.971
✓ Extra words: 0.900
✓ Missing spaces: 0.903
✓ Typo: 0.971
✓ Word order: 0.950
✗ Semantic gap: 0.389
✗ Conceptual gap: 0.385
RapidFuzz achieves 6/8 successful matches (≥0.85 threshold). Successes: exact matches, spacing, extra words, missing spaces, typos, and word order. Failures:
- Semantic gaps: “wireless headphones” vs “bluetooth earbuds” scores only 0.389
- Conceptual relationships: “macbook pro” vs “laptop computer” achieves just 0.385
- Pattern-only matching: Cannot understand that different words describe same products
These failures reveal RapidFuzz’s fundamental limitation: it excels at text-level variations but cannot understand meaning. When products serve identical purposes using different terminology, we need semantic understanding rather than pattern matching.
Sentence Transformers addresses this gap through neural language models that comprehend conceptual relationships.
Sentence Transformers: AI-Powered Semantic Similarity
Surface-level text matching misses semantic relationships. Sentence Transformers, a library built on transformer neural networks, can understand that “wireless headphones” and “bluetooth earbuds” serve identical purposes by analyzing meaning rather than just character patterns.
To install Sentence Transformers, run:
pip install sentence-transformers
Let’s test Sentence Transformers on the same test cases:
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
# Test semantic understanding capabilities
model = SentenceTransformer('all-MiniLM-L6-v2')
test_cases = [
("iphone 14 pro max", "iphone 14 pro max", "Exact match"),
("iphone 14 pro max", "i phone 14 pro max", "Spacing variation"),
("iphone 14 pro max", "apple iphone 14 pro max 256gb", "Extra words"),
("apple iphone 14 pro max", "iphone 14 pro max apple", "Word order"),
("wireless headphones", "bluetooth earbuds", "Semantic match"),
("macbook pro", "laptop computer", "Conceptual match"),
("gaming console", "video game system", "Synonym match"),
("smartphone", "feature phone", "Related concepts")
]
for text1, text2, test_type in test_cases:
embeddings = model.encode([text1, text2])
score = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]
result = "✓" if score >= 0.65 else "✗"
print(f"{result} {test_type}: {score:.3f}")
Output:
✓ Exact match: 1.000
✓ Spacing variation: 0.867
✓ Extra words: 0.818
✓ Word order: 0.988
✗ Semantic match: 0.618
✓ Conceptual match: 0.652
✓ Synonym match: 0.651
✗ Related concepts: 0.600
Sentence Transformers achieves 7/8 successful matches (≥0.65 threshold). Successes: all text variations plus semantic relationships. Failures:
- Edge case semantics: “smartphone” vs “feature phone” scores only 0.600
- Processing overhead: Neural inference requires significantly more computation than string algorithms
- Memory requirements: Models need substantial RAM (100MB+ for basic models, GBs for advanced ones)
- Resource scaling: Large datasets may require GPU acceleration for reasonable performance
Sentence Transformers unlocks semantic understanding at computational cost. The decision depends on whether conceptual relationships provide sufficient business value to justify resource overhead.
For implementing semantic search at production scale, see our pgvector and Ollama integration guide.
When to Use Each Tool
Data Preprocessing (Always Start Here)
Use regex for:
- Removing special characters and symbols
- Standardizing case and formatting
- Cleaning messy product names
- Preparing text for similarity analysis
Character-Level Similarity
Use difflib when:
- Learning text similarity concepts
- Working with small datasets (<1000 records)
- External dependencies not allowed
- Simple typo detection is sufficient
Production Fuzzy Matching
Use RapidFuzz when:
- Processing thousands of records
- Need fast approximate matching
- Handling abbreviations and variations
- Text-level similarity is sufficient
Semantic Understanding
Use Sentence Transformers when:
- Conceptual relationships matter
- “wireless headphones” should match “bluetooth earbuds”
- Building recommendation systems
- Multilingual content similarity
- Compute resources are available
Performance vs Accuracy Tradeoff
| Requirement | Recommended Tool |
|---|---|
| Speed > Accuracy | RapidFuzz |
| Accuracy > Speed | Sentence Transformers |
| No Dependencies | difflib |
| Preprocessing Only | regex |
Decision Tree
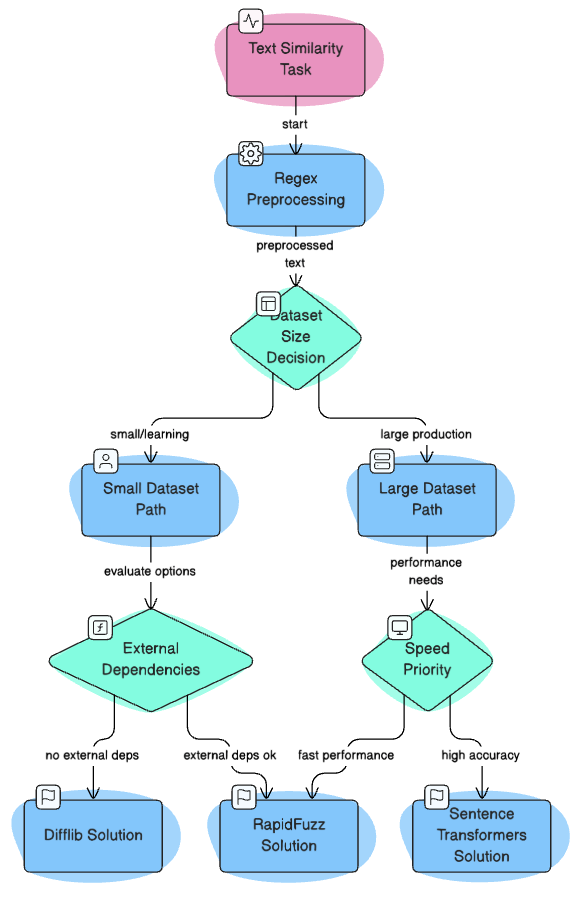
When facing a new text similarity project, use this visual guide to navigate from problem requirements to the optimal tool selection:
Final Thoughts
When facing complex challenges, start with the most basic solution first, identify where it fails through testing, then strategically upgrade the failing component. This article demonstrates exactly this progression – from simple regex preprocessing to sophisticated semantic understanding.
Build complexity incrementally based on real limitations, not anticipated ones.
📚 For comprehensive production-ready data science practices, check out Production-Ready Data Science.
📚 Want to go deeper? Learning new techniques is the easy part. Knowing how to structure, test, and deploy them is what separates side projects from real work. My book shows you how to build data science projects that actually make it to production. Get the book →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.



2 thoughts on “4 Text Similarity Tools: When Regex Isn’t Enough”
Very nice article with practical implementation.
Thank you !!
Thank you!