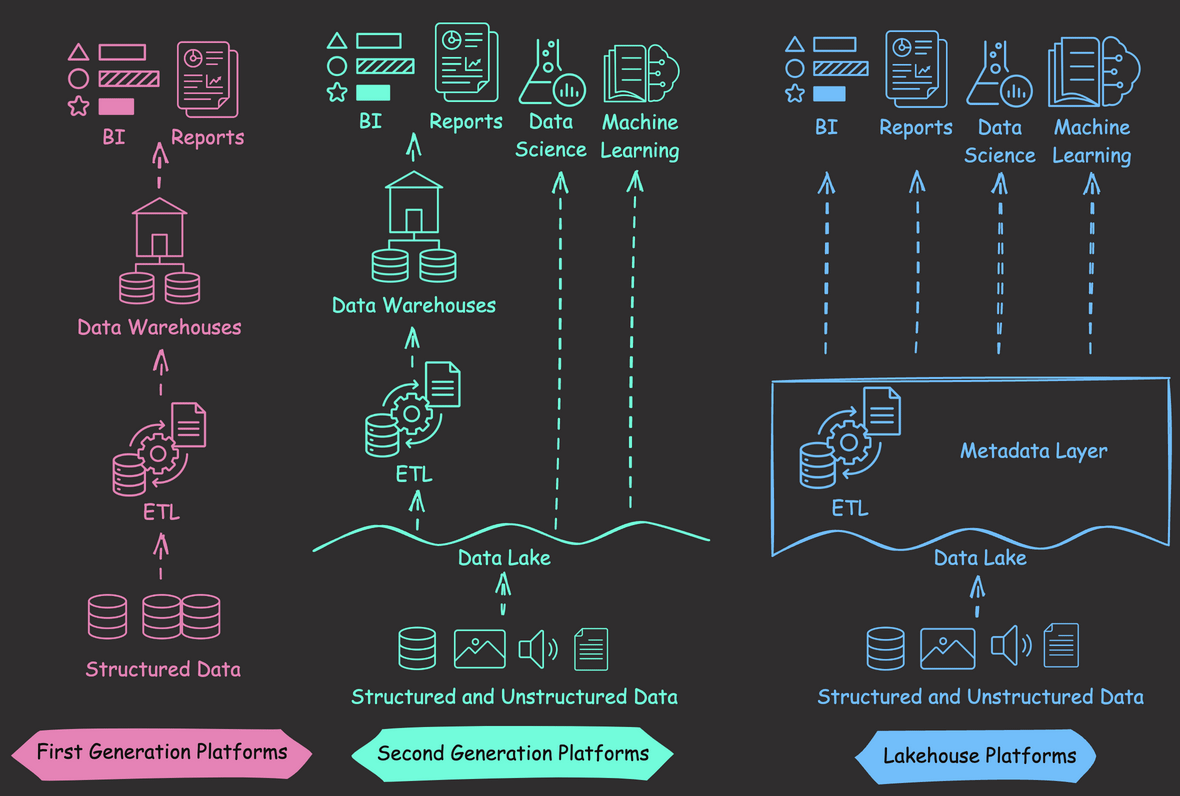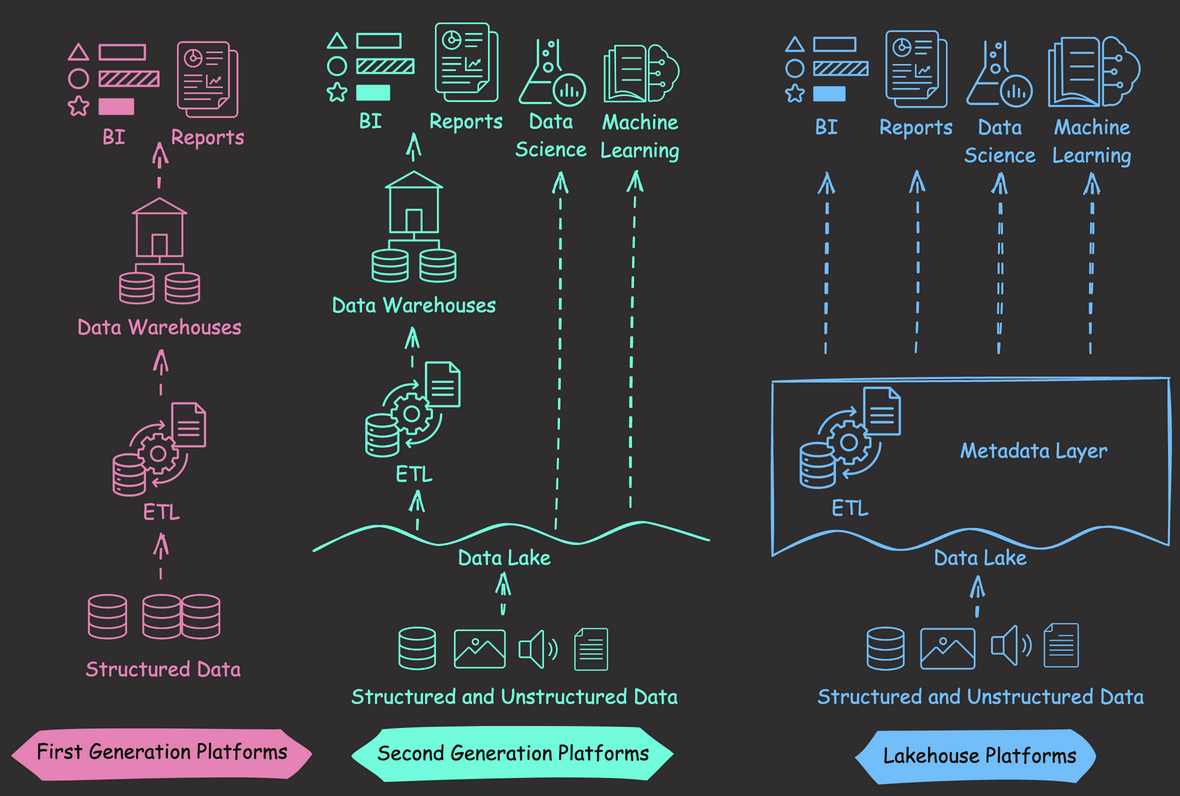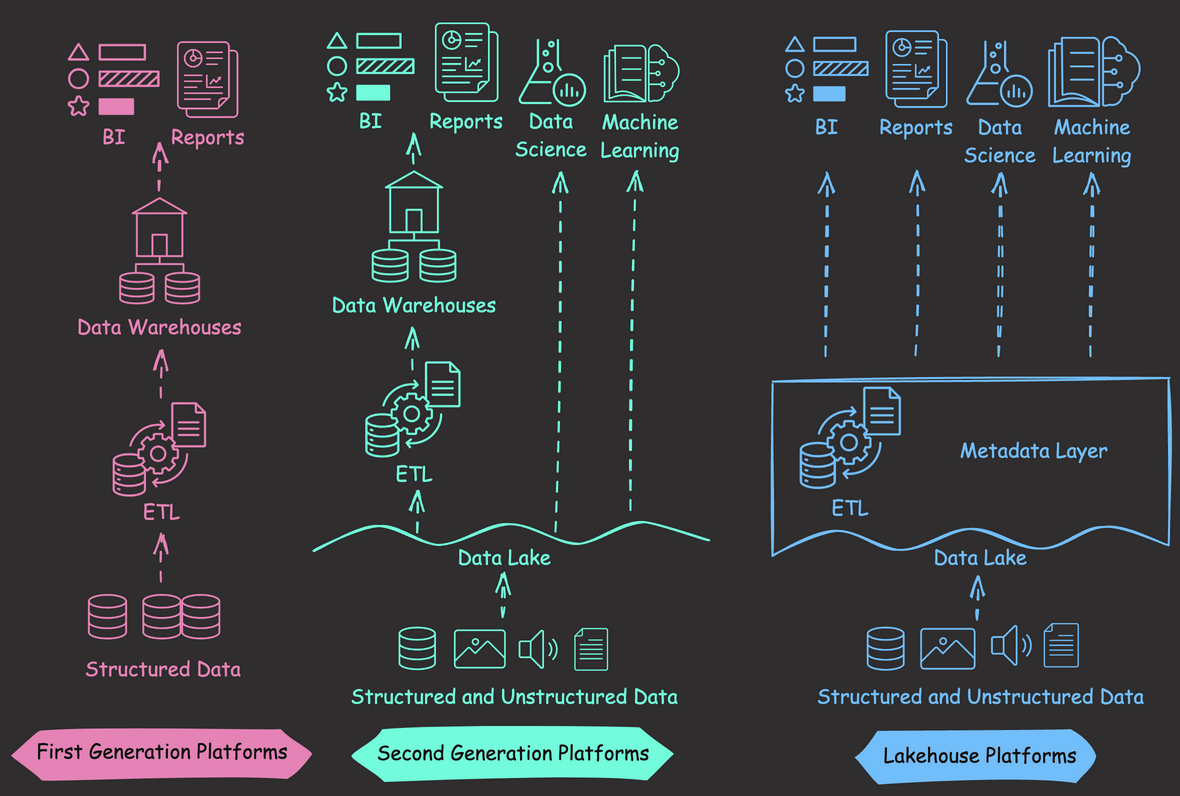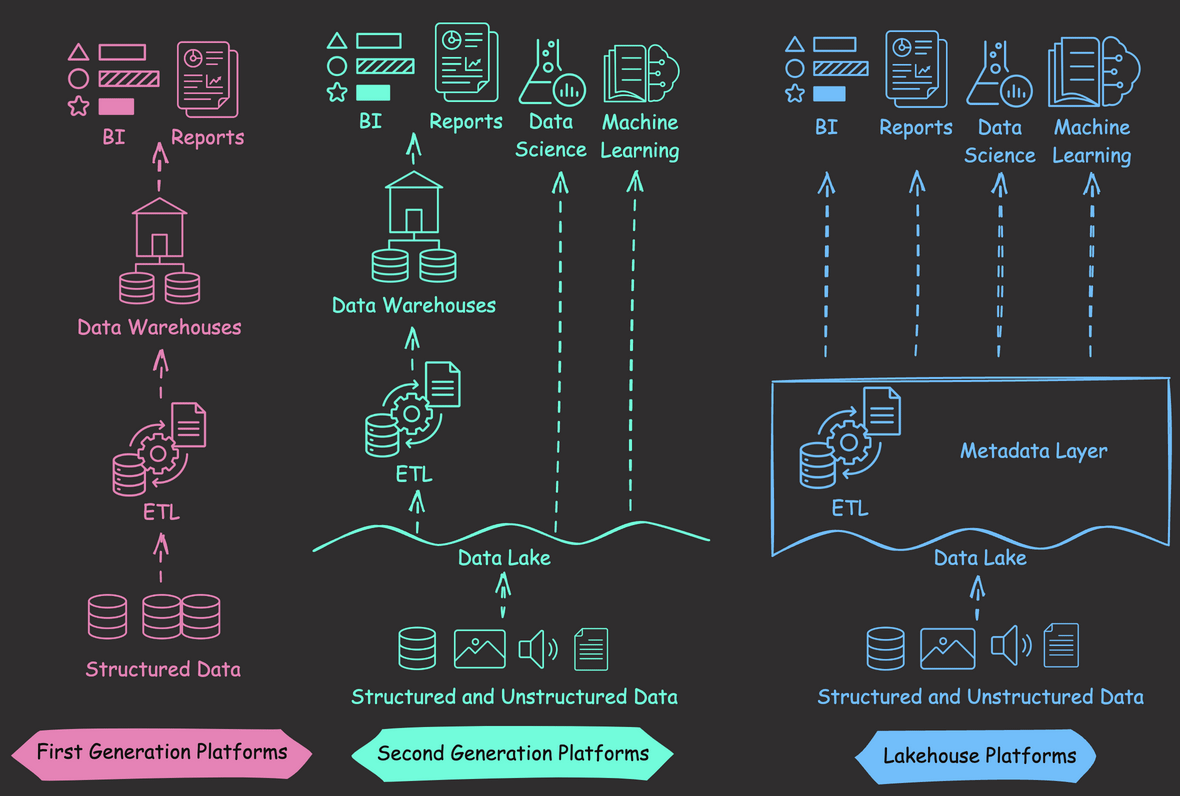

First-generation data warehouses excelled with structured data and BI tasks but had limited support for unstructured data and were costly to scale up.
Second-generation data lakes offered scalable storage for diverse data but lacked key management features, such as ACID transactions and data versioning.
Databricks’ Lakehouse architecture combines the strengths of lakes and warehouses, including:
- Supporting various data types, suitable for data science and machine learning.
- Enhancing management features such as ACID transactions and data versioning.
- Using cost-effective object storage, like Amazon S3, with formats like Parquet.
- Maintaining data integrity via a metadata layer.


